Résumé de la publication
Grâce à cet article vous allez comprendre comment Docker et Kubernetes vous aident à exécuter, faire évoluer, surveiller et mettre à jour vos applications sur site et dans le cloud. L’article montre des techniques pour rendre vos applications hautement disponibles, élastiques, sécurisées et résistantes aux pannes
Objectifs de la publication
- Empaquetez et exécutez des applications monolithiques existantes ou de nouvelles applications basées sur des microservices dans des conteneurs
- Créez et expédiez vos propres images de conteneurs
- Utilisez Kubernetes pour orchestrer des applications multi-conteneurs complexes sur site ou dans le cloud
- Exécuter, mettre à l’échelle, surveiller et mettre à jour les services d’application
- Provisionner, faire évoluer et mettre à jour des clusters Kubernetes entièrement hébergés sur Microsoft Azure
- Sécurisez vos applications conteneurisées à l’aide des bonnes pratiques Docker et Kubernetes
Introduction
Préambule
La conteneurisation est considérée comme le meilleur moyen d’implémenter DevOps et l’objectif principal de cet article est de fournir des solutions de déploiement de bout en bout pour votre environnement Azure.
Cet article commencera par la mise en œuvre du déploiement et de la gestion des conteneurs ainsi que par la mise en route avec Docker et Kubernetes. Ensuite, cet article expliquera les opérations de gestion et d’orchestration des conteneurs dans Docker à l’aide des solutions cloud d’Azure. Vous apprendrez également à déployer et à gérer des applications hautement évolutives ainsi qu’à configurer un cluster Kubernetes prêt pour la production sur Azure dans un environnement intact. Enfin, l’article vous aidera également à tirer parti des outils Docker et Kubernetes de Microsoft pour créer des applications pouvant être rapidement déployées sur Azure.
À la fin de l’article, vous découvrirez des sujets plus avancés pour approfondir vos connaissances sur Docker et Kubernetes.
Contenu de cet article
- Chapitre 1, Que sont les conteneurs et pourquoi devrais-je les utiliser ? ce chapitre se concentre sur la chaîne d’approvisionnement des logiciels et les frictions qu’elle comporte. Il présente ensuite les conteneurs comme un moyen de réduire ce frottement et d’ajouter une sécurité de niveau entreprise par-dessus. Dans ce chapitre, nous examinons également comment les conteneurs et l’écosystème qui les entoure sont assemblés. Nous soulignons spécifiquement la distinction entre les composants OSS en amont (Moby) qui forment les blocs de construction des produits en aval de Docker et d’autres fournisseurs.
- Le chapitre 2, Configuration d’un environnement de travail, dans ce chapitre, explique en détail comment configurer un environnement idéal pour les développeurs, les DevOps et les opérateurs qui peut être utilisé lorsque vous travaillez avec des conteneurs Docker.
- Chapitre 3, Utilisation des conteneurs, ce chapitre explique comment démarrer, arrêter et supprimer des conteneurs. Le chapitre explique également comment inspecter des conteneurs pour en extraire des métadonnées supplémentaires. En outre, il explique comment exécuter des processus supplémentaires ou comment les attacher au processus principal dans un conteneur déjà en cours d’exécution. Il montre également comment récupérer des informations de journalisation à partir d’un conteneur qui sont produites par les processus en cours d’exécution à l’intérieur. Enfin, le chapitre présente le fonctionnement interne d’un conteneur, notamment des espaces de noms Linux et des groupes de contrôle.
- Chapitre 4, Création et gestion d’images de conteneurs, ce chapitre présente les différentes façons de créer des images de conteneurs qui servent de modèles pour les conteneurs. Il présente la structure interne d’une image et comment elle est construite.
- Chapitre 5, Volumes de données et gestion du système, ce chapitre présente les volumes de données qui peuvent être utilisés par des composants avec état s’exécutant dans des conteneurs. Le chapitre présente également les commandes de niveau système qui sont utilisées pour recueillir des informations sur Docker et le système d’exploitation sous-jacent, ainsi que des commandes pour nettoyer le système des ressources orphelines. Enfin, il présente les événements système générés par le moteur Docker.
- Chapitre 6, Architecture d’application distribuée, ce chapitre présente le concept d’une architecture d’application distribuée et présente les différents modèles et meilleures pratiques nécessaires pour exécuter une application distribuée avec succès. Enfin, il examine les exigences supplémentaires qui doivent être remplies pour exécuter une telle application en production.
- Chapitre 7, Mise en réseau à hôte unique, ce chapitre présente le modèle de mise en réseau de conteneurs Docker et son implémentation à hôte unique sous la forme d’un réseau en pont. Le chapitre présente le concept de réseaux définis par logiciel et comment ils sont utilisés pour sécuriser les applications conteneurisées. Enfin, il présente comment les ports à conteneurs peuvent être ouverts au public et rendre ainsi les composants conteneurisés accessibles depuis le monde extérieur.
- Chapitre 8, Docker Compose, ce chapitre présente le concept d’une application composée de plusieurs services s’exécutant chacun dans un conteneur et comment Docker Compose nous permet de créer, d’exécuter et de mettre à l’échelle facilement une telle application en utilisant une approche déclarative.
- Chapitre 9, Orchestrateurs, ce chapitre présente le concept d’orchestrateurs. Il explique pourquoi les orchestrateurs sont nécessaires et comment ils fonctionnent conceptuellement. Le chapitre fournira également un aperçu des orchestrateurs les plus populaires et nommera quelques-uns de leurs avantages et inconvénients.
- Chapitre 10, Orchestration des applications conteneurisées avec Kubernetes , ce chapitre présente Kubernetes. Kubernetes est actuellement le leader incontesté de l’espace d’orchestration de conteneurs. Il commence par une présentation de haut niveau de l’architecture d’un cluster Kubernetes, puis examine les principaux objets utilisés dans Kubernetes pour définir et exécuter des applications conteneurisées.
- Chapitre 11, Déploiement, mise à jour et sécurisation d’une application avec Kubernetes , ce chapitre explique comment déployer, mettre à jour et faire évoluer des applications dans un cluster Kubernetes. Il explique également comment les déploiements sans temps d’arrêt sont atteints pour permettre des mises à jour et des annulations sans interruption des applications critiques. Ce chapitre présente également les secrets de Kubernetes comme moyen de configurer les services avec et de protéger les données sensibles.
- Chapitre 12, Exécution d’une application conteneurisée dans le cloud, ce chapitre montre comment déployer une application conteneurisée complexe dans un cluster Kubernetes hébergé sur Microsoft Azure à l’aide de l’offre Azure Kubernetes Service (AKS). Premièrement, il explique comment approvisionner un cluster Kubernetes, deuxièmement, il montre comment héberger les images Docker dans Azure Container Registry et enfin, il montre comment déployer, exécuter, surveiller, mettre à l’échelle et mettre à niveau l’application. Le chapitre montre également comment mettre à niveau la version de Kubernetes dans le cluster sans provoquer de temps d’arrêt.
Que sont les conteneurs et pourquoi devrais-je les utiliser?
Le premier chapitre de cet article vous fera découvrir le monde des conteneurs et leur orchestration. Cet article suppose que vous n’avez aucune connaissance préalable dans le domaine des conteneurs et vous donnera une introduction très pratique sur le sujet.
Dans ce chapitre, nous nous concentrons sur la chaîne d’approvisionnement des logiciels et les frictions à l’intérieur. Nous présentons ensuite les conteneurs comme un moyen de réduire ce frottement et d’ajouter une sécurité de niveau entreprise par-dessus. Dans ce chapitre, nous examinons également comment les conteneurs et l’écosystème qui les entoure sont assemblés. Nous soulignons en particulier la distinction entre les composants OSS (Operations Support System) en amont, réunis sous le nom de code Moby, qui forment les blocs de construction des produits en aval de Docker et d’autres fournisseurs.
Le chapitre couvre les sujets suivants :
- Que sont les conteneurs ?
- Pourquoi les conteneurs sont-ils importants ?
- Quel est l’avantage pour moi ou pour mon entreprise ?
- Le projet Moby
- Produits Docker
- L’écosystème des conteneurs
- Architecture de conteneur
Après avoir terminé ce module, vous pourrez :
- Expliquez en quelques phrases simples à un profane intéressé ce que sont les conteneurs, en utilisant une analogie comme les conteneurs physiques
- Justifiez à un profane intéressé pourquoi les conteneurs sont si importants, en utilisant une analogie telle que les conteneurs physiques par rapport à l’expédition traditionnelle, ou les maisons d’appartements par rapport aux maisons unifamiliales, etc.
- Nommez au moins quatre composants open source en amont utilisés par les produits Docker, tels que Docker pour Mac / Windows
- Identifier au moins trois produits Docker
Exigences techniques
Ce chapitre est une introduction théorique au sujet. Par conséquent, il n’y a pas d’exigences techniques particulières pour ce chapitre.
Que sont les conteneurs ?
Un conteneur de logiciel est une chose assez abstraite et cela pourrait donc aider si nous commençons par une analogie qui devrait être assez familière à la plupart des lecteurs. L’analogie est un conteneur d’expédition dans l’industrie du transport.
Nous transportons d’énormes quantités de marchandises dans des trains, des navires et des camions. Nous les déchargeons à des emplacements cibles, ce qui peut être un autre moyen de transport. Les marchandises sont souvent diverses et complexes à manipuler. Avant l’invention des conteneurs d’expédition, ce déchargement d’un moyen de transport et son chargement dans un autre était un processus vraiment complexe et fastidieux. Prenons, par exemple, un agriculteur apportant une charrette pleine de pommes à une gare centrale où les pommes sont ensuite chargées dans un train, avec toutes les pommes de nombreux autres agriculteurs. Ou pensez à un vigneron apportant ses tonneaux de vin avec un camion au port où ils sont déchargés, puis transférés sur un navire qui transportera les tonneaux à l’étranger. Chaque type de produit était conditionné à sa manière et devait donc être traité à sa manière. Toute marchandise en vrac risquait d’être volée ou endommagée au cours du processus. Puis vint le conteneur qui révolutionna totalement l’industrie du transport.
Le conteneur est juste une boîte métallique aux dimensions standardisées. La longueur, la largeur et la hauteur de chaque conteneur sont identiques. C’est un point très important. Sans l’accord du monde sur une taille standard, les conteneurs d’expédition n’auraient pas connu un tel succès. De nos jours, les entreprises qui souhaitent faire transporter leurs marchandises de A à B emballent ces marchandises dans ces conteneurs standardisés. Ensuite, ils appellent un expéditeur qui vient avec un moyen de transport standardisé. Il peut s’agir d’un camion conçu pour charger un conteneur ou d’un train dont les wagons peuvent chacun transporter un ou plusieurs conteneurs. Enfin, nous avons des navires spécialisés dans le transport d’énormes quantités de conteneurs. Les expéditeurs n’ont jamais besoin de déballer et de reconditionner les marchandises. Pour un expéditeur, un conteneur est simplement une boîte noire ; ils ne sont pas intéressés par ce qu’il contient et ne devraient pas s’en soucier dans la plupart des cas. Ce n’est qu’une grosse boîte en fer aux dimensions standard. L’emballage des marchandises dans des conteneurs est désormais entièrement délégué aux parties qui souhaitent que leurs marchandises soient expédiées, et elles devraient savoir comment les manipuler et les emballer. Étant donné que tous les conteneurs ont la même forme et les mêmes dimensions normalisées, les expéditeurs peuvent utiliser des outils standardisés pour manipuler les conteneurs, c’est-à-dire des grues qui déchargent des conteneurs, par exemple d’un train ou d’un camion, et les chargent sur un navire ou vice versa. Un seul type de grue suffit pour gérer tous les conteneurs qui se présentent avec le temps. De plus, les moyens de transport peuvent être normalisés, comme les porte-conteneurs, les camions et les trains. En raison de toute cette standardisation, tous les processus dans et autour de l’expédition des marchandises ont pu être standardisés, et ainsi rendus beaucoup plus efficaces qu’ils ne l’étaient avant l’ère des conteneurs.
Je pense que vous devriez maintenant bien comprendre pourquoi les conteneurs d’expédition sont si importants et pourquoi ils ont révolutionné toute l’industrie du transport. J’ai choisi cette analogie parce que les conteneurs logiciels que nous allons examiner ici remplissent exactement le même rôle dans la chaîne d’approvisionnement des logiciels que les conteneurs d’expédition dans la chaîne d’approvisionnement des biens physiques.
Voyons ce que les développeurs faisaient avant de développer une nouvelle application. Une fois une application terminée aux yeux des développeurs, ils remettraient cette application aux ingénieurs d’exploitation qui devaient ensuite l’installer sur les serveurs de production et la faire fonctionner. Si les ingénieurs d’exploitation ont eu de la chance, ils ont même obtenu un document précis avec des instructions d’installation des développeurs. Jusqu’ici tout va bien, et la vie était facile. Mais les choses sont devenues un peu incontrôlables quand il y avait de nombreuses équipes de développeurs dans une entreprise qui créaient des types d’applications très différents, mais tous devaient être installés sur les mêmes serveurs de production et continuer à y fonctionner. Habituellement, chaque application a des dépendances externes telles que le framework sur lequel elle a été construite ou les bibliothèques qu’elle utilise, etc.
Parfois, deux applications utilisent le même framework mais dans des versions différentes qui peuvent être compatibles ou non entre elles. La vie de notre ingénieur d’exploitation est devenue beaucoup plus difficile au fil du temps. Ils devaient être vraiment créatifs avec la façon dont ils pouvaient charger leurs serveurs, ou leur « vaisseau », avec différentes applications sans casser quelque chose. L’installation d’une nouvelle version d’une certaine application était un projet complexe en soi et nécessitait souvent des mois de planification et de test. En d’autres termes, il y avait beaucoup de friction dans la chaîne d’approvisionnement des logiciels. Mais de nos jours, les entreprises s’appuient de plus en plus sur les logiciels et les cycles de sortie deviennent de plus en plus courts. Nous ne pouvons plus nous permettre d’avoir une nouvelle version peut-être deux fois par an. Les applications doivent être mises à jour en quelques semaines ou jours, voire parfois plusieurs fois par jour. Les entreprises qui ne se conforment pas risquent de fermer leurs portes en raison du manque d’agilité. Alors, quelle est la solution ?
Une première approche a été d’utiliser des machines virtuelles (VM). Au lieu d’exécuter plusieurs applications sur le même serveur, les entreprises emballent et exécutent une seule application par machine virtuelle. Avec lui, les problèmes de compatibilité avaient disparu et la vie semblait à nouveau bonne. Malheureusement, le bonheur n’a pas duré longtemps. Les machines virtuelles sont des bêtes assez lourdes en soi, car elles contiennent toutes un système d’exploitation complet tel que Linux ou Windows Server et tout cela pour une seule application. C’est comme si, dans l’industrie des transports, vous utilisiez un gigantesque navire uniquement pour transporter un camion chargé de bananes. Quel gâchis. Cela ne peut jamais être rentable. La solution ultime au problème était de fournir quelque chose de beaucoup plus léger que les machines virtuelles, mais également capable d’encapsuler parfaitement les marchandises dont il avait besoin pour transporter. Ici, les produits sont l’application réelle écrite par nos développeurs plus (et c’est important) toutes les dépendances externes de l’application, telles que le framework, les bibliothèques, les configurations, etc. Ce Saint Graal d’un mécanisme d’emballage logiciel était le conteneur Docker.
Les développeurs utilisent des conteneurs Docker pour empaqueter leurs applications, leurs frameworks et leurs bibliothèques, puis ils expédient ces conteneurs aux testeurs ou aux ingénieurs d’exploitation. Pour les testeurs et les ingénieurs d’exploitation, le conteneur n’est qu’une boîte noire. Surtout, il s’agit d’une boîte noire normalisée. Tous les conteneurs, quelle que soit l’application exécutée à l’intérieur, peuvent être traités de la même manière. Les ingénieurs savent que si un conteneur s’exécute sur leurs serveurs, tous les autres conteneurs doivent également fonctionner. Et cela est vrai, à part quelques cas marginaux qui existent toujours. Ainsi, les conteneurs Docker sont un moyen de conditionner les applications et leurs dépendances de manière standardisée. Docker a ensuite inventé l’expression « Construire, expédier et exécuter n’importe où ».
Pourquoi les conteneurs sont-ils importants ?
De nos jours, le temps entre les nouvelles versions d’une application devient de plus en plus court, mais le logiciel lui-même ne devient pas plus simple. Au contraire, les projets logiciels augmentent en complexité. Ainsi, nous avons besoin d’un moyen d’apprivoiser la bête et de simplifier la chaîne logistique des logiciels.
Amélioration de la sécurité
Nous entendons également chaque jour combien de cybercrimes sont en augmentation. De nombreuses entreprises bien connues sont affectées par des failles de sécurité. Les données clients très sensibles sont volées, telles que les numéros de sécurité sociale, les informations de carte de crédit, etc. Mais non seulement les données clients sont compromises, mais des secrets d’entreprise sensibles sont également volés.
Les conteneurs peuvent aider de plusieurs façons. Tout d’abord, Gartner a découvert dans un récent rapport que les applications s’exécutant dans un conteneur sont plus sécurisées que leurs homologues ne s’exécutant pas dans un conteneur. Les conteneurs utilisent des primitives de sécurité Linux telles que les espaces de noms du noyau Linux pour mettre en sandbox différentes applications s’exécutant sur les mêmes ordinateurs et groupes de contrôle (cgroups), pour éviter le problème de voisin bruyant lorsqu’une mauvaise application utilise toutes les ressources disponibles d’un serveur et affame toutes les autres applications.
Étant donné que les images de conteneurs sont immuables, il est facile de les analyser pour détecter les vulnérabilités et les expositions connues et, ce faisant, augmenter la sécurité globale de nos applications.
Une autre façon de sécuriser davantage notre chaîne logistique de logiciels lors de l’utilisation de conteneurs est d’utiliser la confiance dans le contenu. La confiance dans le contenu garantit essentiellement que l’auteur d’une image de conteneur est bien celui qu’il prétend être et que le consommateur de l’image de conteneur à la garantie que l’image n’a pas été falsifiée en transit. Ce dernier est connu comme une attaque d’homme au milieu (MITM).
Tout ce que je viens de dire est bien sûr techniquement également possible sans utiliser de conteneurs, mais comme les conteneurs introduisent une norme mondialement acceptée, il est tellement plus facile de mettre en œuvre ces meilleures pratiques et de les appliquer.
D’accord, mais la sécurité n’est pas la seule raison pour laquelle les conteneurs sont importants. Il existe d’autres raisons, comme expliqué dans les deux sections suivantes.
Simuler des environnements de type production
L’un d’eux est le fait que les conteneurs permettent de simuler facilement un environnement de production, même sur l’ordinateur portable d’un développeur. Si nous pouvons conteneuriser n’importe quelle application, nous pouvons également conteneuriser, disons, une base de données telle qu’Oracle ou MS SQL Server. Désormais, tous ceux qui ont déjà dû installer une base de données Oracle sur un ordinateur savent que ce n’est pas la chose la plus simple à faire et que cela prend beaucoup de place sur votre ordinateur. Vous ne voudriez pas faire cela à votre ordinateur portable de développement juste pour tester si l’application que vous avez développée fonctionne vraiment de bout en bout. Avec les conteneurs à portée de main, je peux exécuter une base de données relationnelle complète dans un conteneur aussi facilement que dire 1, 2, 3. Et lorsque j’ai terminé les tests, je peux simplement arrêter et supprimer le conteneur et la base de données disparaît sans laissant une trace sur mon ordinateur.
Étant donné que les conteneurs sont très légers par rapport aux machines virtuelles, il n’est pas rare que de nombreux conteneurs s’exécutent en même temps sur l’ordinateur portable d’un développeur sans surcharger l’ordinateur portable.
Normaliser l’infrastructure
Une troisième raison pour laquelle les conteneurs sont importants est que les opérateurs peuvent enfin se concentrer sur ce qu’ils font vraiment bien, approvisionner l’infrastructure, et exécuter et surveiller les applications en production. Lorsque les applications qu’ils doivent exécuter sur un système de production sont toutes conteneurisées, les opérateurs peuvent commencer à standardiser leur infrastructure. Chaque serveur devient juste un autre hôte Docker. Aucune bibliothèque spéciale de frameworks ne doit être installée sur ces serveurs, juste un OS et un runtime de conteneur tel que Docker.
De plus, les opérateurs ne doivent plus avoir de connaissances intimes sur les composants internes des applications, car ces applications fonctionnent de manière autonome dans des conteneurs qui devraient ressembler à des boîtes noires pour les ingénieurs d’exploitation, de la même manière que les conteneurs d’expédition ressemblent au personnel dans l’industrie du transport.
Quel est l’avantage pour moi ou pour mon entreprise ?
Quelqu’un a dit qu’aujourd’hui, chaque entreprise d’une certaine taille doit reconnaître qu’elle doit être une entreprise de logiciels. Le logiciel gère toutes les entreprises, point final. Comme chaque entreprise devient une entreprise de logiciels, il est nécessaire d’établir une chaîne d’approvisionnement de logiciels. Pour que l’entreprise reste compétitive, sa chaîne d’approvisionnement de logiciels doit être sécurisée et efficace. L’efficacité peut être obtenue grâce à une automatisation et une normalisation approfondie. Mais dans les trois domaines, la sécurité, l’automatisation et la normalisation, les conteneurs ont prouvé leur supériorité.
De grandes entreprises bien connues ont signalé que lors de la conteneurisation des applications existantes (beaucoup les appellent des applications traditionnelles) et de l’établissement d’une chaîne d’approvisionnement de logiciels entièrement automatisée basée sur les conteneurs, elles peuvent réduire d’un facteur le coût utilisé pour la maintenance de ces applications critiques. de 50 à 60% et ils peuvent réduire le temps entre les nouvelles versions de ces applications traditionnelles jusqu’à 90%.
Cela dit, l’adoption de la technologie des conteneurs permet à ces entreprises d’économiser beaucoup d’argent, tout en accélérant le processus de développement et en réduisant les délais de commercialisation.
Le projet Moby
À l’origine, lorsque la société Docker a introduit les conteneurs Docker, tout était open source. Docker n’avait pas de produits commerciaux pour le moment. Le moteur Docker que la société a développé était un logiciel monolithique. Il contenait de nombreuses parties logiques, telles que l’exécution du conteneur, une bibliothèque réseau, une API RESTful, une interface de ligne de commande et bien plus encore.
D’autres fournisseurs ou projets tels que Red Hat ou Kubernetes utilisaient le moteur Docker dans leurs propres produits, mais la plupart du temps, ils n’utilisaient qu’une partie de ses fonctionnalités. Par exemple, Kubernetes n’a pas utilisé la bibliothèque réseau Docker du moteur Docker mais a fourni sa propre façon de mettre en réseau. Red Hat à son tour n’a pas mis à jour le moteur Docker fréquemment et a préféré appliquer des correctifs non officiels aux anciennes versions du moteur Docker, mais ils l’appelaient toujours le moteur Docker.
De toutes ces raisons et bien d’autres, l’idée est apparue que Docker devait faire quelque chose pour séparer clairement la partie open source Docker de la partie commerciale Docker. En outre, la société voulait empêcher les concurrents d’utiliser et d’abuser du nom Docker pour leurs propres gains. C’est la raison principale de la naissance du projet Moby. Il sert de cadre à la plupart des composants open source que Docker a développés et continue de développer. Ces projets open source ne portent plus le nom Docker.
Le projet Moby comprend des composants pour la gestion des images, la gestion des secrets, la gestion de la configuration, la mise en réseau et l’approvisionnement, pour n’en nommer que quelques-uns. En outre, une partie du projet Moby comprend des outils Moby spéciaux qui sont, par exemple, utilisés pour assembler des composants en artefacts exécutables.
Certains des composants qui appartiendraient techniquement au projet Moby ont été donnés par Docker à la Cloud Native Computing Foundation (CNCF) et n’apparaissent donc plus dans la liste des composants. Les plus importants sont containerd et runc qui forment ensemble le runtime du conteneur.
Produits Docker
Docker sépare actuellement ses gammes de produits en deux segments. Il y a la Community Edition (CE) qui est une source fermée mais entièrement gratuite, et puis il y a la Enterprise Edition (EE) qui est également une source fermée et doit être sous licence sur une base annuelle. Les produits d’entreprise sont pris en charge par le support 24 x 7 et sont pris en charge avec des corrections de bogues beaucoup plus longtemps que leurs homologues CE.
Docker CE
L’édition de la communauté Docker comprend des produits tels que la boîte à outils Docker, Docker pour Mac et Docker pour Windows. Ces trois produits visent principalement les développeurs.
Docker pour Mac et Docker pour Windows sont des applications de bureau faciles à installer qui peuvent être utilisées pour créer, déboguer et tester des applications ou des services Dockerized sur un Mac ou sur Windows. Docker pour Mac et Docker pour Windows sont des environnements de développement complets qui s’intègrent profondément avec leur infrastructure d’hyperviseur, leur réseau et leur système de fichiers respectifs. Ces outils sont le moyen le plus rapide et le plus fiable d’exécuter Docker sur un Mac ou Windows.
Sous l’égide de la CE, il existe également deux produits plus destinés aux ingénieurs d’exploitation. Ces produits sont Docker pour Azure et Docker pour AWS.
Par exemple, avec Docker pour Azure, qui est une application Azure native, vous pouvez configurer Docker en quelques clics, optimisé et intégré aux services Azure Infrastructure as a Service ( IaaS ) sous-jacents . Il aide les ingénieurs d’exploitation à accélérer le temps nécessaire pour créer et exécuter des applications Docker dans Azure.
Docker pour AWS fonctionne de manière très similaire, mais pour le cloud d’Amazon.
Docker EE
Le Docker EE se compose des deux produits Universal Control Plane (UCP) et Docker Trusted Registry (DTR) qui s’exécutent tous les deux sur Docker Swarm. Les deux sont Applications en essaim. Docker EE s’appuie sur les composants en amont du Moby projette et ajoute des fonctionnalités de niveau entreprise telles que le contrôle d’accès basé sur les rôles (RBAC), la multi-location, les clusters mixtes de Docker Swarm et Kubernetes, l’interface utilisateur Web et la confiance du contenu, ainsi que la numérisation d’images par-dessus.
L’écosystème des conteneurs
Il n’y a jamais eu une nouvelle technologie introduite dans l’informatique qui a pénétré le paysage aussi rapidement et complètement que les conteneurs. Toute entreprise qui ne veut pas être laissée pour compte ne peut ignorer les conteneurs. Cet énorme intérêt pour les conteneurs de tous les secteurs de l’industrie a déclenché de nombreuses innovations dans ce secteur. De nombreuses entreprises se sont spécialisées dans les conteneurs et proposent soit des produits qui s’appuient sur cette technologie, soit des outils qui la prennent en charge.
Initialement, Docker n’avait pas de solution pour l’orchestration de conteneurs, donc d’autres entreprises ou projets, open source ou non, ont tenté de combler cet écart. Le plus important est Kubernetes qui a été lancé par Google et ensuite donné à la CNCF. Les autres produits d’orchestration de conteneurs sont Apache Mesos, Rancher, Open Shift de Red Hat, Swarm de Docker, etc.
Plus récemment, la tendance s’oriente vers un maillage de services. C’est le nouveau mot à la mode. Au fur et à mesure que nous conteneurisons de plus en plus d’applications et que nous transformons ces applications en applications davantage orientées microservices, nous rencontrons des problèmes qu’un logiciel d’orchestration simple ne peut plus résoudre de manière fiable et évolutive. Les sujets dans ce domaine sont la découverte de services, la surveillance, le traçage et l’agrégation de journaux. De nombreux nouveaux projets ont vu le jour dans ce domaine, le plus populaire en ce moment étant Istio, qui fait également partie de la CNCF.
Beaucoup disent que la prochaine étape dans l’évolution du logiciel est les fonctions, ou plus précisément, les fonctions en tant que service (FaaS). Il existe des projets qui fournissent exactement ce type de service et sont construits sur des conteneurs. Un exemple frappant est OpenFaaS.
Nous n’avons fait qu’effleurer la surface de l’écosystème des conteneurs. Toutes les grandes sociétés informatiques telles que Google, Microsoft, Intel, Red Hat, IBM et bien d’autres travaillent fiévreusement sur les conteneurs et les technologies connexes. La CNCF qui porte principalement sur les conteneurs et les technologies associées, a tellement de projets enregistrés, qu’ils ne tiennent plus tous sur une affiche. C’est une période passionnante pour travailler dans ce domaine. Et à mon humble avis, ce n’est que le début.
Architecture des conteneurs
Maintenant, discutons à un niveau élevé de la conception d’un système capable d’exécuter des conteneurs Docker. Le diagramme suivant illustre à quoi ressemble un ordinateur sur lequel Docker a été installé. Soit dit en passant, un ordinateur sur lequel Docker est installé est souvent appelé hôte Docker, car il peut exécuter ou héberger des conteneurs Docker :
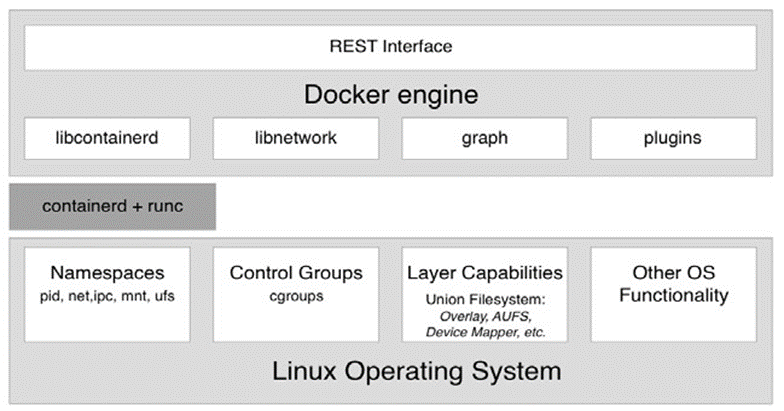
Schéma d’architecture de haut niveau du moteur Docker
Dans le schéma précédent, nous voyons trois parties essentielles :
- En bas, nous avons le système d’exploitation Linux
- Au milieu gris foncé, nous avons le runtime du conteneur
- En haut, nous avons le moteur Docker
Les conteneurs ne sont possibles qu’en raison du fait que le système d’exploitation Linux fournit certaines primitives, telles que les espaces de noms, les groupes de contrôle, les capacités de couche, etc., qui sont exploitées de manière très spécifique par l’exécution du conteneur et le moteur Docker. Les espaces de noms du noyau Linux tels que les espaces de noms Process ID (pid) ou les espaces de noms réseau (net) permettent à Docker d’encapsuler ou de sandboxer les processus qui s’exécutent à l’intérieur du conteneur. Les groupes de contrôle s’assurent que les conteneurs ne peuvent pas souffrir du syndrome du voisin bruyant, où une seule application s’exécutant dans un conteneur peut consommer la plupart ou la totalité des ressources disponibles de l’hôte Docker entier. Les groupes de contrôle permettent à Docker de limiter les ressources, telles que le temps CPU ou la quantité de RAM que chaque conteneur obtient allouée de façon maximale.
Le runtime du conteneur sur un hôte Docker se compose de containerd et runc. runc est la fonctionnalité de bas niveau du conteneur runtime et containerd , qui est basé sur runc , fournit la fonctionnalité de niveau supérieur. Les deux sont open source et ont été donnés par Docker à la CNCF.
Le runtime du conteneur est responsable de l’ensemble du cycle de vie d’un conteneur. Il extrait une image de conteneur (qui est le modèle d’un conteneur) d’un registre si nécessaire, crée un conteneur à partir de cette image, initialise et exécute le conteneur, et finalement arrête et supprime le conteneur du système lorsque cela lui est demandé.
Le moteur Docker fournit des fonctionnalités supplémentaires en plus de l’exécution du conteneur, telles que les bibliothèques réseau ou la prise en charge des plugins. Il fournit également une interface REST sur laquelle toutes les opérations de conteneur peuvent être automatisées. L’interface de ligne de commande Docker que nous utiliserons fréquemment dans cet article est l’un des consommateurs de cette interface REST.
Résumé
Dans ce chapitre, nous avons examiné comment les conteneurs peuvent réduire massivement le frottement dans la chaîne d’approvisionnement du logiciel et en plus, rendre la chaîne d’approvisionnement beaucoup plus sûre.
Dans le prochain chapitre, nous nous familiariserons avec les conteneurs. Nous apprendrons comment exécuter, arrêter et supprimer des conteneurs et les manipuler autrement. Nous aurons également un assez bon aperçu de l’anatomie des conteneurs. Pour la première fois, nous allons vraiment nous salir les mains et jouer avec ces conteneurs, alors restez à l’écoute.
Questions
Veuillez résoudre les questions suivantes pour évaluer vos progrès d’apprentissage :
- Quelles affirmations sont correctes (plusieurs réponses sont possibles) ?
- Un conteneur est une sorte de machine virtuelle légère
- Un conteneur ne fonctionne que sur un hôte Linux
- Un conteneur ne peut exécuter qu’un seul processus
- Le processus principal dans un conteneur a toujours PID 1
- Un conteneur est un ou plusieurs processus encapsulés par des espaces de noms Linux et restreints par des cgroups
- Expliquez à un profane intéressé dans vos propres mots, peut-être en utilisant des analogies, ce qu’est un conteneur.
- Pourquoi les conteneurs changent-ils la donne en informatique ? Nommez trois à quatre raisons.
- Qu’est-ce que cela signifie lorsque nous affirmons : si un conteneur fonctionne sur une plate-forme donnée, il s’exécute n’importe où … ? Nommez deux ou trois raisons pour lesquelles cela est vrai.
- Vrai ou faux : les conteneurs Docker ne sont vraiment utiles que pour les applications greenfield modernes basées sur des microservices. Veuillez justifier votre réponse.
- Combien une entreprise typique économise-t-elle en conteneurisant ses applications héritées ?
- 20%
- 33%
- 50%
- 75%
- Sur quels deux concepts de base de Linux les conteneurs sont-ils basés?
Mise en place d’un environnement de travail
Dans le dernier chapitre, nous avons appris ce que sont les conteneurs Docker et pourquoi ils sont importants. Nous avons appris quels types de conteneurs de problèmes résolvent dans une chaîne d’approvisionnement de logiciels moderne.
Dans ce chapitre, nous allons préparer notre environnement personnel ou professionnel pour travailler efficacement avec Docker. Nous discuterons en détail de la façon de configurer un environnement idéal pour les développeurs, les DevOps et les opérateurs qui peuvent être utilisés lorsque vous travaillez avec des conteneurs Docker.
Ce chapitre couvre les sujets suivants :
- Le shell de commande Linux
- PowerShell pour Windows
- Utilisation d’un gestionnaire de packages
- Choisir un éditeur de code
- Boîte à outils Docker
- Docker pour macOS et Docker pour Windows
- Minikube
- Clonage du référentiel de code source
Après avoir terminé ce chapitre, vous pourrez effectuer les opérations suivantes :
- Utilisez un éditeur sur votre ordinateur portable capable de modifier des fichiers simples tels qu’un Dockerfile ou un fichier docker- compose.yml
- Utilisez un shell tel que Bash sur macOS et PowerShell sur Windows pour exécuter les commandes Docker et d’autres opérations simples, telles que la navigation dans la structure des dossiers ou la création d’un nouveau dossier
- Installez Docker pour macOS ou Docker pour Windows sur votre ordinateur
- Exécuter des commandes Docker simples telles que la version Docker ou le conteneur Docker exécuté sur votre Docker pour macOS ou Docker pour Windows
- Installez Docker Toolbox avec succès sur votre ordinateur
- Utilisez docker-machine pour créer un hôte Docker sur VirtualBox
- Configurer votre CLI Docker locale pour accéder à distance à un hôte Docker exécuté dans VirtualBox
Exigences techniques
Pour ce chapitre, vous aurez besoin d’installer macOS ou Windows, de préférence Windows 10 Professionnel. Vous devez également avoir un accès gratuit à Internet pour télécharger des applications et la permission d’installer ces applications sur votre ordinateur portable.
Le shell de commande Linux
Les conteneurs Docker ont d’abord été développés sur Linux pour Linux. Il est donc naturel que le principal outil de ligne de commande utilisé pour travailler avec Docker, également appelé shell, soit un shell Unix ; rappelez-vous, Linux dérive d’Unix. La plupart des développeurs utilisent le shell Bash. Sur certaines distributions Linux légères, comme Alpine, Bash n’est pas installé et, par conséquent, il faut utiliser le shell Bourne plus simple, juste appelé sh. Chaque fois que nous travaillons dans un environnement Linux, comme à l’intérieur d’un conteneur ou sur une machine virtuelle Linux, nous utiliserons /bin/bash ou /bin/sh, selon leur disponibilité.
Bien que macOS X ne soit pas un système d’exploitation Linux, Linux et OS X sont tous deux des versions d’Unix et prennent donc en charge les mêmes types d’outils. Parmi ces outils, il y a les coquilles. Ainsi, lorsque vous travaillez sur un macOS, vous utiliserez probablement le shell Bash.
Dans cet article, nous attendons des lecteurs une familiarité avec les commandes de script les plus élémentaires de Bash et PowerShell si vous travaillez sous Windows. Si vous êtes un débutant absolu, nous vous recommandons fortement de vous familiariser avec les feuilles de triche suivantes :
- Aide-mémoire sur la ligne de commande Linux de Dave Child sur http://bit.ly/2mTQr8l
- Aide-mémoire de base PowerShell sur http://bit.ly/2EPHxze
PowerShell pour Windows
Sur un ordinateur, un ordinateur portable ou un serveur Windows, nous avons plusieurs outils de ligne de commande disponibles. Le plus familier est le shell de commande. Il est disponible sur n’importe quel ordinateur Windows depuis des décennies. C’est une coquille très simple. Pour des scripts plus avancés, Microsoft a développé PowerShell. PowerShell est très puissant et très populaire parmi les ingénieurs travaillant sur Windows. Sur Windows 10, enfin, nous avons le soi-disant sous-système Windows pour Linux, qui nous permet d’utiliser n’importe quel outil Linux, comme les shells Bash ou Bourne. En dehors de cela, il existe également d’autres outils qui installent un shell Bash sur Windows, par exemple, le shell Git Bash. Dans cet article, toutes les commandes utiliseront la syntaxe Bash. La plupart des commandes s’exécutent également dans PowerShell.
Nous vous recommandons donc d’utiliser PowerShell ou tout autre outil Bash pour travailler avec Docker sous Windows.
Utilisation d’un gestionnaire de packages
La façon la plus simple d’installer un logiciel sur un ordinateur portable macOS ou Windows est d’utiliser un bon gestionnaire de paquets. Sur macOS, la plupart des gens utilisent Homebrew et sur Windows, Chocolatey est un bon choix.
Installer Homebrew sur un macOS
Installer Homebrew sur un macOS est facile ; suivez simplement les instructions sur https://brew.sh/
Voici la commande pour installer Homebrew :
/usr/bin/ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)”
Une fois l’installation terminée, testez si Homebrew fonctionne en entrant brew –version dans le Terminal. Vous devriez voir quelque chose comme ceci :
$ brew –version
Homebrew 1.4.3
Homebrew/homebrew-core (git revision f4e35; last commit 2018-01-11)
Maintenant, nous sommes prêts à utiliser Homebrew pour installer des outils et des utilitaires. Si nous voulons, par exemple, installer l’éditeur de texte Vi, nous pouvons le faire comme ceci:
$ brew install vim
Cela va ensuite télécharger et installer l’éditeur pour vous.
Installer Chocolatey sur Windows
Pour installer le gestionnaire de packages Chocolatey sous Windows, veuillez suivre les instructions sur https://chocolatey.org/ ou simplement exécuter la commande suivante dans un terminal PowerShell que vous avez exécuté en tant qu’administrateur :
PS> Set-ExecutionPolicy Bypass -Scope Process -Force; iex ((New-Object System.Net.WebClient).DownloadString(‘https://chocolatey.org/install. ps1’))
Une fois Chocolatey installé, testez-le avec la commande choco sans paramètres supplémentaires. Vous devriez voir une sortie similaire à la suivante :
PS> choco
Chocolatey v0.10.3
Pour installer une application telle que l’éditeur Vi, utilisez la commande suivante :
PS> choco install -y vim
Le paramètre -y garantit que l’installation se déroule sans demander de reconfirmation. Veuillez noter qu’une fois que Chocolatey a installé une application, vous devez ouvrir une nouvelle fenêtre PowerShell pour l’utiliser.
Choisir un éditeur de code
L’utilisation d’un bon éditeur de code est essentielle pour travailler de manière productive avec Docker. Bien sûr, quel éditeur est le meilleur est très controversé et dépend de vos préférences personnelles. Beaucoup de gens utilisent Vim, ou d’autres tels que Emacs, Atom, Sublime ou Visual Studio (VS) Code, pour n’en nommer que quelques-uns. Si vous n’avez pas encore décidé quel éditeur vous convient le mieux, alors je vous recommande fortement d’essayer VS Code. Il s’agit d’un éditeur gratuit et léger, mais il est très puissant et est disponible pour macOS, Windows et Linux. Essaie. Vous pouvez télécharger VS Code à partir de https://code.visualstudio.com/download.
Mais si vous avez déjà un éditeur de code préféré, continuez à l’utiliser. Tant que vous pouvez modifier des fichiers texte, vous êtes prêt à partir. Si votre éditeur prend en charge la coloration syntaxique pour les fichiers Dockerfiles et JSON et YAML, c’est encore mieux.
Docker Toolbox
Docker Toolbox est disponible pour les développeurs depuis quelques années. Il précède les nouveaux outils tels que Docker pour macOS et Docker pour Windows. La boîte à outils permet à un utilisateur de travailler de manière très élégante avec des conteneurs sur n’importe quel ordinateur macOS ou Windows. Les conteneurs doivent s’exécuter sur un hôte Linux. Ni Windows ni macOS ne peuvent exécuter les conteneurs en mode natif. Ainsi, nous devons exécuter une machine virtuelle Linux sur notre ordinateur portable, où nous pouvons ensuite exécuter nos conteneurs. Docker Toolbox installe VirtualBox sur notre ordinateur portable, qui est utilisé pour exécuter les machines virtuelles Linux dont nous avons besoin.
En tant qu’utilisateur Windows, vous savez peut-être déjà qu’il existe des soi-disant conteneurs Windows qui s’exécutent nativement sur Windows. Et tu as raison. Récemment, Microsoft a porté le moteur Docker vers Windows et il est désormais possible d’exécuter des conteneurs Windows directement sur Windows Server 2016 sans avoir besoin d’une machine virtuelle. Nous avons donc maintenant deux versions de conteneurs, les conteneurs Linux et les conteneurs Windows. Les premiers ne fonctionnent que sur l’hôte Linux et les seconds ne fonctionnent que sur un serveur Windows. Dans cet article, nous discutons exclusivement des conteneurs Linux, mais la plupart des choses que nous apprenons s’appliquent également aux conteneurs Windows.
Utilisons docker-machine pour configurer notre environnement. Premièrement, nous listons toutes les VM Dockerready que nous avons actuellement définies sur notre système. Si vous venez d’installer Docker Toolbox, vous devriez voir la sortie suivante :

Liste de toutes les machines virtuelles compatibles Docker
L’adresse IP utilisée peut-être différente dans votre cas, mais elle sera certainement dans la plage 192.168.0.0/24. Nous pouvons également voir que la VM a Docker version 18.04.0-ce installé.
Si, pour une raison quelconque, vous n’avez pas de machine virtuelle par défaut ou si vous l’avez accidentellement supprimée, vous pouvez la créer à l’aide de la commande suivante :
$ docker-machine create –driver virtualbox default
La sortie que vous devriez voir se présente comme suit :
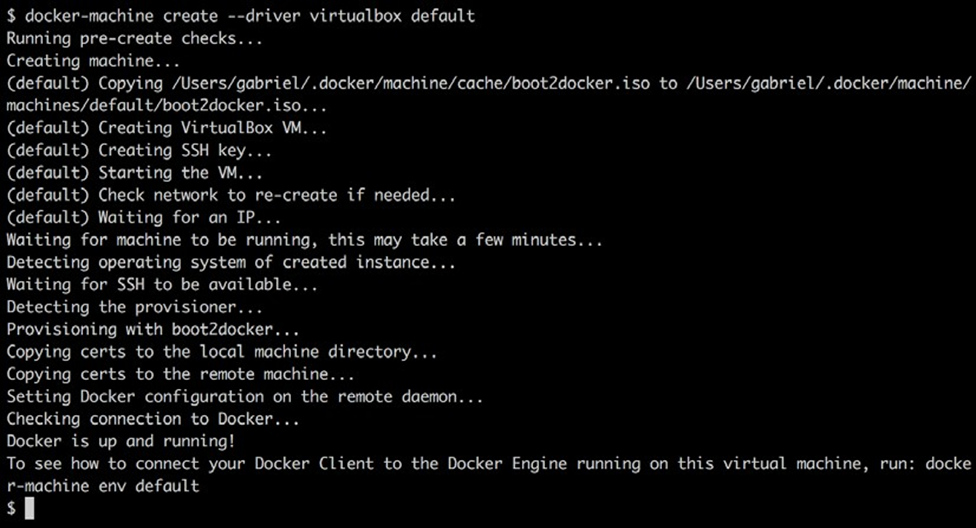
Création de la VM appelée par défaut dans VirtualBox
Pour voir comment connecter votre client Docker au moteur Docker exécuté sur cette machine virtuelle, exécutez la commande suivante :
$ docker-machine env default
Une fois que notre machine virtuelle appelée par défaut est prête, nous pouvons essayer de la connecter en SSH :
$ docker-machine ssh default
Lors de l’exécution de la commande précédente, nous sommes accueillis par un message de bienvenue boot2docker.
Tapez docker –version dans l’invite de commandes comme suit :
docker@default:~$ docker –version
Docker version 18.06.1-ce, build e68fc7a
Maintenant, essayons d’exécuter un conteneur :
docker@default:~$ docker run hello-world
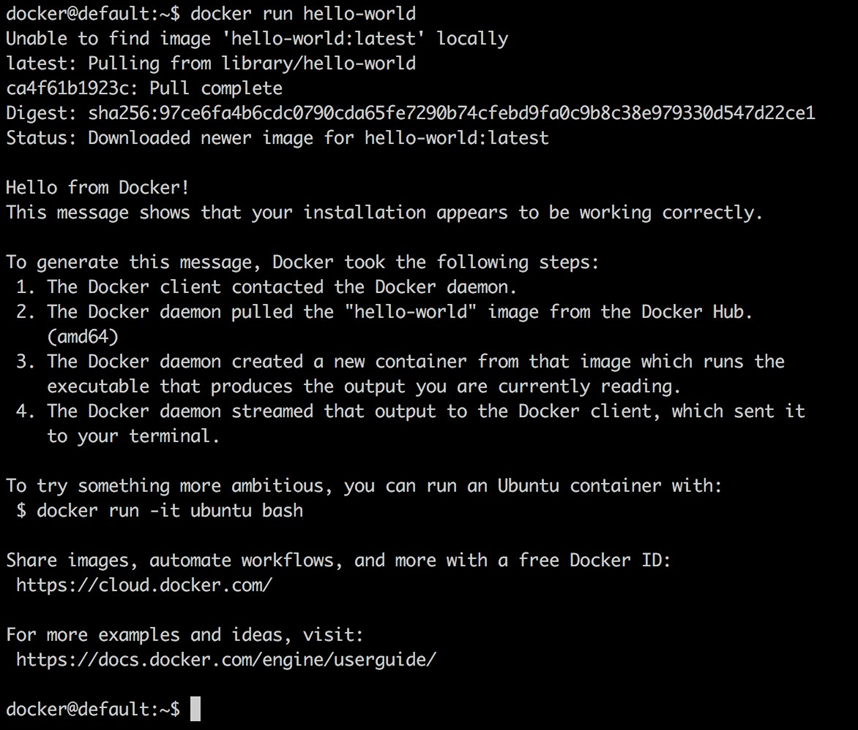
Exécution du conteneur Docker Hello World
Docker pour macOS et Docker pour Windows
Si vous utilisez un macOS ou que Windows 10 Professionnel est installé sur votre ordinateur portable, nous vous recommandons fortement d’installer Docker pour macOS ou Docker pour Windows. Ces outils vous offrent la meilleure expérience lorsque vous travaillez avec des conteneurs. Remarque : les anciennes versions de Windows ou de Windows 10 Home Edition ne peuvent pas exécuter Docker pour Windows. Docker pour Windows utilise Hyper-V pour exécuter des conteneurs de manière transparente dans une machine virtuelle, mais Hyper-V n’est pas disponible sur les anciennes versions de Windows ni dans l’édition familiale.
Installation de Docker pour macOS
Accédez au lien suivant pour télécharger Docker pour macOS sur https://docs.docker.com/docker-for-mac/install/.
Il existe une version stable et une version dite de bord de l’outil disponibles. Dans cet article, nous allons utiliser des fonctionnalités plus récentes et Kubernetes, qui, au moment de la rédaction, ne sont disponibles que dans la version Edge. Veuillez donc sélectionner cette version.
Pour démarrer l’installation :
1. Cliquez sur le bouton Get Docker for Mac (Edge) et suivez les instructions.
2. Une fois que vous avez correctement installé Docker pour macOS, ouvrez un terminal. Appuyez sur commande + barre d’espace pour ouvrir Spotlight et tapez terminal, puis appuyez sur entrée. Le terminal d’Apple sera ouvert comme suit :

Apple Terminal window
3. Tapez docker –version dans l’invite de commande et appuyez sur Entrée. Si Docker pour macOS est correctement installé, vous devriez obtenir une sortie similaire à la suivante :
$ docker –version
Docker version 18.02.0-ce-rc2, build f968a2c
4. Pour voir si vous pouvez exécuter des conteneurs, entrez la commande suivante dans le terminal et appuyez sur Entrée :
$ docker run hello-world
Si tout se passe bien, votre sortie devrait ressembler à ceci :
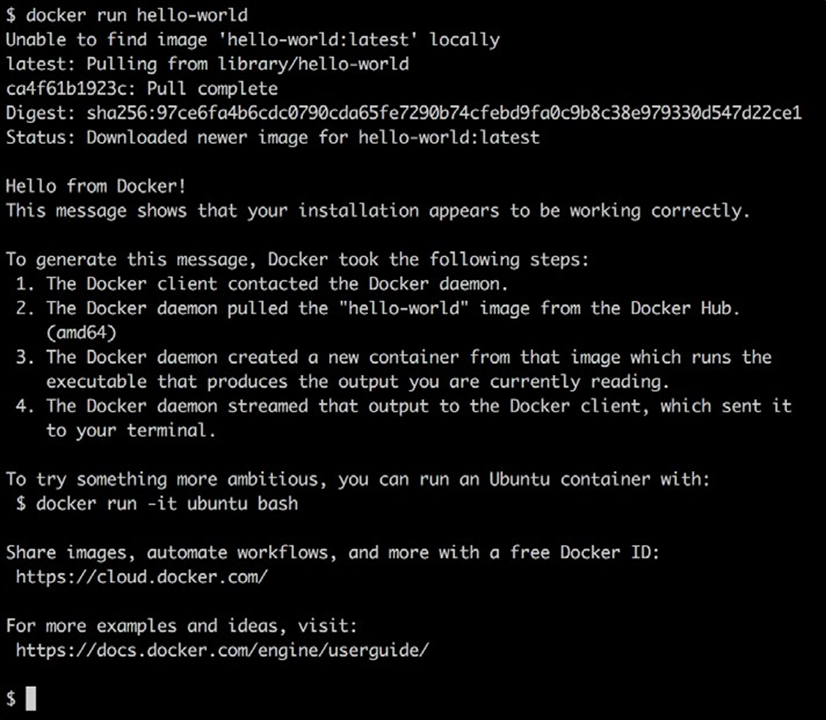
Exécution du conteneur Hello World sur Docker pour macOS
Félicitations, vous êtes maintenant prêt à travailler avec les conteneurs Docker.
Installation de Docker pour Windows
Remarque, vous ne pouvez installer Docker pour Windows que sur Windows 10 Professionnel ou Windows Server 2016 car il nécessite Hyper-V, qui n’est pas disponible sur les ancienness Versions Windows ou sur l’édition Home de Windows 10. Si vous utilisez Windows 10 Home ou une ancienne version de Windows, vous devrez vous en tenir à Docker Toolbox.
1. Accédez au lien suivant pour télécharger Docker pour Windows à l’adresse https://docs.docker.com/docker-for-windows/install/.
Il existe une version stable et une version dite de bord de l’outil disponibles. Dans cet article, nous allons utiliser des fonctionnalités plus récentes et Kubernetes, qui, au moment de la rédaction, ne sont disponibles que dans la version Edge. Veuillez donc sélectionner cette version.
2. Pour démarrer l’installation, cliquez sur le bouton Get Docker for Windows (Edge) et suivez les instructions. Avec Docker pour Windows, vous pouvez développer, exécuter et tester des conteneurs Linux et des conteneurs Windows. Dans cet article, cependant, nous ne discutons que des conteneurs Linux.
3. Une fois que vous avez correctement installé Docker pour Windows. Ouvrez une fenêtre PowerShell et tapez docker –version dans l’invite de commandes. Vous devriez voir quelque chose comme ceci :
PS> docker –version
Docker version 18.04.0-ce, build 3d479c0
Utilisation de docker-machine sous Windows avec Hyper-V
Si Docker pour Windows est installé sur votre ordinateur portable Windows, Hyper-V est également activé. Dans ce cas, vous ne pouvez pas utiliser Docker Toolbox car il utilise VirtualBox, et Hyper-V et VirtualBox ne peuvent pas coexister et s’exécuter en même temps. Dans ce cas, vous pouvez utiliser docker-machine avec le pilote Hyper-V.
1. Ouvrez une console PowerShell en tant qu’administrateur. Installez docker-machine à l’aide de Chocolatey comme suit:
PS> choco install -y docker-machine
2. À l’aide du gestionnaire Hyper-V de Windows, créez un nouveau commutateur interne appelé DM Internal Switch, où DM signifie docker-machine.
3. Créez une machine virtuelle appelée par défaut dans Hyper-V avec la commande suivante :
PS> docker-machine create –driver hyperv –hyperv-virtual- switch “DM Internal Switch” default
Vous devez exécuter la commande précédente en mode administrateur, sinon elle échouera.
Vous devriez voir la sortie suivante générée par la commande précédente :
Running pre-create checks…
(boot2docker) Image cache directory does not exist, creating it at C:\Users\Docker\.docker\machine\cache… (boot2docker) No default Boot2Docker ISO found locally, downloading the latest release…
(boot2docker) Latest release for github.com/boot2docker/
boot2docker is v18.06.1-ce ….
….
Checking connection to Docker…
Docker is up and running!
To see how to connect your Docker Client to the Docker Engine running on this virtual machine, run: C:\Program Files\Doc ker\Docker\Resources\bin\docker-machine.exe env default
4. Pour voir comment connecter votre client Docker au moteur Docker exécuté sur cette machine virtuelle, exécutez ce qui suit :
C:\Program Files\Docker\Docker\Resources\bin\docker-machine.exe env default
5. La liste de toutes les machines virtuelles générées par docker-machine nous donne la sortie suivante :
PS C:\WINDOWS\system32> docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
default . – hyperv Running tcp://[…]:2376 v18.06.1-ce
6. Maintenant, passons à SSH dans notre VM boot2docker :
PS> docker-machine ssh default
Vous devriez être accueilli par l’écran d’accueil.
Nous pouvons tester la machine virtuelle en exécutant notre commande docker version , qui est illustrée comme suit:
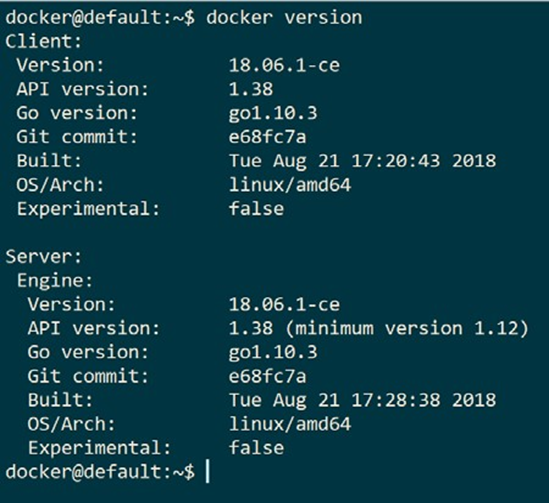
Version du client Docker (CLI) et du serveur
Il s’agit certainement d’une machine virtuelle Linux, comme nous pouvons le voir sur l’entrée OS / Arch, et Docker 18.06.1-c’est installé.
Minikube
Si vous ne pouvez pas utiliser Docker pour macOS ou Windows ou, pour une raison quelconque, vous n’avez accès qu’à une ancienne version de l’outil qui ne prend pas encore en charge Kubernetes, alors c’est une bonne idée d’installer Minikube. Minikube fournit un cluster Kubernetes à nœud unique sur votre poste de travail et est accessible via kubectl , qui est l’outil de ligne de commande utilisé pour travailler avec Kubernetes.
Installation de Minikube sur macOS et Windows
Pour installer Minikube pour macOS ou Windows, accédez au lien suivant à https://kubernetes.io/docs/tasks/tools/install-minikube/.
Suivez attentivement les instructions. Si Docker Toolbox est installé, vous disposez déjà d’un hyperviseur sur votre système, car le programme d’installation de Docker Toolbox a également installé VirtualBox. Sinon, je vous recommande d’installer d’abord VirtualBox.
Si Docker pour macOS ou Windows est installé, vous avez déjà installé kubectl , vous pouvez donc ignorer cette étape également. Sinon, suivez les instructions sur le site.
Enfin, sélectionnez le dernier binaire pour Minikube pour macOS ou Windows et installez-le. Pour macOS, le dernier binaire s’appelle minikube-darwin-amd64 et pour Windows, il est minikube-windows-amd64.
Test de Minikube et kubectl
Une fois Minikube installé avec succès sur votre poste de travail, ouvrez un terminal et testez l’installation.
1. Tout d’abord, nous devons démarrer Minikube . Entrez minikube start sur la ligne de commande. La sortie doit ressembler à ceci :
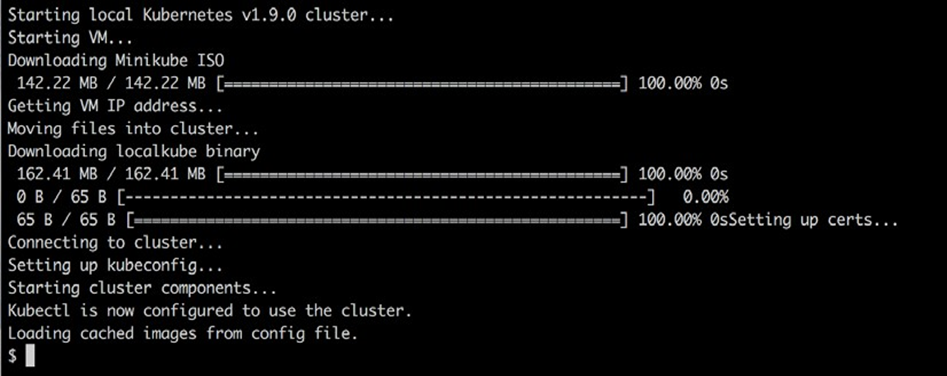
Starting Minikube
2. Maintenant, entrez la version de kubectl et appuyez sur Entrée pour voir quelque chose comme la capture d’écran suivante :

Déterminer la version du client et du serveur Kubernetes
Si la commande précédente échoue, par exemple, en expirant, il se peut que votre kubectl ne soit pas configuré pour le bon contexte. kubectl peut être utilisé pour fonctionner avec de nombreux clusters Kubernetes différents. Chaque cluster est appelé un contexte.
3. Pour savoir pour quel contexte kubectl est actuellement configuré, utilisez la commande suivante :
$ kubectl config current-context minikube
La réponse doit être minikube , comme indiqué dans la sortie précédente.
4. Si ce n’est pas le cas, utilisez kubectl config get-contexts pour répertorier tous les contextes définis sur votre système, puis définissez le contexte actuel sur minikube comme suit :
$ kubectl config use-context minikube
La configuration de kubectl , où il stocke les contextes, se trouve normalement dans ~ /. kube / config , mais cela peut être remplacé en définissant une variable d’environnement appelée KUBECONFIG . Vous devrez peut-être désactiver cette variable si elle est définie sur votre ordinateur.
Pour plus d’informations sur la configuration et l’utilisation des contextes Kubernetes, consultez le lien à https://kubernetes.io/docs/concepts/ configuration / organise-cluster- access – kubeconfig / .
En supposant que Minikube et kubectl fonctionnent comme prévu, nous pouvons maintenant utiliser kubectl pour obtenir des informations sur le cluster Kubernetes.
5. Entrez la commande suivante :
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready <none> 47d v1.9.0
Évidemment, nous avons un cluster d’un nœud, sur lequel Kubernetes v1.9.0 est installé.
Clonage du référentiel de code source
Cet article est accompagné du code source accessible au public. Clonez ce référentiel sur votre ordinateur local.
Tout d’abord créer un nouveau dossier par exemple, dans votre dossier maison, comme apps- withdocker -et- Kubernetes et parcourir l’itinéraire :
$ mkdir -p ~/apps-with-docker-and-kubernetes \ cd apps-with-docker-and-kubernetes
Et puis clonez le référentiel avec la commande suivante :
$ git clone https://github.com/appswithdockerandkubernetes/labs. git
Résumé
Dans ce chapitre, nous avons installé et configuré notre environnement personnel ou professionnel afin de pouvoir travailler de manière productive avec les conteneurs Docker. Cela s’applique également aux développeurs, aux DevOps et aux ingénieurs d’exploitation. Dans ce contexte, nous nous sommes assurés que nous utilisons un bon éditeur, que Docker pour macOS ou Windows est installé et que nous pouvons également utiliser docker-machine pour créer des machines virtuelles dans VirtualBox ou Hyper-V que nous pouvons utiliser pour exécuter et tester des conteneurs.
Dans le chapitre suivant, nous allons apprendre tous les faits importants sur les conteneurs. Par exemple, nous explorerons comment exécuter, arrêter, répertorier et supprimer des conteneurs, mais plus que cela, nous plongerons également profondément dans l’anatomie des conteneurs.
Questions
Sur la base de votre lecture de ce chapitre, veuillez répondre aux questions suivantes :
1. À quoi sert la machine docker ? Nommez trois à quatre scénarios.
2. Vrai ou faux ? Avec Docker pour Windows, on peut développer et exécuter des conteneurs Linux.
3. Pourquoi de bonnes compétences en script (comme Bash ou PowerShell) sont-elles essentielles pour une utilisation productive des conteneurs ?
4. Nommez trois à quatre distributions Linux sur lesquelles Docker est certifié pour fonctionner.
5. Nommez toutes les versions de Windows sur lesquelles vous pouvez exécuter des conteneurs Windows.
Travailler avec des conteneurs
Dans le chapitre précédent, vous avez appris à préparer de manière optimale votre environnement de travail pour une utilisation productive et sans friction de Docker. Dans ce chapitre, nous allons nous salir les mains et apprendre tout ce qui est important pour travailler avec des conteneurs. Voici les sujets que nous allons couvrir dans ce chapitre :
- Exécution du premier conteneur
- Démarrage, arrêt et retrait des conteneurs
- Inspection des conteneurs
- Exec dans un conteneur en cours d’exécution
- Fixation à un conteneur en cours d’exécution
- Récupération des journaux des conteneurs
- Anatomie des conteneurs
Après avoir terminé ce chapitre, vous pourrez effectuer les opérations suivantes :
- Exécuter, arrêter et supprimer un conteneur basé sur une image existante, telle que NGINX, busybox ou alpine
- Liste de tous les conteneurs du système
- Inspectez les métadonnées d’un conteneur en cours d’exécution ou arrêté
- Récupérer les journaux produits par une application s’exécutant à l’intérieur d’un conteneur
- Exécutez un processus tel que / bin / sh dans un conteneur déjà en cours d’exécution.
- Attacher un terminal à un conteneur déjà en cours d’exécution
- Expliquez dans vos propres mots à un profane intéressé les fondements d’un conteneur
Exigences techniques
Pour ce chapitre, vous devez avoir installé Docker pour Mac ou Docker pour Windows. Si vous utilisez une ancienne version de Windows ou utilisez Windows 10 Home Edition, Docker Toolbox doit être installé et prêt à l’emploi. Sous macOS, utilisez l’application Terminal et sous Windows, une console PowerShell pour essayer les commandes que vous apprendrez.
Exécution du premier conteneur
Avant de commencer, nous voulons nous assurer que Docker est correctement installé sur votre système et prêt à accepter vos commandes. Ouvrez une nouvelle fenêtre de terminal et saisissez la commande suivante :
$ docker -v
Si tout fonctionne correctement, vous devriez voir la version de Docker installée sur la sortie de votre ordinateur portable dans le terminal. Au moment de la rédaction, cela ressemble à ceci :
Docker version 17.12.0-ce-rc2, build f9cde63
Si cela ne fonctionne pas, alors quelque chose avec votre installation ne va pas. Veuillez-vous assurer d’avoir suivi les instructions du chapitre précédent sur la façon d’installer Docker pour Mac ou Docker pour Windows sur votre système.
Vous êtes donc prêt à voir une action. Veuillez saisir la commande suivante dans votre fenêtre de terminal et appuyez sur retour :
$ docker container run alpine echo “Hello World”
Lorsque vous exécutez la commande précédente la première fois, vous devriez voir une sortie dans votre fenêtre Terminal similaire à ceci :
Unable to find image ‘alpine:latest’ locally latest: Pulling from library/alpine 2fdfe1cd78c2: Pull complete Digest: sha256:ccba511b…
Status: Downloaded newer image for alpine:latest
Hello World
C’était facile ! Essayons d’exécuter à nouveau la même commande :
$ docker container run alpine echo “Hello World”
La deuxième, troisième ou nième fois que vous exécutez la commande précédente, vous ne devriez voir que cette sortie dans votre terminal :
Hello World
Essayez de comprendre pourquoi la première fois que vous exécutez une commande, vous voyez une sortie différente de toutes les fois suivantes. Ne vous inquiétez pas si vous ne pouvez pas le comprendre, nous expliquerons les raisons en détail dans les sections suivantes du chapitre.
Démarrage, arrêt et retrait des conteneurs
Vous avez réussi à exécuter un conteneur dans la section précédente. Maintenant, nous voulons enquêter en détail sur ce qui s’est exactement passé et pourquoi. Regardons à nouveau la commande que nous avons utilisée :
$ docker container run alpine echo “Hello World”
Cette commande contient plusieurs parties. D’abord et avant tout, nous avons le mot docker. Il s’agit du nom de l’interface de ligne de commande (CLI) Docker, que nous utilisons pour interagir avec le moteur Docker responsable de l’exécution des conteneurs. Ensuite, nous avons le mot conteneur, qui indique le contexte avec lequel nous travaillons. Comme nous voulons exécuter un conteneur, notre contexte est le mot conteneur. Vient ensuite la commande réelle que nous voulons exécuter dans le contexte donné, qui est exécutée.
Permettez – moi de récapituler- à ce jour, nous avons l’exécution de conteneurs docker, ce qui signifie, Hey Docker, nous voulons lancer un récipient ….
Maintenant, nous devons également indiquer à Docker quel conteneur exécuter. Dans ce cas, il s’agit du soi – disant conteneur alpin. Enfin, nous devons définir quel type de processus ou de tâche doit être exécuté à l’intérieur du conteneur lorsqu’il est en cours d’exécution. Dans notre cas, il s’agit de la dernière partie de la commande, echo “Hello World”.
La figure suivante peut vous aider à obtenir une meilleure approche de l’ensemble :
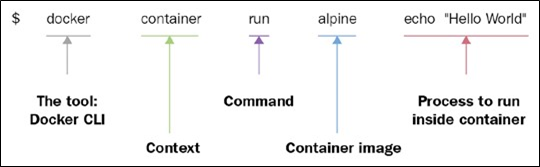
Anatomie de l’expression d’exécution du conteneur Docker
Maintenant que nous avons compris les différentes parties d’une commande pour exécuter un conteneur, essayons d’exécuter un autre conteneur avec un processus différent en cours d’exécution. Tapez la commande suivante dans votre terminal :
$ docker container run centos ping -c 5 127.0.0.1
Vous devriez voir une sortie dans votre fenêtre Terminal similaire à la suivante :
Unable to find image ‘centos:latest’ locally latest: Pulling from library/centos 85432449fd0f: Pull complete Digest: sha256:3b1a65e9a05…
Status: Downloaded newer image for centos:latest PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.022 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.019 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.029 ms
64 bytes from 127.0.0.1: icmp_seq=4 ttl=64 time=0.030 ms
64 bytes from 127.0.0.1: icmp_seq=5 ttl=64 time=0.029 ms
— 127.0.0.1 ping statistics —
5 packets transmitted, 5 received, 0% packet loss, time 4103ms rtt min/avg/max/mdev = 0.021/0.027/0.029/0.003 ms
Ce qui a changé, c’est que cette fois, l’image du conteneur que nous utilisons est centos et le processus que nous exécutons à l’intérieur du conteneur centos est ping -c 5 127.0.0.1, qui envoie cinq fois l’adresse de bouclage à un ping jusqu’à ce qu’elle s’arrête.
Analysons la sortie en détail :
- La première ligne est la suivante :
Unable to find image ‘centos:latest’ locally
Cela nous indique que Docker n’a pas trouvé d’image nommée centos: dernier dans le cache local du système. Ainsi, Docker sait qu’il doit extraire l’image d’un registre dans lequel les images de conteneur sont stockées. Par défaut, votre environnement Docker est configuré de telle sorte que les images soient extraites du Docker Hub sur docker.io. Ceci est exprimé par la deuxième ligne, comme suit :
latest: Pulling from library/centos
- Les trois lignes de sortie suivantes sont les suivantes :
85432449fd0f: Pull complete
Digest: sha256:3b1a65e9a05…
Status: Downloaded newer image for centos:latest
Cela nous indique que Docker a réussi à extraire les centos d’image : les plus récents du Docker Hub.
Toutes les lignes suivantes de la sortie sont générées par le processus que nous avons exécuté à l’intérieur du conteneur, qui est l’outil ping dans ce cas. Si vous avez été attentif jusqu’à présent, vous avez peut-être remarqué que le mot-clé le plus récent s’est produit plusieurs fois. Chaque image a une version (également appelée balise), et si nous ne spécifions pas explicitement de version, Docker l’assume automatiquement comme la plus récente.
Si nous exécutons à nouveau le conteneur précédent sur notre système, les cinq premières lignes de la sortie seront manquantes car, cette fois, Docker trouvera l’image du conteneur mise en cache localement et n’aura donc pas à la télécharger en premier. Pour le vérifier, essayez-le.
Exécution d’un conteneur de devis aléatoires
Pour les sections suivantes de ce chapitre, nous avons besoin d’un conteneur qui s’exécute en continu en arrière-plan et produit une sortie intéressante. C’est pourquoi nous avons choisi un algorithme qui produit des citations aléatoires. L’API qui produit ces citations aléatoires gratuites peut être trouvée sur https://talaikis.com/random_quotes_api/.
Maintenant, l’objectif est d’avoir un processus en cours d’exécution à l’intérieur d’un conteneur qui produit un nouveau devis aléatoire toutes les cinq secondes et renvoie le devis à STDOUT. Le script suivant fera exactement cela :
while :
do
wget -qO- https://talaikis.com/api/quotes/random
printf ‘n’
sleep 5 done
Essayez-le dans une fenêtre de terminal. Arrêtez le script en appuyant sur Ctrl + C. La sortie devrait ressembler à ceci :
{“quote”:”Martha Stewart is extremely talented. Her designs are picture perfect. Our philosophy is life is messy, and rather than being afraid of those messes we design products that work the way we
live.”,”author”:”Kathy Ireland”,”cat”:”design”}
{“quote”:”We can reach our potential, but to do so, we must reach within ourselves. We must summon the strength, the will, and the faith to move forward – to be bold – to invest in our future.”,”author”:”John Hoeven”,”cat”:”faith”}
Chaque réponse est une chaîne au format JSON avec la citation, son auteur et sa catégorie.
Maintenant, exécutons cela dans un conteneur alpin en tant que démon en arrière-plan. Pour cela, nous devons compacter le script précédent en une seule ligne et l’exécuter en utilisant la syntaxe / bin / sh -c “…”. Notre expression Docker se présente comme suit :
$ docker container run -d –name quotes alpine \
/bin/sh -c “while :; do wget -qO- https://talaikis.com/api/quotes/ random; printf ‘\n’; sleep 5; done”
Dans l’expression précédente, nous avons utilisé deux nouveaux paramètres de ligne de commande, -d et –name . Le -d indique à Docker d’exécuter le processus en cours d’exécution dans le conteneur en tant que démon Linux. Le paramètre –name à son tour peut être utilisé pour donner au conteneur un nom explicite. Dans l’exemple précédent, le nom que nous avons choisi est des guillemets.
Si nous ne spécifions pas de nom de conteneur explicite lorsque nous exécutons un conteneur, Docker attribue automatiquement au conteneur un nom aléatoire mais unique. Ce nom sera composé du nom d’un célèbre scientifique et et adjectif. Ces noms peuvent être boring_borg ou angry_goldberg . Assez humoristique nos ingénieurs Docker, n’est-ce pas ?
Un point important à retenir est que le nom du conteneur doit être unique sur le système. Assurons-nous que le conteneur de devis est opérationnel :
$ docker container ls -l
Cela devrait nous donner quelque chose comme ceci :

Liste du dernier conteneur d’exécution
La partie importante de la sortie précédente est la colonne STATUS, qui dans ce cas est Up 16 secondes. Autrement dit, le conteneur est opérationnel depuis 16 secondes maintenant.
Ne vous inquiétez pas si la dernière commande Docker ne vous est pas encore familière, nous y reviendrons dans la section suivante.
Liste des conteneurs
Comme nous continuons à gérer des conteneurs au fil du temps, nous en obtenons beaucoup dans notre système. Pour découvrir ce qui est actuellement en cours d’exécution sur notre hôte, nous pouvons utiliser la commande list de conteneurs comme suit:
$ docker container ls
Cela répertoriera tous les conteneurs en cours d’exécution. Une telle liste pourrait ressembler à ceci:

Liste de tous les conteneurs en cours d’exécution sur le système
Par défaut, Docker génère sept colonnes avec les significations suivantes :
| Column | Description |
| Container ID | The unique ID of the container. It is a SHA-256. |
| Image | The name of the container image from which this container is instantiated. |
| Command | The command that is used to run the main process in the container. |
| Created | The date and time when the container was created. |
| Status | The status of the container (created, restarting, running, removing, paused, exited, or dead). |
| Ports | The list of container ports that have been mapped to the host. |
| Names | The name assigned to this container (multiple names are possible). |
Si nous voulons répertorier non seulement les conteneurs en cours d’exécution, mais tous les conteneurs définis sur notre système, nous pouvons utiliser le paramètre de ligne de commande -a ou –all comme suit :
$ docker container ls -a
Cela répertoriera les conteneurs dans n’importe quel état, tels que créés, en cours d’exécution ou fermés.
Parfois, nous voulons simplement répertorier les ID de tous les conteneurs. Pour cela, nous avons le paramètre -q :
$ docker container ls -q
Vous vous demandez peut-être où cela est utile. La commande suivante montre où cela peut être très utile :
$ docker container rm -f $ (docker container ls -a -q)
Penchez-vous en arrière et respirez profondément. Ensuite, essayez de découvrir ce que fait la commande précédente. Ne lisez pas plus loin jusqu’à ce que vous trouviez la réponse ou abandonniez.
La commande précédente supprime tous les conteneurs actuellement définis sur le système, y compris ceux qui sont arrêtés. La commande rm signifie supprimer, et elle sera expliquée plus loin.
Dans la section précédente, nous avons utilisé le paramètre -l dans la commande list. Essayez d’utiliser l’aide de Docker pour savoir ce que signifie le paramètre -l. Vous pouvez appeler l’aide de la commande list comme suit :
$ docker container ls -h
Arrêt et démarrage des conteneurs
Parfois, nous voulons arrêter (temporairement) un conteneur en cours d’exécution. Essayons cela avec le conteneur de citations que nous avons utilisé précédemment. Exécutez à nouveau le conteneur avec cette commande :
$ docker container run -d –name quotes alpine \
/bin/sh -c “while :; do wget -qO- https://talaikis.com/api/quotes/ random; printf ‘\n’; sleep 5; done”
Maintenant, si nous voulons arrêter ce conteneur, nous pouvons le faire en émettant cette commande :
$ docker container stop quotes
Lorsque vous essayez d’arrêter le conteneur de guillemets, vous remarquerez probablement qu’il faut un certain temps pour que cette commande soit exécutée. Pour être précis, cela prend environ 10 secondes. Pourquoi est-ce le cas ?
Docker envoie un signal Linux SIGTERM au processus principal exécuté à l’intérieur du conteneur. Si le processus ne réagit pas à ce signal et ne se termine pas lui-même, Docker attend 10 secondes, puis envoie SIGKILL, qui tuera le processus avec force et terminera le conteneur.
Dans la commande précédente, nous avons utilisé le nom du conteneur pour spécifier le conteneur que nous voulons arrêter. Mais nous aurions également pu utiliser l’ID de conteneur à la place.
Comment obtient-on l’ID d’un conteneur ? Il y a plusieurs façons de le faire. L’approche manuelle consiste à répertorier tous les conteneurs en cours d’exécution et à trouver celui que nous recherchons dans la liste. De là, nous copions son ID. Un moyen plus automatisé consiste à utiliser des scripts shell et des variables d’environnement. Si, par exemple, nous voulons obtenir l’ID du conteneur de guillemets, nous pouvons utiliser cette expression :
$ export CONTAINER_ID=$(docker container ls | grep quotes | awk ‘{print $1}’)
Maintenant, au lieu d’utiliser le nom du conteneur, nous pouvons utiliser la variable $ CONTAINER_ID dans notre expression :
$ docker container stop $CONTAINER_ID
Une fois que nous avons arrêté le conteneur, son statut passe à Exited.
Si un conteneur est arrêté, il peut être redémarré à l’aide de la commande docker container start. Faisons-le avec notre conteneur de devis. Il est bon de le relancer, car nous en aurons besoin dans les sections suivantes de ce chapitre :
$ docker container start quotes
Retrait des conteneurs
Lorsque nous exécutons la commande docker container ls -a , nous pouvons voir un bon nombre de conteneurs qui ont le statut Exited . Si nous n’avons plus besoin de ces conteneurs, alors c’est une bonne chose de les supprimer de la mémoire, sinon ils occupent inutilement de précieuses ressources. La commande pour supprimer un conteneur est :
$ docker container rm <container ID>
Une autre commande pour supprimer un conteneur est :
$ docker container rm <container name>
Essayez de supprimer l’un de vos conteneurs sortis à l’aide de son ID.
Parfois, la suppression d’un conteneur ne fonctionnera pas car il est toujours en cours d’exécution. Si nous voulons forcer une suppression, quelle que soit la condition actuelle du conteneur, nous pouvons utiliser le paramètre de ligne de commande -f ou –force.
Inspection des conteneurs
Les conteneurs sont des instances d’exécution d’une image et ont beaucoup de données associées qui caractérisent leur comportement. Pour obtenir plus d’informations sur un conteneur spécifique, nous pouvons utiliser la commande inspect. Comme d’habitude, nous devons fournir l’ID ou le nom du conteneur pour identifier le conteneur dont nous voulons obtenir les données. Alors, inspectons notre conteneur d’échantillons :
$ docker container inspect quotes
La réponse est un gros objet JSON plein de détails. Cela ressemble à ceci:
[
{
“Id”: “c5c1c68c87…”,
“Created”: “2017-12-30T11:55:51.223271182Z”,
“Path”: “/bin/sh”,
“Args”: [
“-c”,
“while :; do wget -qO- https://talaikis.com/api/ quotes/random; printf ‘\n’; sleep 5; done”
],
“State”: {
“Status”: “running”,
“Running”: true, …
},
“Image”: “sha256:e21c333399e0…”, …
“Mounts”: [],
“Config”: {
“Hostname”: “c5c1c68c87dd”,
“Domainname”: “”, …
},
“NetworkSettings”: {
“Bridge”: “”,
“SandboxID”: “2fd6c43b6fe5…”, …
}
}
]
La sortie a été raccourcie pour plus de lisibilité.
Veuillez prendre un moment pour analyser ce que vous avez obtenu. Vous devriez voir des informations telles que :
- L’ID du conteneur
- La date et l’heure de création du conteneur
- À partir de quelle image le conteneur est construit et ainsi de suite
De nombreuses sections de la sortie, telles que Mounts ou NetworkSettings, n’ont pas beaucoup de sens pour le moment, mais nous en discuterons certainement dans les prochains chapitres de l’article. Les données que vous voyez ici sont également nommées les métadonnées d’un conteneur. Nous utiliserons la commande inspect assez souvent dans le reste de l’article comme source d’information.
Parfois, nous n’avons besoin que d’une infime partie des informations globales, et pour y parvenir, nous pouvons utiliser l’outil grep ou un filter. La première méthode n’aboutit pas toujours à la réponse attendue, alors examinons la dernière approche :
$ docker container inspect -f “{{json .State}}” quotes | jq
Le paramètre -f ou –filter est utilisé pour définir le filtre. L’expression de filtre elle-même utilise la syntaxe du modèle Go. Dans cet exemple, nous voulons uniquement voir la partie état de la sortie entière au format JSON.
Pour bien formater la sortie, nous redirigeons le résultat dans l’outil jq :
{
“Status”: “running”,
“Running”: true,
“Paused”: false,
“Restarting”: false,
“OOMKilled”: false,
“Dead”: false,
“Pid”: 6759,
“ExitCode”: 0,
“Error”: “”,
“StartedAt”: “2017-12-31T10:31:51.893299997Z”,
“FinishedAt”: “0001-01-01T00:00:00Z”
}
Exec dans un conteneur en cours d’exécution
Parfois, nous voulons exécuter un autre processus à l’intérieur d’un conteneur déjà en cours d’exécution. Une raison typique pourrait être d’essayer de déboguer un conteneur qui se comporte mal. Comment peut-on le faire ? Tout d’abord, nous devons connaître l’ID ou le nom du conteneur, puis nous pouvons définir quel processus nous voulons exécuter et comment nous voulons qu’il s’exécute. Encore une fois, nous utilisons notre conteneur de devis en cours d’exécution et nous exécutons un shell de manière interactive à l’intérieur avec la commande suivante :
$ docker container exec -i -t quotes /bin/sh
L’indicateur – i signifie que nous voulons exécuter le processus supplémentaire de manière interactive, et -t indique à Docker que nous voulons qu’il nous fournisse un TTY (un émulateur de terminal) pour la commande. Enfin, le processus que nous exécutons est / bin / sh.
Si nous exécutons la commande précédente dans notre terminal, une nouvelle invite nous sera présentée. Nous sommes maintenant dans un shell à l’intérieur du conteneur de citations. Nous pouvons facilement prouver que, par exemple, en exécutant la commande ps, qui répertoriera tous les processus en cours d’exécution dans le contexte :
# / ps
Le résultat devrait ressembler à ceci :

Liste des processus exécutés à l’intérieur du conteneur quotes
Nous pouvons clairement voir que le processus avec PID 1 est la commande que nous avons définie pour s’exécuter à l’intérieur du conteneur de citations. Le processus avec PID 1 est également appelé processus principal.
Quittez le conteneur en entrant exit à l’invite. Nous ne pouvons pas seulement exécuter des processus supplémentaires interactifs dans un conteneur. Veuillez considérer la commande suivante :
$ docker container exec quotes ps
La sortie semble évidemment très similaire à la sortie précédente :
Liste des processus exécutés à l’intérieur du conteneur quotes
Nous pouvons même exécuter des processus en tant que démon en utilisant l’indicateur -d et définir les variables d’environnement en utilisant les variables d’indicateur -e comme suit :
$ docker container exec -it \ -e MY_VAR=”Hello World” \ quotes /bin/sh # / echo $MY_VAR
Hello World
# / exit
Fixation à un conteneur en cours d’exécution
Nous pouvons utiliser la commande attach pour attacher l’entrée, la sortie et l’erreur standard de notre terminal (ou toute combinaison des trois) à un conteneur en cours d’exécution en utilisant l’ID ou le nom du conteneur. Faisons cela pour notre conteneur de devis :
$ docker container attach quotes
Dans ce cas, nous verrons toutes les cinq secondes environ une nouvelle citation apparaissant dans la sortie.
Pour quitter le récipient sans arrêter ou tuer, nous pouvons appuyer sur la combinaison de touches Ctrl + P Ctrl + Q. Cela nous détache du conteneur tout en le laissant tourner en arrière-plan. D’autre part, si nous voulons détacher et arrêter le conteneur en même temps, nous pouvons simplement appuyer sur Ctrl + C.
Lançons un autre conteneur, cette fois un serveur Web Nginx :
$ docker run -d –name nginx -p 8080:80 nginx:alpine
Ici, nous exécutons la version Alpine de Nginx en tant que démon dans un conteneur nommé nginx . Le paramètre de ligne de commande -p 8080: 80 ouvre le port 8080 sur l’hôte pour accéder au serveur Web Nginx exécuté à l’intérieur du conteneur. Ne vous inquiétez pas de la syntaxe ici car nous expliquerons cette fonctionnalité plus en détail dans le Chapitre 7, Mise en réseau à hôte unique.
Voyons si nous pouvons accéder à Nginx, en utilisant l’outil curl et en exécutant cette commande :
$ curl -4 localhost:8080
Si tout fonctionne correctement, vous devriez être accueilli par la page d’accueil de Nginx:
<html>
<head>
<title>Welcome to nginx!</title>
<style> body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href=”http://nginx.org/”>nginx.org</a>.<br/>
Commercial support is available at
<a href=”http://nginx.com/”>nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
Maintenant, attachons notre terminal au conteneur nginx pour observer ce qui se passe :
$ docker container attach nginx
Une fois que vous êtes attaché au conteneur, vous ne verrez d’abord rien. Mais maintenant, ouvrez un autre terminal et, dans cette nouvelle fenêtre de terminal, répétez la commande curl plusieurs fois en utilisant le script suivant :
$ for n in {1..10}; do curl -4 localhost:8080; done
Vous devriez voir la sortie de journalisation de Nginx, qui ressemble à ceci :
172.17.0.1 – – [06/Jan/2018:12:20:00 +0000] “GET / HTTP/1.1” 200 612 “-” “curl/7.54.0” “-“
172.17.0.1 – – [06/Jan/2018:12:20:03 +0000] “GET / HTTP/1.1” 200 612 “-” “curl/7.54.0” “-“
172.17.0.1 – – [06/Jan/2018:12:20:05 +0000] “GET / HTTP/1.1” 200 612 “-” “curl/7.54.0” “-“
Quitter le conteneur en appuyant sur Ctrl + C. Cela détachera votre terminal et, en même temps, arrêtera le conteneur nginx.
Pour nettoyer, supprimez le conteneur nginx avec la commande suivante :
$ docker container rm nginx
Récupération des journaux des conteneurs
Il est recommandé pour toute bonne application de générer des informations de journalisation que les développeurs et les opérateurs peuvent utiliser pour savoir ce que fait l’application à un moment donné et s’il existe des problèmes pour aider à identifier la cause première du problème.
Lors de l’exécution à l’intérieur d’un conteneur, l’application doit de préférence afficher les éléments de journal vers STDOUT et STDERR et non dans un fichier. Si la sortie de journalisation est dirigée vers STDOUT et STDERR, Docker peut collecter ces informations et les garder prêtes à être consommées par un utilisateur ou tout autre système externe.
Pour accéder aux journaux d’un conteneur donné, nous pouvons utiliser la commande docker container logs. Si, par exemple, nous voulons récupérer les journaux de notre conteneur de devis, nous pouvons utiliser l’expression suivante :
$ docker container logs quotes
Cela permettra de récupérer l’intégralité du journal produit par l’application depuis le tout début de son existence.
Arrêtez, attendez une seconde – ce n’est pas tout à fait vrai, ce que je viens de dire, que le journal complet, depuis le début de l’existence des conteneurs est disponible. Par défaut, Docker utilise le soi-disant pilote de journalisation des fichiers json. Ce pilote stocke les informations de journalisation dans un fichier. Et si une stratégie de roulement de fichiers est définie, les journaux du conteneur Docker ne récupèrent que ce qui se trouve dans le fichier journal actif actuel et non ce qui se trouve dans les fichiers roulés précédents qui pourraient toujours ou non être disponibles sur l’hôte.
Si nous ne voulons obtenir que quelques-unes des dernières entrées, nous pouvons utiliser le paramètre -t ou –tail , comme suit:
$ docker container logs –tail 5 quotes
Cela ne récupérera que les cinq derniers éléments générés par le processus à l’intérieur du conteneur.
Parfois, nous voulons suivre le journal produit par un conteneur. Ceci est possible lorsque vous utilisez le paramètre -f ou –follow. L’expression suivante affichera les cinq derniers éléments du journal, puis suivra le journal tel qu’il est produit par le processus conteneurisé :
$ docker container logs –tail 5 –follow quotes
Journalisation des pilotes
Docker inclut plusieurs mécanismes de journalisation pour nous aider à obtenir des informations sur les conteneurs en cours d’exécution. Ces mécanismes sont appelés pilotes de journalisation. Le pilote de journalisation utilisé peut être configuré au niveau du démon Docker. Le pilote de journalisation par défaut est json-file. Certains des pilotes actuellement pris en charge nativement sont les suivants :
| Driver | Description |
| none | No log output for the specific container is produced. |
| json-file | This is the default driver. The logging information is stored in files, formatted as JSON. |
| journald | If the journals daemon is running on the host machine, we can use this driver. It forwards logging to the journald daemon. |
| syslog | If the syslog daemon is running on the host machine, we can configure this driver, which will forward the log messages to the syslog daemon. |
| gelf | When using this driver, log messages are written to a Graylog Extended Log Format (GELF) endpoint. Popular examples of such endpoints are Graylog and Logstash. |
| fluentd | Assuming that the fluentd daemon is installed on the host system, this driver writes log messages to it. |
Si vous modifiez le pilote de journalisation, sachez que la commande docker container logs n’est disponible que pour les pilotes json-file et journald.
Utilisation d’un pilote de journalisation spécifique au conteneur
Nous avons vu que le pilote de journalisation peut être défini globalement dans le fichier de configuration du démon Docker. Mais nous pouvons également définir le pilote de journalisation conteneur par conteneur. Dans l’exemple suivant, nous exécutons un conteneur busybox et utilisons le paramètre –log-driver pour configurer le pilote de journalisation none :
$ docker container run –name test -it \
–log-driver none \
busybox sh -c ‘for N in 1 2 3; do echo “Hello $N”; done’
Nous devrions voir ce qui suit :
Hello 1
Hello 2
Hello 3
Maintenant, essayons d’obtenir les journaux du conteneur précédent :
$ docker container logs test
La sortie est la suivante :
Error response from daemon: configured logging driver does not support reading
Cela est normal, car le pilote none ne produit aucune sortie de journalisation. Nettoyons et retirons le conteneur de test :
$ docker container rm test
Rubrique avancée – modification du pilote de journalisation par défaut
Modifions le pilote de journalisation par défaut d’un hôte Linux. La façon la plus simple de le faire est sur un véritable hôte Linux. Pour cela, nous allons utiliser Vagrant avec une image Ubuntu :
$ vagrant init bento/ubuntu-17.04
$ vagrant up $ vagrant ssh
Une fois à l’intérieur de la machine virtuelle Ubuntu, nous voulons modifier le fichier de configuration du démon Docker. Accédez au dossier / etc / docker et exécutez vi comme suit :
$ vi daemon.json
Saisissez le contenu suivant :
{
“Log-driver”: “json-log”,
“log-opts”: {
“max-size”: “10m”,
“max-file”: 3
}
}
Enregistrez et quittez Vi en appuyant d’abord sur Échap, puis en tapant : w: q et enfin en appuyant sur la touche Entrée.
La définition précédente indique au démon Docker d’utiliser le pilote json-log avec une taille de fichier journal maximale de 10 Mo avant qu’il ne soit déployé, et le nombre maximal de fichiers journaux pouvant être présents sur le système est de 3 avant que le fichier le plus ancien ne soit purgé.
Nous devons maintenant envoyer un signal SIGHUP au démon Docker pour qu’il récupère les modifications dans le fichier de configuration :
$ sudo kill -SIGHUP $(pidof dockerd)
Notez que la commande précédente recharge uniquement le fichier de configuration et ne redémarre pas le démon.
Anatomie des conteneurs
De nombreuses personnes comparent à tort les conteneurs aux machines virtuelles. Cependant, c’est une comparaison discutable. Les conteneurs ne sont pas seulement des machines virtuelles légères. OK alors, quelle est la description correcte d’un conteneur ?
Les conteneurs sont des processus encapsulés et sécurisés spécialement exécutés sur le système hôte.
Les conteneurs exploitent de nombreuses fonctionnalités et primitives disponibles dans le système d’exploitation Linux. Les plus importants sont les espaces de noms et les groupes de contrôle. Tous les processus s’exécutant dans des conteneurs partagent le même noyau Linux du système d’exploitation hôte sous-jacent. Ceci est fondamentalement différent des machines virtuelles, car chaque machine virtuelle contient son propre système d’exploitation complet.
Les temps de démarrage d’un conteneur typique peuvent être mesurés en millisecondes, tandis qu’une machine virtuelle a normalement besoin de plusieurs secondes à quelques minutes pour démarrer. Les machines virtuelles sont conçues pour durer longtemps. L’objectif principal de chaque ingénieur d’exploitation est de maximiser la disponibilité de leurs machines virtuelles. Contrairement à cela, les conteneurs sont censés être éphémères. Ils vont et viennent dans une cadence rapide.
Voyons d’abord un aperçu de haut niveau de l’architecture qui nous permet d’exécuter des conteneurs.
Architecture
Sur la partie inférieure du la figure précédente, nous avons le système d’exploitation Linux avec ses groupes de contrôle, et les capacités namespaces de la couche ainsi que d’autres fonctionnalités que nous ne devons mentionner explicitement ici. Ensuite, il y a une couche intermédiaire composée de containerd et runc. En plus de tout cela se trouve maintenant le moteur Docker. Le moteur Docker offre une interface RESTful au monde extérieur accessible par n’importe quel outil, comme la CLI Docker, Docker pour Mac et Docker pour Windows ou Kubernetes pour n’en nommer que quelques-uns.
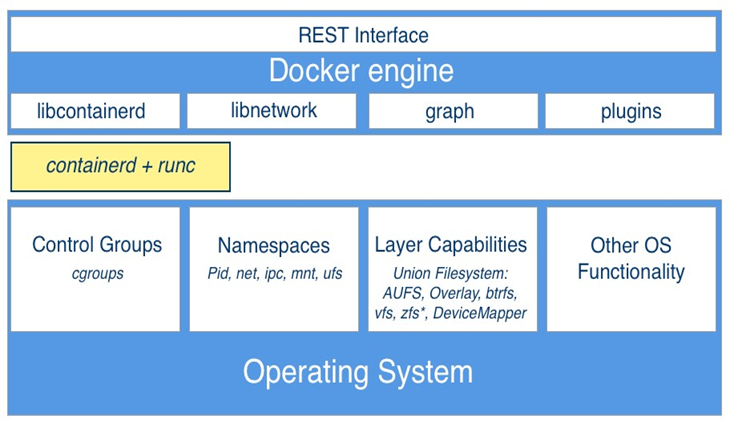
Architecture de haut niveau de Docker
Décrivons maintenant les blocs de construction principaux avec un peu plus de détails.
Espaces de noms
Les espaces de noms Linux existaient depuis des années avant d’être exploités par Docker pour leurs conteneurs. Un espace de noms est une abstraction de ressources globales telles que les systèmes de fichiers, l’accès au réseau, l’arborescence des processus (également nommée espace de noms PID) ou les ID de groupe système et les ID utilisateur. Un système Linux est initialisé avec une seule instance de chaque type d’espace de noms. Après l’initialisation, des espaces de noms supplémentaires peuvent être créés ou joints.
Les espaces de noms Linux sont nés en 2002 dans le noyau 2.4.19. Dans la version 3.8 du noyau, les espaces de noms des utilisateurs ont été introduits et avec eux, les espaces de noms étaient prêts à être utilisés par les conteneurs.
Si nous encapsulons un processus en cours, par exemple, dans un espace de noms de système de fichiers, alors ce processus a l’illusion qu’il possède son propre système de fichiers complet. Ce n’est bien sûr pas vrai ; ce n’est qu’un FS virtuel. Du point de vue de l’hôte, le processus contenu obtient une sous-section blindée de la FS globale. Il est comme un système de fichiers dans un système de fichiers :
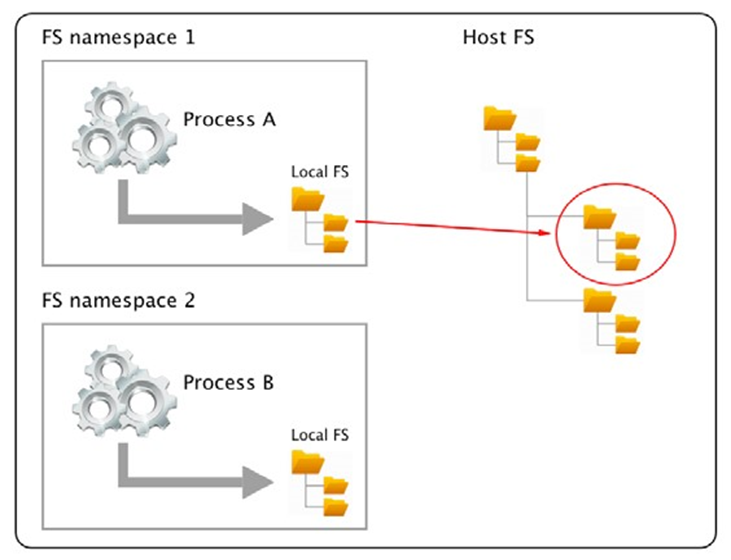
Il en va de même pour toutes les autres ressources globales pour lesquelles des espaces de noms existent. L’espace de noms ID utilisateur est un autre exemple. Ayant un espace de noms utilisateur, nous pouvons maintenant définir un utilisateur jdoe plusieurs fois sur le système tant qu’il vit dans son propre namespace.
L’espace de noms PID est ce qui empêche les processus d’un conteneur de voir ou d’interagir avec les processus d’un autre conteneur. Un processus pourrait avoir le PID 1 apparent à l’intérieur d’un conteneur, mais si nous l’examinons à partir du système hôte, il aurait un PID ordinaire, disons 334 :
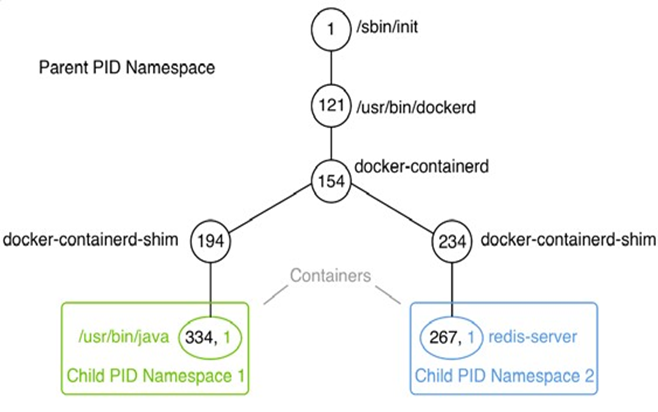
Arborescence des processus sur un hôte Docker
Dans un espace de noms donné, nous pouvons exécuter un à plusieurs processus. C’est important lorsque nous parlons de conteneurs, et nous l’avons déjà expérimenté lorsque nous avons exécuté un autre processus dans un conteneur déjà en cours d’exécution.
Groupes de contrôle (cgroups)
Les groupes de contrôle Linux sont utilisés pour limiter, gérer et isoler l’utilisation des ressources des collections de processus s’exécutant sur un système. Les ressources sont le temps CPU, la mémoire système, la bande passante réseau ou les combinaisons de ces ressources, etc.
Les ingénieurs de Google ont initialement implémenté cette fonctionnalité à partir de 2006. La fonctionnalité cgroups a été fusionnée dans la ligne principale du noyau Linux dans la version 2.6.24 du noyau, qui a été publiée en janvier 2008.
À l’aide de cgroups, les administrateurs peuvent limiter les ressources que les conteneurs peuvent consommer. Avec cela, on peut éviter, par exemple, le problème de voisin bruyant classique, où un processus voyou s’exécutant dans un conteneur consomme tout le temps CPU ou réserve d’énormes quantités de RAM et, en tant que tel, affame tous les autres processus exécutés sur l’hôte, que ce soit ils sont conteneurisés ou non.
Système de fichiers Union ( UnionFS )
L’UnionFS constitue l’épine dorsale de ce qu’on appelle les images de conteneurs. Nous discuterons des images de conteneurs en détail dans le chapitre suivant. Pour le moment, nous voulons simplement mieux comprendre ce qu’est un UnionFS et comment il fonctionne. UnionFS est principalement utilisé sous Linux et permet de superposer des fichiers et des répertoires de systèmes de fichiers distincts et de former ainsi un système de fichiers cohérent unique. Dans ce contexte, les systèmes de fichiers individuels sont appelés branches. Le contenu des répertoires qui ont le même chemin dans les branches fusionnées sera vu ensemble dans un seul répertoire fusionné, dans le nouveau système de fichiers virtuel. Lors de la fusion de branches, la priorité entre les branches est spécifiée. De cette façon, lorsque deux branches contiennent le même fichier, celle avec la priorité la plus élevée est vue dans le FS final.
Plomberie des conteneurs
Le sous-sol au-dessus duquel le moteur Docker est construit ; nous pouvons également l’appeler la plomberie du conteneur et est formé par les deux composants – runc et containerd .
À l’origine, Docker était construit de manière monolithique et contenait toutes les fonctionnalités nécessaires pour exécuter des conteneurs. Au fil du temps, cela est devenu trop rigide et Docker a commencé à décomposer des parties de la fonctionnalité en leurs propres composants. Runc et containerd sont deux composants importants.
Runc
Runc est un runtime de conteneur léger et portable. Il fournit une prise en charge complète des espaces de noms Linux ainsi qu’une prise en charge native de toutes les fonctionnalités de sécurité disponibles sur Linux, telles que SELinux , AppArmor , seccomp et cgroups .
Runc est un outil pour générer et exécuter des conteneurs selon la spécification OCI (Open Container Initiative). Il s’agit d’un format de configuration formellement spécifié, régi par l’Open Container Project (OCP) sous les auspices de la Linux Foundation.
Containerd
Runc est une implémentation de bas niveau d’un runtime de conteneur ; containerd s’appuie sur celui-ci et ajoute des fonctionnalités de plus haut niveau, telles que le transfert et le stockage d’images, l’exécution et la supervision de conteneurs, ainsi que des pièces jointes de réseau et de stockage. Avec cela, il gère le cycle de vie complet des conteneurs. Containerd est l’implémentation de référence des spécifications OCI et est de loin le runtime de conteneur le plus populaire et le plus utilisé.
Containerd a été donné et accepté par la CNCF en 2017. Il existe des implémentations alternatives de la spécification OCI. Certains d’entre eux sont rkt par CoreOS, CRI-O par RedHat et LXD par Linux Containers. Cependant, containerd à l’heure actuelle est de loin le runtime de conteneur le plus populaire et est le runtime par défaut de Kubernetes 1.8 ou version ultérieure et de la plateforme Docker.
Résumé
Dans ce chapitre, vous avez appris à travailler avec des conteneurs basés sur des images existantes. Nous avons montré comment exécuter, arrêter, démarrer et supprimer un conteneur. Ensuite, nous avons inspecté les métadonnées d’un conteneur, extrait les journaux de celui-ci et appris à exécuter un processus arbitraire dans un conteneur déjà en cours d’exécution. Enfin et surtout, nous avons creusé un peu plus et étudié le fonctionnement des conteneurs et les fonctionnalités du système d’exploitation Linux sous-jacent qu’ils exploitent.
Dans le chapitre suivant, vous allez découvrir ce que sont les images de conteneur et comment nous pouvons créer et partager nos propres images personnalisées. Nous discutons également des meilleures pratiques couramment utilisées lors de la création d’images personnalisées, telles que la réduction de leur taille et l’utilisation du cache d’images. Restez à l’écoute !
Questions
Pour évaluer vos progrès d’apprentissage, veuillez répondre aux questions suivantes :
1. Quels sont les états d’un conteneur ?
2. Quelle commande nous aide à découvrir ce qui fonctionne actuellement sur notre hôte ?
3. Quelle commande est utilisée pour répertorier les ID de tous les conteneurs ?
Création et gestion d’images de conteneurs
Dans le chapitre précédent, nous avons appris ce que sont les conteneurs et comment les exécuter, les arrêter, les supprimer, les répertorier et les inspecter. Nous avons extrait les informations de journalisation de certains conteneurs, exécuté d’autres processus à l’intérieur d’un conteneur déjà en cours d’exécution et finalement nous avons plongé profondément dans l’anatomie des conteneurs. Chaque fois que nous avons exécuté un conteneur, nous l’avons créé à l’aide d’une image de conteneur. Dans ce chapitre, nous allons nous familiariser avec ces images de conteneurs. Nous apprendrons en détail ce qu’ils sont, comment les créer et comment les distribuer.
Ce chapitre couvrira les sujets suivants :
- Quelles sont les images ?
- Création d’images
- Partage ou expédition d’images
Après avoir terminé ce chapitre, vous pourrez effectuer les opérations suivantes :
- Nommez trois des caractéristiques les plus importantes d’une image de conteneur
- Créez une image personnalisée en modifiant interactivement la couche de conteneur et en la validant
- Créez un Dockerfile simple à l’aide de mots clés tels que FROM, COPY, RUN, CMD et ENTRYPOINT pour générer une image personnalisée
- Exportez une image existante à l’aide de l’image Docker, enregistrez-la et importez-la dans un autre hôte Docker à l’aide de la charge d’image Docker
- Écrire un Dockerfile en deux étapes qui minimise la taille de l’image résultante en incluant uniquement les artefacts résultants (binaires) dans l’image finale
Que sont les images ?
Sous Linux, tout est un fichier. L’ensemble du système d’exploitation est essentiellement un système de fichiers avec des fichiers et des dossiers stockés sur le disque local. C’est un fait important à retenir lorsque l’on regarde ce que sont les images de conteneurs. Comme nous le verrons, une image est essentiellement une grande archive tar contenant un système de fichiers. Plus précisément, il contient un système de fichiers en couches.
Le système de fichiers en couches
Les images de conteneur sont des modèles à partir desquels les conteneurs sont créés. Ces images ne sont pas seulement un bloc monolithique, mais sont composées de plusieurs couches. Le premier calque de l’image est appelé le calque de base:
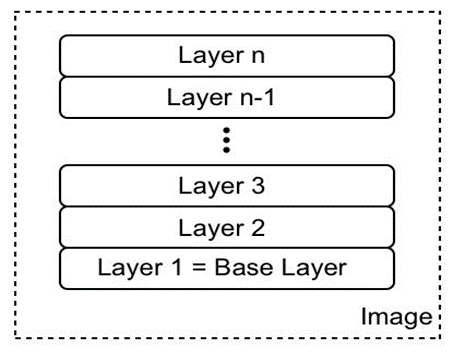
L’image comme une pile de couches
Chaque couche individuelle contient des fichiers et des dossiers. Chaque couche contient uniquement les modifications apportées au système de fichiers par rapport aux couches sous-jacentes. Docker utilise un système de fichiers union (comme expliqué au chapitre 3 , Utilisation des conteneurs) pour créer un système de fichiers virtuel à partir de l’ensemble de couches. Un pilote de stockage gère les détails concernant la façon dont ces couches interagissent les unes avec les autres. Différents pilotes de stockage sont disponibles qui présentent des avantages et des inconvénients dans différentes situations.
Les couches d’une image de conteneur sont toutes immuables. Immuable signifie qu’une fois générée, la couche ne peut plus être modifiée. La seule opération possible affectant la couche est sa suppression physique. Cette immuabilité des couches est importante car elle ouvre une énorme quantité d’opportunités, comme nous le verrons.
Dans l’image suivante, nous pouvons voir à quoi pourrait ressembler une image personnalisée pour une application Web utilisant Nginx comme serveur Web :

Un exemple d’image personnalisée basée sur Alpine et Nginx
Notre couche de base se compose ici de la distribution Alpine Linux. Ensuite, en plus de cela, nous avons une couche où Nginx est ajouté au-dessus d’Alpine. Enfin, la troisième couche contient tous les fichiers qui composent l’application Web, tels que les fichiers HTML, CSS et JavaScript.
Comme cela a été dit précédemment, chaque image commence par une image de base. En règle générale, cette image de base est l’une des images officielles trouvées sur Docker Hub, telles qu’une distribution Linux, Alpine, Ubuntu ou CentOS. Cependant, il est également possible de créer une image à partir de zéro.
Docker Hub est un registre public pour les images de conteneurs. Il s’agit d’un hub central idéal pour le partage d’images de conteneurs publics.
Chaque couche contient uniquement le delta de modifications par rapport à l’ensemble de couches précédent. Le contenu de chaque couche est mappé vers un dossier spécial sur le système hôte, qui est généralement un sous-dossier de / var / lib / docker /.
Comme les couches sont immuables, elles peuvent être mises en cache sans jamais devenir périmées. C’est un gros avantage, comme nous le verrons.
La couche contenant inscriptible
Comme nous l’avons vu, une image de conteneur est constituée d’une pile de couches immuables ou en lecture seule. Lorsque le moteur Docker crée un conteneur à partir d’une telle image, il ajoute une couche de conteneur inscriptible au-dessus de cette pile de couches immuables. Notre pile se présente maintenant comme suit :

La couche contenant inscriptible
La couche conteneur est marquée en lecture / écriture. Un autre avantage de l’immuabilité des couches d’image est qu’elles peuvent être partagées entre de nombreux conteneurs créés à partir de cette image. Tout ce qui est nécessaire est une couche de conteneur mince et inscriptible pour chaque conteneur :
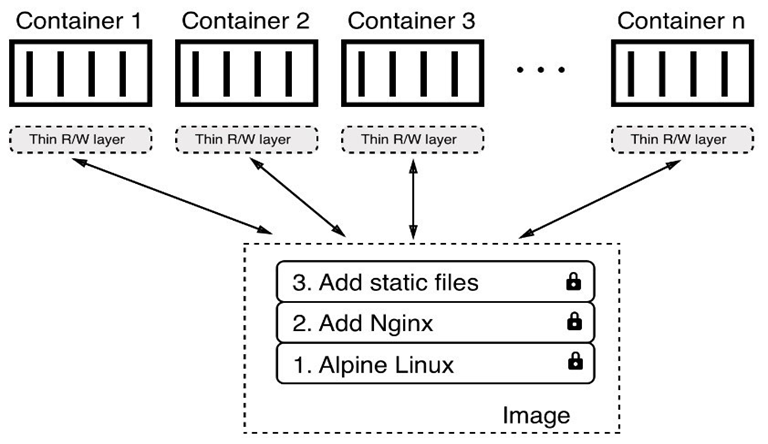
Plusieurs conteneurs partageant les mêmes couches d’image
Cette technique entraîne bien sûr une réduction considérable des ressources consommées. De plus, cela aide à réduire le temps de chargement d’un conteneur, car seule une fine couche de conteneur doit être créée une fois que les couches d’image ont été chargées en mémoire, ce qui ne se produit que pour le premier conteneur.
Copie sur écriture
Docker utilise la technique de copie sur écriture lors du traitement d’images. La copie sur écriture est une stratégie de partage et de copie de fichiers pour une efficacité maximale. Si un calque utilise un fichier ou un dossier disponible dans l’un des calques de faible hauteur, il ne fait que l’utiliser. Si, en revanche, un calque souhaite modifier, par exemple, un fichier d’un calque de faible altitude, il copie d’abord ce fichier dans le calque cible, puis le modifie. Dans la figure suivante, nous pouvons voir ce que cela signifie :
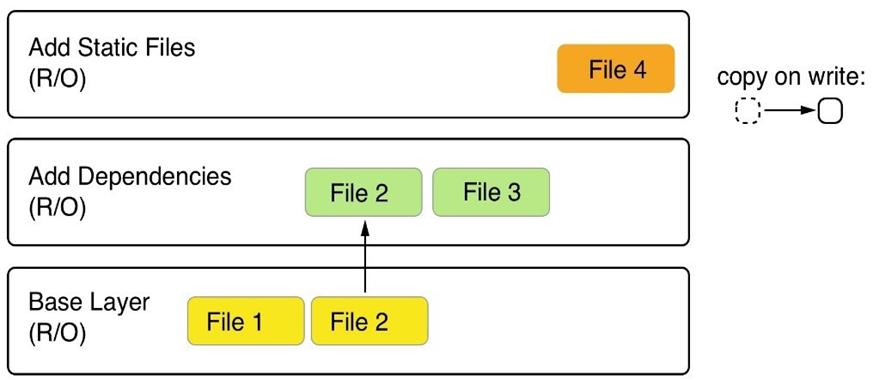
Copie sur écriture
La deuxième couche souhaite modifier le fichier 2 , qui est présent dans la couche de base. Ainsi, il l’a copié puis modifié. Maintenant, disons que nous sommes assis dans la couche supérieure de la figure précédente. Cette couche utilisera le fichier 1 de la couche de base et les fichiers 2 et 3 de la deuxième couche.
Pilotes graphiques
Les pilotes de graphes activent le système de fichiers union. Les pilotes de graphique sont également appelés pilotes de stockage et sont utilisés pour traiter les images de conteneur en couches. Un pilote graphique consolide les multiples couches d’images en un système de fichiers racine pour l’espace de noms de montage du conteneur. Ou, autrement dit, le pilote contrôle la façon dont les images et les conteneurs sont stockés et gérés sur l’hôte Docker.
Docker prend en charge plusieurs pilotes graphiques différents à l’aide d’une architecture enfichable. Le pilote préféré est overlay2 suivi d’overlay.
Création d’images
Il existe trois façons de créer une nouvelle image de conteneur sur votre système. La première consiste à créer de manière interactive un conteneur qui contient tous les ajouts et modifications souhaités, puis à valider ces modifications dans une nouvelle image. La deuxième manière, et la plus importante, consiste à utiliser un Dockerfile pour décrire le contenu de la nouvelle image, puis à créer cette image en utilisant ce Dockerfile comme manifeste. Enfin, la troisième façon de créer une image est de l’importer dans le système à partir d’une archive tar.
Maintenant, regardons ces trois façons en détail.
Création d’image interactive
La première façon de créer une image personnalisée est de créer un conteneur de manière interactive. Autrement dit, nous commençons avec une image de base que nous voulons utiliser comme modèle et exécutons un conteneur de celui-ci de manière interactive. Disons que c’est l’image alpine. La commande pour exécuter le conteneur serait alors la suivante :
$ docker container run -it –name sample alpine /bin/sh
Par défaut, le conteneur alpin n’a pas l’outil ping installé. Supposons que nous voulons créer une nouvelle image personnalisée sur laquelle ping est installé. À l’intérieur du conteneur, nous pouvons ensuite exécuter la commande suivante :
/ # apk update && apk add iputils
Cela utilise le gestionnaire de paquets Alpine apk pour installer la bibliothèque iputils , dont ping fait partie. La sortie de la commande précédente doit ressembler à ceci :
fetch http://dl-cdn.alpinelinux.org/alpine/v3.7/main/x86_64/APKINDEX. tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.7/community/x86_64/
APKINDEX.tar.gz
v3.7.0-50-gc8da5122a4 [http://dl-cdn.alpinelinux.org/alpine/v3.7/main] v3.7.0-49-g06d6ae04c3 [http://dl-cdn.alpinelinux.org/alpine/v3.7/ community]
OK: 9046 distinct packages available
(1/2) Installing libcap (2.25-r1)
(2/2) Installing iputils (20121221-r8)
Executing busybox-1.27.2-r6.trigger
OK: 4 MiB in 13 packages
Now, we can indeed use ping, as the following snippet shows:
/ # ping 127.0.0.1 PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.028 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.044 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.049 ms
^C
— 127.0.0.1 ping statistics —
3 packets transmitted, 3 received, 0% packet loss, time 2108ms rtt min/avg/max/mdev = 0.028/0.040/0.049/0.010 ms
Une fois que nous avons terminé notre personnalisation, nous pouvons quitter le conteneur en tapant exit à l’invite. Si nous répertorions maintenant tous les conteneurs avec le conteneur docker ls -a , nous pouvons voir que notre exemple de conteneur a le statut Exited , mais existe toujours sur le système:
$ docker container ls -a | grep sample
eff7c92a1b98 alpine “/bin/sh” 2 minutes ago Exited (0) …
Si nous voulons voir ce qui a changé dans notre conteneur par rapport à l’image de base, nous pouvons utiliser la commande diff docker container comme suit :
$ docker container diff sample
La sortie doit présenter une liste de toutes les modifications effectuées sur le système de fichiers du conteneur :
C /bin
C /bin/ping
C /bin/ping6
A /bin/traceroute6
C /etc/apk
C /etc/apk/world
C /lib/apk/db
C /lib/apk/db/installed
C /lib/apk/db/lock
C /lib/apk/db/scripts.tar
C /lib/apk/db/triggers
C /root
A /root/.ash_history
C /usr/lib
A /usr/lib/libcap.so.2
A /usr/lib/libcap.so.2.25
C /usr/sbin
C /usr/sbin/arping
A /usr/sbin/capsh
A /usr/sbin/clockdiff
A /usr/sbin/getcap
A /usr/sbin/getpcaps
A /usr/sbin/ipg
A /usr/sbin/rarpd
A /usr/sbin/rdisc
A /usr/sbin/setcap
A /usr/sbin/tftpd
A /usr/sbin/tracepath
A /usr/sbin/tracepath6
C /var/cache/apk
A /var/cache/apk/APKINDEX.5022a8a2.tar.gz
A /var/cache/apk/APKINDEX.70c88391.tar.gz
C /var/cache/misc
Dans la liste précédente, A signifie ajouté, et C pour changer. Si nous avions des fichiers supprimés, alors celles -ci seraient préfixé par D.
Nous pouvons maintenant utiliser la commande docker container commit pour conserver nos modifications et en créer une nouvelle image :
$ docker container commit sample my-alpinesha256:44bca4141130ee8702e8e8efd1beb3cf4fe5aadb62a0c69a6995afd49c 2e7419
Avec la commande précédente, nous avons spécifié que la nouvelle image sera appelée my-alpine . La sortie générée par la commande précédente correspond à l’ID de la nouvelle image générée. Nous pouvons le vérifier en répertoriant toutes les images sur notre système, comme suit :
$ docker image ls
Nous pouvons voir cet ID d’image (raccourci) comme suit :
REPOSITORY TAG IMAGE ID CREATED SIZE
my-alpine latest 44bca4141130 About a minute ago 5.64MB …
Nous pouvons voir que l’image nommée my-alpine, a l’ID attendu de 44bca4141130 et a automatiquement une dernière étiquette attribuée. Cela se produit car nous n’avons pas défini explicitement de balise nous-mêmes. Dans ce cas, Docker utilise toujours par défaut la dernière balise.
Si nous voulons voir comment notre image personnalisée a été construite, nous pouvons utiliser la commande historique comme suit :
$ docker image history my-alpine
Cela imprimera la liste des couches de notre image se compose de :
IMAGE CREATED CREATED BY SIZE COMMENT
44bca4141130 3 minutes ago /bin/sh 1.5MB
e21c333399e0 6 weeks ago /bin/sh -c #… 0B
<missing> 6 weeks ago /bin/sh -c #… 4.14MB
La première couche de la liste précédente est celle que nous venons de créer en ajoutant le package iputils.
Utilisation de Dockerfiles
La création manuelle d’images personnalisées, comme indiqué dans la section précédente de ce chapitre, est très utile lors de l’exploration, de la création de prototypes ou de la réalisation d’études de faisabilité. Mais il présente un sérieux inconvénient : il s’agit d’un processus manuel et n’est donc pas reproductible ou évolutif. Elle est également sujette aux erreurs comme toute tâche exécutée manuellement par des humains. Il doit y avoir un meilleur moyen.
C’est là que le soi-disant Dockerfile entre en jeu. Le Dockerfile est un fichier texte qui est généralement appelé littéralement Dockerfile. Il contient des instructions sur la façon de créer une image de conteneur personnalisée. C’est une manière déclarative de construire des images.
Déclaratif versus impératif
En informatique, en général et avec Docker en particulier, on utilise souvent une manière déclarative de définir une tâche. L’un décrit le résultat escompté et permet au système de comprendre comment atteindre cet objectif, plutôt que de donner des instructions pas à pas au système sur la manière d’atteindre ce résultat souhaité. Cette dernière est l’approche impérative.
Regardons un exemple de Dockerfile :
FROM python:2.7
RUN mkdir -p /app
WORKDIR /app
COPY ./requirements.txt /app/
RUN pip install -r requirements.txt
CMD [“python”, “main.py”]
Il s’agit d’un Dockerfile car il est utilisé pour conteneuriser une application Python 2.7. Comme nous pouvons le voir, le fichier comporte six lignes, chacune commençant par un mot-clé tel que FROM, RUN ou COPY. C’est une convention d’écrire les mots clés en majuscules, mais ce n’est pas un must.
Chaque ligne du Dockerfile crée un calque dans l’image résultante. Dans l’image suivante, l’image est dessinée à l’envers par rapport aux illustrations précédentes de ce chapitre, montrant une image comme une pile de couches. Ici, la couche de base est représentée en haut. Ne vous laissez pas confondre par cela. En réalité, la couche de base est toujours la couche la plus basse de la pile :
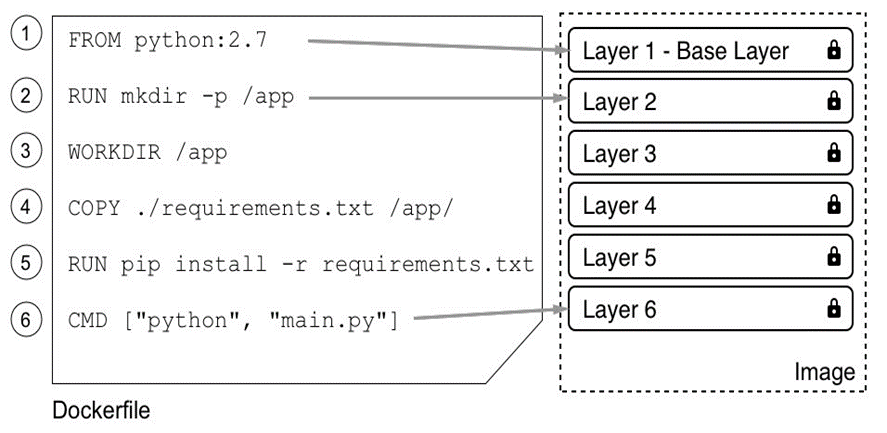
La relation entre Dockerfile et les couches dans une image
Examinons maintenant les mots clés individuels plus en détail.
Le mot clé FROM
La plupart des Dockerfiles commencent par le mot clé FROM. Avec lui, nous définissons à partir de quelle image de base nous voulons commencer à construire notre image personnalisée. Si nous voulons construire à partir de CentOS 7, par exemple, nous aurions la ligne suivante dans le Dockerfile :
FROM centos:7
Sur Docker Hub, il existe des images organisées ou officielles pour toutes les principales distributions Linux, ainsi que pour tous les cadres de développement ou langages importants, tels que Python, Node JS, Ruby, Go et bien d’autres. En fonction de nos besoins, nous devons sélectionner l’image de base la plus appropriée.
Par exemple, si je souhaite conteneuriser une application Python 2.7, je pourrais vouloir sélectionner l’image python: 2.7 officielle appropriée .
Si nous voulons vraiment partir de zéro, nous pouvons également utiliser la déclaration suivante :
FROM scratch
Ceci est utile dans le contexte de la construction d’images super minimales qui ne contiennent, par exemple, qu’un seul binaire, l’exécutable réel lié statiquement, tel que Hello-World. L’image à gratter est littéralement une image de base vide.
FROM scratch correspond à un no-op (aucune opération) dans le Dockerfile et, en tant que tel, ne génère pas de couche dans l’image de conteneur résultante.
Le mot clé RUN
Le prochain mot clé important est RUN. L’argument pour RUN est n’importe quelle commande Linux valide, telle que la suivante :
RUN yum install -y wget
La commande précédente utilise le gestionnaire de packages CentOS yum pour installer le package wget dans le conteneur en cours d’exécution. Cela suppose que notre image de base est CentOS ou RHEL. Si nous avions Ubuntu comme image de base, la commande ressemblerait à ceci :
RUN apt-get update && apt-get install -y wget
Cela ressemblerait à cela car Ubuntu utilise apt-get comme gestionnaire de packages. De même, nous pourrions définir une ligne avec RUN comme ceci :
RUN mkdir -p /app && cd /app
On pourrait aussi faire ça :
RUN tar -xJC /usr/src/python –strip-components=1 -f python.tar.xz
Ici, le premier crée un dossier / app dans le conteneur et y accède, et le dernier décompresse un fichier vers un emplacement donné. Il est tout à fait correct, et même recommandé, de formater une commande Linux en utilisant plusieurs lignes physiques, comme celle-ci :
RUN apt-get update \
&& apt-get install -y –no-install-recommends \
ca-certificates \
libexpat1 \
libffi6 \
libgdbm3 \
libreadline7 \
libsqlite3-0 \
libssl1.1 \
&& rm -rf /var/lib/apt/lists/*
Si nous utilisons plus d’une ligne, nous devons mettre une barre oblique inverse ( \ ) à la fin des lignes pour indiquer au shell que la commande continue sur la ligne suivante.
Essayez de savoir ce que fait la commande précédente.
Les mots-clés COPY et ADD
Les mots clés COPY et ADD sont très importants car, au final, nous voulons ajouter du contenu à une image de base existante pour en faire une image personnalisée. La plupart du temps, il s’agit de quelques fichiers source, disons, d’une application Web ou de quelques fichiers binaires d’une application compilée.
Ces deux mots clés sont utilisés pour copier des fichiers et des dossiers de l’hôte dans l’image que nous construisons. Les deux mots clés sont très similaires, à l’exception du fait que le mot clé ADD nous permet également de copier et de décompresser les fichiers TAR, ainsi que de fournir une URL comme source pour les fichiers et dossiers à copier.
Examinons quelques exemples d’utilisation de ces deux mots clés :
COPY . /app
COPY ./web /app/web
COPY sample.txt /data/my-sample.txt
ADD sample.tar /app/bin/
ADD http://example.com/sample.txt /data/
Dans les lignes de code précédentes :
- La première ligne copie récursivement tous les fichiers et dossiers du répertoire actuel dans le dossier / app à l’intérieur de l’image du conteneur
- La deuxième ligne copie tout dans le sous-dossier Web dans le dossier cible, / app / web
- La troisième ligne copie un seul fichier, sample.txt, dans le dossier cible, / data, et en même temps, le renomme my-sample.txt
- La quatrième instruction décompresse le fichier sample.tar dans le dossier cible, / app / bin
- Enfin, la dernière instruction copie le fichier distant, sample.txt, dans le fichier cible, / data
Les caractères génériques sont autorisés dans le chemin source. Par exemple, l’instruction suivante copie tous les fichiers commençant par sample dans le dossier mydir à l’intérieur de l’image :
COPY ./sample* /mydir/
Du point de vue de la sécurité, il est important de savoir que par défaut, tous les fichiers et dossiers à l’intérieur de l’image auront un ID utilisateur (UID) et un ID de groupe (GID) de 0. La bonne chose est que pour ADD et COPY, nous pouvons changer la propriété que les fichiers auront à l’intérieur de l’image en utilisant le drapeau optionnel – chown , comme suit:
ADD –chown=11:22 ./data/files* /app/data/
L’instruction précédente copiera tous les fichiers commençant par le nom web et les placera dans le dossier / app / data de l’image, et affectera en même temps l’utilisateur 11 et le groupe 22 à ces fichiers.
Au lieu de nombres, on pourrait également utiliser des noms pour l’utilisateur et le groupe, mais alors ces entités devraient être déjà définies dans le système de fichiers racine de l’image dans / etc / passwd et / etc / group respectivement, sinon la construction de l’image échouerait.
Le mot clé WORKDIR
Le mot clé WORKDIR définit le répertoire de travail ou le contexte utilisé lorsqu’un conteneur est exécuté à partir de notre image personnalisée. Donc, si je veux définir le contexte dans le dossier / app / bin à l’intérieur de l’image, mon expression dans le Dockerfile devrait ressembler à ceci :
WORKDIR /app/bin
Toute activité qui se produit à l’intérieur de l’image après la ligne précédente utilisera ce répertoire comme répertoire de travail. Il est très important de noter que les deux extraits suivants d’un Dockerfile ne sont pas identiques :
RUN cd /app/bin
RUN touch sample.txt
Comparez le code précédent avec le code suivant :
WORKDIR /app/bin
RUN touch sample.txt
Le premier créera le fichier à la racine du système de fichiers image, tandis que le second créera le fichier à l’emplacement attendu dans le dossier /app/bin. Seul le mot clé WORKDIR définit le contexte sur les couches de l’image. La commande cd seule n’est pas persistante sur les couches.
Les mots-clés CMD et ENTRYPOINT
Les mots clés CMD et ENTRYPOINT sont spéciaux. Alors que tous les autres mots clés définis pour un Dockerfile sont exécutés au moment où l’image est construite par le générateur Docker, ces deux sont en fait des définitions de ce qui se passera lorsqu’un conteneur est démarré à partir de l’image que nous définissons. Lorsque le runtime du conteneur démarre un conteneur, il doit savoir quel sera le processus ou l’application qui doit s’exécuter à l’intérieur de ce conteneur. C’est exactement pour cela que CMD et ENTRYPOINT sont utilisés – pour indiquer à Docker quel est le processus de démarrage et comment le démarrer.
Maintenant, les différences entre CMD et ENTRYPOINT sont subtiles, et honnêtement, la plupart des utilisateurs ne les comprennent pas complètement ou ne les utilisent pas de la manière prévue. Heureusement, dans la plupart des cas, ce n’est pas un problème et le conteneur fonctionnera de toute façon ; c’est juste sa manipulation qui n’est pas aussi simple qu’elle pourrait l’être.
Pour mieux comprendre comment utiliser les deux mots clés, analysons à quoi ressemble une commande ou une expression Linux typique, par exemple, prenons l’utilitaire ping comme exemple, comme suit :
$ ping 8.8.8.8 -c 3
Dans l’expression précédente, ping est la commande et 8.8.8.8 -c 3 sont les paramètres de cette commande. Regardons une autre expression :
$ wget -O – http://example.com/downloads/script.sh
Encore une fois, dans l’expression précédente, wget est la commande et -O – http://example.com/downloads/script.sh sont les paramètres.
Maintenant que nous avons réglé cela, nous pouvons revenir à CMD et ENTRYPOINT. ENTRYPOINT est utilisé pour définir la commande de l’expression tandis que CMD est utilisé pour définir les paramètres de la commande. Ainsi, un Dockerfile utilisant alpine comme image de base et définissant ping comme processus à exécuter dans le conteneur pourrait ressembler à ceci:
FROM alpine:latest
ENTRYPOINT [“ping”]
CMD [“8.8.8.8”, “-c”, “3”]
Pour ENTRYPOINT et CMD, les valeurs sont formatées sous la forme d’un tableau JSON de chaînes, où les éléments individuels correspondent aux jetons de l’expression qui sont séparés par des espaces. C’est le moyen préféré de définir CMD et ENTRYPOINT. Il est également appelé formulaire exec.
Alternativement, on peut également utiliser ce qu’on appelle le formulaire shell, par exemple :
CMD command param1 param2
Nous pouvons maintenant créer une image à partir du Dockerfile précédent, comme suit :
$ docker image build -t pinger .
Ensuite, nous pouvons exécuter un conteneur à partir de l’image de pinger que nous venons de créer:
$ docker container run –rm -it pinger
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: seq=0 ttl=37 time=19.298 ms
64 bytes from 8.8.8.8: seq=1 ttl=37 time=27.890 ms
64 bytes from 8.8.8.8: seq=2 ttl=37 time=30.702 ms
La beauté de ceci est que je peux maintenant remplacer la partie CMD que j’ai défini dans le Dockerfile (rappelez-vous, c’était [“8.8.8.8”, “-c”, “3”]) lorsque je crée un nouveau conteneur en ajoutant les nouvelles valeurs à la fin de l’expression d’exécution du conteneur Docker :
$ docker container run –rm -it pinger -w 5 127.0.0.1
Cela entraînera maintenant le conteneur de ping sur le bouclage pendant 5 secondes.
Si nous voulons remplacer ce qui est défini dans ENTRYPOINT dans le Dockerfile, nous devons utiliser le paramètre – entrypoint dans l’expression d’exécution du conteneur de docker. Disons que nous voulons exécuter un shell dans le conteneur au lieu de la commande ping. Nous pourrions le faire en utilisant la commande suivante :
$ docker container run –rm -it –entrypoint /bin/sh pinger
Nous nous retrouverons alors à l’intérieur du conteneur. Tapez exit pour quitter le conteneur.
Comme je l’ai déjà mentionné, nous ne devons pas nécessairement suivre les meilleures pratiques et définir la commande via ENTRYPOINT et les paramètres via CMD, mais nous pouvons plutôt saisir l’expression entière en tant que valeur de CMD et cela fonctionnera :
FROM alpine:latest
CMD wget -O – http://www.google.com
Ici, j’ai même utilisé le formulaire shell pour définir le CMD. Mais que se passe-t-il vraiment dans cette situation où ENTRYPOINT n’est pas défini ? Si vous laissez ENTRYPOINT indéfini, alors il aura la valeur par défaut de / bin / sh -c, et quelle que soit la valeur de CMD sera passée sous forme de chaîne à la commande shell. La définition précédente entraînerait ainsi la saisie du processus suivant pour s’exécuter à l’intérieur du conteneur :
/bin/sh -c “wget -O – http://www.google.com”
Par conséquent, / bin / sh est le processus principal en cours d’exécution à l’intérieur du conteneur, et il démarrera un nouveau processus enfant pour exécuter l’utilitaire wget.
Un Dockerfile complexe
Nous avons discuté des mots clés les plus importants couramment utilisés dans les Dockerfiles . Regardons un exemple réaliste et quelque peu complexe d’un Dockerfile . Le lecteur intéressé pourrait noter qu’il ressemble beaucoup au premier Dockerfile que nous avons présenté dans ce chapitre. Voici le contenu :
FROM node:9.4
RUN mkdir -p /app
WORKDIR /app
COPY package.json /app/
RUN npm install
COPY . /app
ENTRYPOINT [“npm”]
CMD [“start”]
OK, alors qu’est-ce qui se passe ici ? Évidemment, il s’agit d’un Dockerfile qui est utilisé pour créer une image pour une application Node.js ; nous pouvons déduire cela du fait que le nœud d’image de base : 9.4 est utilisé. Ensuite, la deuxième ligne est une instruction pour créer un dossier / app dans le système de fichiers de l’image. La troisième ligne définit le répertoire de travail ou le contexte dans l’image comme étant ce nouveau dossier / app. Ensuite, à la ligne quatre, nous copions un fichier package.json dans le dossier / app à l’intérieur de l’image. Après cela, à la ligne cinq, nous exécutons la commande npm install à l’intérieur du conteneur ; rappelez-vous, notre contexte est le dossier / app et donc, npm y trouvera le fichier package.json que nous avons copié à la ligne quatre.
Une fois toutes les dépendances Node.js installées, nous copions le reste des fichiers d’application du dossier actuel de l’hôte dans le dossier / app de l’image.
Enfin, sur les deux dernières lignes, nous définissons ce que doit être la commande de démarrage lorsqu’un conteneur est exécuté à partir de cette image. Dans notre cas, c’est npm start, qui lancera l’application Node.
Construire une image
Suivez les étapes ci-dessous pour créer une image :
1. Dans votre maison répertoire, créez un FundamentalsOfDocker dossier et parcourir l’itinéraire :
$ mkdir ~/FundamentalsOfDocker
$ cd ~/FundamentalsOfDocker
2. Dans le dossier précédent, créez un sous-dossier sample1 et accédez-y: $ mkdir sample1 && cd sample1
3. Utilisez votre éditeur préféré pour créer un fichier appelé Dockerfile dans cet exemple de dossier avec le contenu suivant :
FROM centos:7
RUN yum install -y wget
4. Enregistrez le fichier et quittez votre éditeur. De retour dans le terminal, nous pouvons maintenant créer une nouvelle image de conteneur en utilisant le Dockerfile précédent comme manifeste ou plan de construction :
$ docker image build -t my-centos .
Veuillez noter qu’il y a un point à la fin de la commande précédente. Cette commande signifie que le générateur Docker crée une nouvelle image appelée my-centos à l’aide du Dockerfile présent dans le répertoire actuel. Ici, le point à la fin de la commande représente le répertoire courant. Nous pourrions également écrire la commande précédente comme suit, avec le même résultat :
$ docker image build -t my-centos -f Dockerfile .
Mais nous pouvons omettre le paramètre -f, car le générateur suppose que le Dockerfile est littéralement appelé Dockerfile. Nous n’avons besoin du paramètre -f que si notre Dockerfile a un nom différent ou n’est pas situé dans le répertoire courant.
La commande précédente nous donne cette sortie (raccourcie):
Sending build context to Docker daemon 2.048kB
Step 1/2 : FROM centos:7
7: Pulling from library/centos af4b0a2388c6: Pull complete
Digest: sha256:2671f7a3eea36ce43609e9fe7435ade83094291055f1c96d9d1d1d
7c0b986a5d
Status: Downloaded newer image for centos:7
—> ff426288ea90
Step 2/2 : RUN yum install -y wget
—> Running in bb726903820c
Loaded plugins: fastestmirror, ovl
Determining fastest mirrors
* base: mirror.dal10.us.leaseweb.net
* extras: repos-tx.psychz.net
* updates: pubmirrors.dal.corespace.com
Resolving Dependencies
–> Running transaction check
—> Package wget.x86_64 0:1.14-15.el7_4.1 will be installed …
Installed:
wget.x86_64 0:1.14-15.el7_4.1
Complete!
Removing intermediate container bb726903820c
—> bc070cc81b87
Successfully built bc070cc81b87
Successfully tagged my-centos:latest
Analysons cette sortie:
1. Premièrement, nous avons la ligne suivante :
Sending build context to Docker daemon 2.048kB
La première chose que fait le générateur est de regrouper les fichiers dans le contexte de génération actuel, à l’exclusion des fichiers et du dossier mentionnés dans le fichier dockerignore , s’il est présent, et envoie le fichier .tar résultant au démon Docker.
2. Ensuite, nous avons les lignes suivantes :
Step 1/2 : FROM centos:7
7: Pulling from library/centos
af4b0a2388c6: Pull complete
Digest: sha256:2671f7a…
Status: Downloaded newer image for centos:7
—> ff426288ea90
La première ligne nous indique quelle étape du Dockerfile le générateur exécute actuellement. Ici, nous n’avons que deux instructions dans le Dockerfile, et nous sommes à l’étape 1 de 2. Nous pouvons également voir quel est le contenu de cette section. Voici la déclaration de l’image de base, au-dessus de laquelle nous voulons construire notre image personnalisée. Ensuite, le générateur extrait cette image de Docker Hub si elle n’est pas déjà disponible dans le cache local. La dernière ligne de l’extrait précédent indique l’ID que la couche qui vient d’être créée est attribuée par le générateur.
3. Voici la prochaine étape. Je l’ai raccourci encore plus que le précédent pour me concentrer sur l’essentiel :
Step 2/2 : RUN yum install -y wget
—> Running in bb726903820c …
…
Removing intermediate container bb726903820c
—> bc070cc81b87
Ici encore, la première ligne nous indique que nous sommes à l’étape 2 sur 2. Elle nous montre également l’entrée respective du Dockerfile . Sur la deuxième ligne, nous pouvons voir Running in bb726903820c, qui nous indique que le générateur a créé un conteneur avec l’ID bb726903820c à l’intérieur, dans lequel il exécute la commande RUN. Nous avons omis la sortie de la commande yum install -y wget dans l’extrait de code car elle n’est pas importante dans cette section. Une fois la commande terminée, le générateur arrête le conteneur, le valide dans un nouveau calque, puis supprime le conteneur. La nouvelle couche a l’ID bc070cc81b87, dans ce cas particulier.
4. À la toute fin de la sortie, nous rencontrons les deux lignes suivantes :
Successfully built bc070cc81b87
Successfully tagged my-centos:latest
Cela nous indique que l’image personnalisée résultante a reçu l’ID bc070cc81b87 et a été étiquetée avec le nom my-centos: latest .
Alors, comment fonctionne exactement le constructeur ? Cela commence par l’image de base. À partir de cette image de base, une fois téléchargée dans le cache local, elle crée un conteneur et exécute la première instruction du Dockerfile à l’intérieur de ce conteneur. Ensuite, il arrête le conteneur et persiste les modifications apportées dans le conteneur dans une nouvelle couche d’image. Le générateur crée ensuite un nouveau conteneur à partir de l’image de base et du nouveau calque et exécute la deuxième instruction à l’intérieur de ce nouveau conteneur. Encore une fois, le résultat est enregistré dans une nouvelle couche. Ce processus est répété jusqu’à ce que la toute dernière instruction du Dockerfile soit rencontrée. Après avoir validé la dernière couche de la nouvelle image, le générateur crée un ID pour cette image et marque l’image avec le nom que nous avons fourni dans la commande de construction :

Visualisation du processus de création d’image
Constructions en plusieurs étapes
Pour montrer pourquoi un Dockerfile avec plusieurs étapes de construction est utile, faisons un exemple de Dockerfile. Prenons une application Hello World écrite en C. Voici le code trouvé dans le fichier hello.c :
#include <stdio.h> int main (void)
{
printf (“Hello, world!\n”);
return 0; }
Maintenant, nous voulons conteneuriser cette application et écrire ce Dockerfile :
RUN apk update && apk add –update alpine-sdk
RUN mkdir /app
WORKDIR /app
COPY . /app
RUN mkdir bin
RUN gcc -Wall hello.c -o bin/hello
CMD /app/bin/hello
Maintenant, construisons cette image:
$ docker image build -t hello-world .
Cela nous donne une sortie assez longue, car le constructeur doit installer le SDK Alpine, qui, entre autres outils, contient le compilateur C ++ dont nous avons besoin pour construire l’application.
Une fois la construction terminée, nous pouvons lister l’image et voir sa taille comme suit:
$ docker image ls | grep hello-world
hello-world latest e9b… 2 minutes ago 176MB
Avec une taille de 176 Mo, l’image résultante est beaucoup trop grande. Au final, ce n’est qu’une application Hello World. La raison pour laquelle il est si grand est que l’image contient non seulement le binaire Hello World, mais aussi tous les outils pour compiler et lier l’application à partir du code source. Mais ce n’est vraiment pas souhaitable lors de l’exécution de l’application, par exemple, en production. Idéalement, nous voulons seulement avoir le binaire résultant dans l’image et non un SDK entier.
C’est précisément pour cette raison que nous devons définir les Dockerfiles comme étant à plusieurs étages. Nous avons certaines étapes qui sont utilisées pour construire les artefacts finaux, puis une étape finale où nous utilisons l’image de base minimale nécessaire et copions les artefacts dedans. Il en résulte de très petites images. Jetez un œil à ce Dockerfile révisé :
FROM alpine:3.7 AS build
RUN apk update && \
apk add –update alpine-sdk
RUN mkdir /app
WORKDIR /app
COPY . /app
RUN mkdir bin
RUN gcc hello.c -o bin/hello
FROM alpine:3.7
COPY –from=build /app/bin/hello /app/hello
CMD /app/hello
Ici, nous avons une première étape avec un build d’alias qui est utilisé pour compiler l’application, puis la deuxième étape utilise la même image de base alpine : 3.7, mais n’installe pas le SDK et copie uniquement le binaire à partir de l’étape de construction, en utilisant le paramètre –from , dans cette image finale.
Reconstruisons l’image comme suit :
$ docker image build -t hello-world-small .
Lorsque nous comparons les tailles des images, nous obtenons la sortie suivante :
$ docker image ls | grep hello-world
hello-world-small latest f98… 20 seconds ago 4.16MB
hello-world latest 469… 10 minutes ago 176MB
Nous avons pu réduire la taille de 176 Mo à 4 Mo. Il s’agit d’une réduction de la taille d’un facteur de 40. Une taille d’image plus petite présente de nombreux avantages, tels qu’une surface d’attaque plus petite pour les pirates, une consommation de mémoire et de disque réduite, des temps de démarrage plus rapides des conteneurs correspondants et une réduction de la bande passante nécessaire pour télécharger l’image à partir d’un registre, tel que Docker Hub.
Meilleures pratiques Dockerfile
Il existe quelques bonnes pratiques recommandées à prendre en compte lors de la création d’un Dockerfile , qui sont les suivantes:
- N’oubliez pas que les contenants sont censés être éphémères. Par éphémère, nous voulons dire qu’un conteneur peut être arrêté et détruit et qu’un nouveau peut être construit et mis en place avec une installation et une configuration minimales absolues. Cela signifie que nous devons nous efforcer de réduire au minimum le temps nécessaire à l’initialisation de l’application en cours d’exécution à l’intérieur du conteneur, ainsi que le temps nécessaire pour terminer ou nettoyer l’application.
- Ordonnez les commandes individuelles dans le Dockerfile de manière à tirer le meilleur parti de la mise en cache. La construction d’une couche d’une image peut prendre un temps considérable, parfois un certain nombre de minutes. Lors du développement d’une application, nous devrons créer plusieurs fois l’image du conteneur pour notre application. Nous voulons garder les temps de construction au minimum.
Lorsque nous reconstruisons une image précédemment créée, les seuls calques qui sont reconstruits sont ceux qui ont changé, mais si un calque doit être reconstruit, tous les calques suivants doivent également être reconstruits. C’est très important à retenir. Prenons l’exemple suivant:
FROM node:9.4
RUN mkdir -p /app
WORKIR /app
COPY . /app
RUN npm install
CMD [“npm”, “start”]
Dans cet exemple, la commande npm install sur la ligne cinq du Dockerfile prend généralement le plus de temps. Une application Node.js classique possède de nombreuses dépendances externes, et celles-ci sont toutes téléchargées et installées à cette étape. Cela peut prendre quelques minutes jusqu’à ce qu’il soit fait. Par conséquent, nous voulons éviter d’exécuter npm install chaque fois que nous reconstruisons l’image, mais un développeur change tout le temps son code source pendant le développement de l’application. Cela signifie que la ligne quatre, résultat de la commande COPY, change tout le temps et que cette couche doit être reconstruite à chaque fois. Mais comme nous l’avons vu précédemment, cela signifie également que toutes les couches suivantes doivent être reconstruites, ce qui inclut dans ce cas la commande npm install. Pour éviter cela, nous pouvons légèrement modifier le Dockerfile et disposer des éléments suivants :
FROM node:9.4
RUN mkdir -p /app
WORKIR /app
COPY package.json /app/
RUN npm install
COPY . /app
CMD [“npm”, “start”]
Ce que nous avons fait ici, à la ligne quatre, nous n’avons copié que le fichier unique dont la commande npm install a besoin en tant que source, qui est le package fichier json. Ce fichier change rarement dans un processus de développement typique. Par conséquent, la commande npm install ne doit également être exécutée que lorsque le fichier package.json change. Tout le contenu restant, fréquemment modifié, est ajouté à l’image après la commande d’installation npm.
- Gardez le nombre de couches qui composent votre image relativement petite. Plus une image contient de couches, plus le pilote graphique doit travailler pour consolider les couches en un seul système de fichiers racine pour le conteneur correspondant. Bien sûr, cela prend du temps, et donc moins il y a de couches dans l’image, plus le temps de démarrage du conteneur peut être rapide.
Mais comment pouvons-nous maintenir notre nombre de couches bas ? N’oubliez pas que dans un Dockerfile, chaque ligne commençant par un mot clé, tel que FROM, COPY ou RUN, crée un nouveau calque. La façon la plus simple de réduire le nombre de couches est de combiner plusieurs commandes RUN individuelles en une seule, par exemple, disons que nous avions les éléments suivants dans un Dockerfile :
RUN apt-get update
RUN apt-get install -y ca-certificates
RUN rm -rf /var/lib/apt/lists/*
Nous pourrions les combiner en une seule expression concaténée, comme suit :
RUN apt-get update \
&& apt-get install -y ca-certificates \
&& rm -rf /var/lib/apt/lists/*
Le premier générera trois calques dans l’image résultante, tandis que le second ne créera qu’un seul calque.
Les trois meilleures pratiques suivantes donnent toutes des images plus petites. Pourquoi est-ce important ? Les images plus petites réduisent le temps et la bande passante nécessaires pour télécharger l’image à partir d’un registre. Ils réduisent également la quantité d’espace disque nécessaire pour stocker une copie localement sur l’hôte Docker et la mémoire nécessaire pour charger l’image. Enfin, des images plus petites signifient également une surface d’attaque plus petite pour les pirates. Voici les meilleures pratiques pour réduire la taille de l’image :
- Utilisez un fichier .dockerignore. Nous voulons éviter de copier des fichiers et des dossiers inutiles dans une image pour la garder aussi légère que possible. Le fichier dockerignore fonctionne exactement de la même manière qu’un fichier .gitignore, pour ceux qui connaissent Git. Dans un fichier .dockerignore, nous pouvons configurer des modèles pour exclure certains fichiers ou dossiers d’être inclus dans le contexte lors de la construction de l’image.
- Évitez d’installer des packages inutiles dans le système de fichiers de l’image. Encore une fois, c’est pour garder l’image aussi maigre que possible.
- Utilisez des versions à plusieurs étapes afin que l’image résultante soit aussi petite que possible et ne contienne que le minimum absolu nécessaire pour exécuter votre application ou service d’application.
Enregistrement et chargement d’images
La troisième façon de créer une nouvelle image de conteneur consiste à l’importer ou à la charger à partir d’un fichier. Une image de conteneur n’est rien de plus qu’une archive tar. Pour illustrer cela, nous pouvons utiliser la commande docker image save pour exporter une image existante vers une archive tar :
$ docker image save -o ./backup/my-alpine.tar my-alpine
La commande précédente prend notre image my-alpine que nous avons précédemment créée et l’exporte dans un fichier ./backup/my-alpine.tar.
Si, d’autre part, nous avons une archive tar existante et que nous voulons l’importer en tant qu’image dans notre système, nous pouvons utiliser la commande docker image load comme suit :
$ docker image load -i ./backup/my-alpine.tar
Partage ou expédition d’images
Pour pouvoir envoyer notre image personnalisée à d’autres environnements, nous devons d’abord lui donner un nom unique au monde. Cette action est souvent appelée marquage d’une image. Nous devons ensuite publier l’image à un emplacement central à partir duquel d’autres parties intéressées ou autorisées peuvent la retirer. Ces emplacements centraux sont appelés registres d’images.
Marquage d’une image
Chaque image a une soi-disant balise. Une balise est souvent utilisée pour versionner des images, mais elle a une portée plus large que d’être simplement un numéro de version. Si nous ne spécifions pas explicitement une balise lorsque nous travaillons avec des images, Docker suppose automatiquement que nous faisons référence à la dernière balise. Cela est pertinent lors de l’extraction d’une image à partir de Docker Hub, par exemple :
$ docker image pull alpine
La commande précédente extrait l’image alpine : dernière du hub. Si nous voulons spécifier explicitement une balise, nous le faisons comme ceci :
$ docker image pull alpine:3.5
Cela va maintenant extraire l’image alpine qui a été étiquetée avec 3.5.
Espaces de noms d’images
Jusqu’à présent, vous avez tiré diverses images et ne vous êtes pas tellement inquiété de l’origine de ces images. Votre environnement Docker est configuré pour que, par défaut, toutes les images soient extraites de Docker Hub. Nous n’avons également tiré que des images dites officielles du Docker Hub, telles qu’alpine ou busybox.
Il est maintenant temps d’élargir un peu notre horizon et d’apprendre comment les images sont espacées de noms. La façon la plus générique de définir une image est par son nom complet, qui ressemble à ceci :
<registry URL>/<User or Org>/<name>:<tag>
Examinons cela un peu plus en détail :
- <registry URL>: il s’agit de l’URL du registre à partir duquel nous voulons extraire l’image. Par défaut, c’est docker.io. Plus généralement, cela pourrait être https://registry.acme.com.
Outre Docker Hub, il existe de nombreux registres publics dont vous pouvez extraire des images. Voici une liste de certains d’entre eux, sans ordre particulier :
- ° Google sur https://cloud.google.com/container-registry
- ° Amazon AWS sur https://aws.amazon.com/ecr/
- ° Microsoft Azure sur https://azure.micros oft.com/services/container-registry/
- ° Red Hat sur https://access.redhat.com/containers/
- ° Artifactory sur https://jfrog.com/integration/artifactory docker-registry /
- <User or Org>: il s’agit de l’ID Docker privé d’un individu ou d’une organisation défini sur Docker Hub, ou tout autre registre d’ailleurs, tel que Microsoft ou Oracle .
- <name>: il s’agit du nom de l’image qui est souvent également appelée référentiel.
- <tag> : il s’agit de la balise de l’image.
Regardons un exemple :
https://registry.acme.com/engineering/web-app:1.0
Ici, nous avons une image, une application Web, qui est étiquetée avec la version 1.0 et appartient à l’organisation d’ingénierie sur le registre privé à https://registry.acme.com.
Maintenant, il existe des conventions spéciales :
- Si nous omettons l’URL du registre, Docker Hub est automatiquement pris
- Si nous omettons la balise, la dernière est prise
- S’il s’agit d’une image officielle sur Docker Hub, aucun espace de noms d’utilisateur ou d’organisation n’est nécessaire
Quelques exemples sous forme de tableau sont les suivants :
| Image | Description |
| alpine | Official alpine image on Docker Hub with the latest tag. |
| ubuntu:16.04 | Official ubuntu image on Docker Hub with the 16.04 tag or version. |
| microsoft/nanoserver | nanoserver image of Microsoft on Docker Hub with the latest tag. |
| acme/web-api:12.0 | web-api image version 12.0 associated with the acme org. The image is on Docker Hub. |
| gcr.io/gnschenker/ sample-app:1.1 | sample-app image with the 1.1 tag belonging to an individual with the gnschenker ID on Google’s container registry. |
Images officielles
Dans le tableau précédent, nous avons mentionné l’image officielle à quelques reprises. Cela nécessite une explication. Les images sont stockées dans des référentiels sur le registre Docker Hub. Les référentiels officiels sont un ensemble de référentiels qui sont hébergés sur Docker Hub et sont gérés par des individus ou des organisations qui sont également responsables du logiciel qui est emballé à l’intérieur de l’image. Regardons un exemple de ce que cela signifie. Il existe une organisation officielle derrière la distribution Ubuntu Linux. Cette équipe fournit également des versions officielles des images Docker qui contiennent leurs distributions Ubuntu.
Les images officielles sont destinées à fournir des référentiels de base du système d’exploitation de base, des images pour les exécutions de langage de programmation populaires, le stockage de données fréquemment utilisé et d’autres services importants.
Docker parraine une équipe dont la tâche consiste à examiner et publier toutes ces images organisées dans des référentiels publics sur Docker Hub. De plus, Docker scanne toutes les images officielles à la recherche de vulnérabilités.
Pousser des images vers un registre
Créer des images personnalisées est bien beau, mais à un moment donné, nous voulons réellement partager ou expédier nos images vers un environnement cible, tel qu’un test, un contrôle qualité ou un système de production. Pour cela, nous utilisons généralement un registre de conteneurs. Docker Hub est l’un des registres les plus populaires et publics. Il est configuré en tant que registre par défaut dans votre environnement Docker, et c’est le registre à partir duquel nous avons extrait toutes nos images jusqu’à présent.
Sur un registre, on peut généralement créer des comptes personnels ou organisationnels. Par exemple, mon compte personnel sur Docker Hub est gnschenker. Les comptes personnels sont bons pour un usage personnel. Si nous voulons utiliser le registre de manière professionnelle, nous voulons probablement créer un compte d’organisation, tel que acme, sur Docker Hub. L’avantage de ce dernier est que les organisations peuvent avoir plusieurs équipes. Les équipes peuvent avoir des autorisations différentes.
Pour pouvoir envoyer une image vers mon compte personnel sur Docker Hub, je dois la marquer en conséquence. Imaginons que je veuille pousser la dernière version d’alpin sur mon compte et lui donner une balise de 1.0. Je peux le faire de la manière suivante :
$ docker image tag alpine:latest gnschenker/alpine:1.0
Maintenant, pour pouvoir pousser l’image, je dois me connecter à mon compte :
$ docker login -u gnschenker -p <my secret password>
Après une connexion réussie, je peux ensuite pousser l’image :
$ docker image push gnschenker/alpine:1.0
Je vais voir quelque chose de similaire dans le terminal :
The push refers to repository [docker.io/gnschenker/alpine]
04a094fe844e: Mounted from library/alpine
1.0: digest: sha256:5cb04fce… size: 528
Pour chaque image que nous transmettons à Docker Hub, nous créons automatiquement un référentiel. Un référentiel peut être privé ou public. Tout le monde peut extraire une image d’un référentiel public. À partir d’un référentiel privé, on ne peut extraire une image que si l’on est connecté au registre et que les autorisations nécessaires sont configurées.
Résumé
Dans ce chapitre, nous avons discuté en détail de ce que sont les images de conteneurs et comment nous pouvons les construire et les expédier. Comme nous l’avons vu, il existe trois façons différentes de créer une image, soit manuellement, soit automatiquement, soit en important une archive tar dans le système. Nous avons également appris certaines des meilleures pratiques couramment utilisées lors de la création d’images personnalisées.
Dans le chapitre suivant, nous allons présenter les volumes Docker qui peuvent être utilisés pour conserver l’état d’un conteneur, et nous présenterons également quelques commandes système utiles qui peuvent être utilisées pour inspecter l’hôte Docker plus en profondeur, travailler avec les événements générés par le démon Docker et nettoyer les ressources inutilisées.
Questions
Veuillez essayer de répondre aux questions suivantes pour évaluer vos progrès d’apprentissage :
1. Comment allez-vous créer un Dockerfile qui hérite d’Ubuntu version 17.04, et qui installe ping et exécute ping au démarrage d’un conteneur. L’adresse par défaut pour envoyer une requête ping sera 127.0.0.1.
2. Comment allez-vous créer une nouvelle image de conteneur qui utilise alpine : latest et installe curl . Nommez la nouvelle image my-alpine : 1.0.
3. Créez un Dockerfile qui utilise plusieurs étapes pour créer une image d’une application Hello World de taille minimale, écrite en C ou Go.
4. Nommez trois caractéristiques essentielles d’une image de conteneur Docker.
5. Vous voulez envoyer une image nommée foo: 1.0 à votre compte personnel jdoe sur Docker Hub. Laquelle des solutions suivantes est la bonne ?
-
- $ docker container push foo:1.0
- $ docker image tag foo:1.0 jdoe/foo:1.0
$ docker image push jdoe/foo:1.0
-
- $ docker login -u jdoe -p <your password>
$ docker image tag foo:1.0 jdoe/foo:1.0
$ docker image push jdoe/foo:1.0
-
- $ docker login -u jdoe -p <your password>
$ docker container tag foo:1.0 jdoe/foo:1.0
$ docker container push jdoe/foo:1.0
-
- $ docker login -u jdoe -p <your password>
$ docker image push foo:1.0 jdoe/foo:1.0
Volumes de données et gestion du système
Dans le dernier chapitre, nous avons appris comment créer et partager nos propres images de conteneur. Un accent particulier a été mis sur la façon de créer des images aussi petites que possible en ne contenant que des artefacts vraiment nécessaires à l’application conteneurisée.
Dans ce chapitre, nous allons apprendre comment travailler avec des conteneurs avec état, c’est-à-dire des conteneurs qui consomment et produisent des données. Nous apprendrons également à garder notre environnement Docker propre et exempt de ressources inutilisées. Enfin, nous examinerons le flux d’événements produit par un moteur Docker.
Voici une liste des sujets dont nous allons discuter :
- Création et montage de volumes de données
- Partage de données entre conteneurs
- Utilisation de volumes hôtes
- Définition des volumes dans les images
- Obtention d’informations complètes sur le système Docker
- Liste de la consommation des ressources
- Élagage des ressources inutilisées
- Consommation des événements du système Docker
Après avoir parcouru ce chapitre, vous pourrez :
- Créer, supprimer et répertorier des volumes de données
- Monter un volume de données existant dans un conteneur
- Créez des données durables à partir d’un conteneur à l’aide d’un volume de données
- Partager des données entre plusieurs conteneurs à l’aide de volumes de données
- Montez n’importe quel dossier hôte dans un conteneur à l’aide de volumes de données
- Définir le mode d’accès (lecture / écriture ou lecture seule) pour un conteneur lors de l’accès aux données dans un volume de données
- Liste de la quantité d’espace consommée par les ressources Docker sur un hôte donné, telles que les images, les conteneurs et les volumes
- Libérez votre système des ressources Docker inutilisées, telles que les conteneurs, les images et les volumes
- Afficher les événements du système Docker dans une console en temps réel
Exigences techniques
Pour ce chapitre, vous devez installer Docker Toolbox sur votre machine ou accéder à une machine virtuelle Linux exécutant Docker sur votre ordinateur portable ou dans le cloud. Il n’y a pas de code accompagnant ce chapitre.
Création et montage de volumes de données
Toutes les applications significatives consomment ou produisent des données. Pourtant, les conteneurs sont de préférence destinés à être apatrides. Comment allons-nous y faire face? Une façon consiste à utiliser les volumes Docker. Les volumes permettent aux conteneurs de consommer, de produire et de modifier l’état. Les volumes ont un cycle de vie qui va au-delà du cycle de vie des conteneurs. Lorsqu’un conteneur qui utilise un volume meurt, le volume continue d’exister. C’est génial pour la durabilité de l’état.
Modification de la couche conteneur
Avant de plonger dans les volumes, discutons d’abord de ce qui se passe si une application dans un conteneur change quelque chose dans le système de fichiers du conteneur. Dans ce cas, les modifications se produisent toutes dans la couche conteneur accessible en écriture. Démontrons rapidement cela en exécutant un conteneur et en exécutant un script qui crée un nouveau fichier:
$ docker container run –name demo \
alpine /bin/sh -c ‘echo “This is a test” > sample.txt’
La commande précédente crée un conteneur nommé démo et à l’intérieur de ce conteneur crée un fichier appelé sample.txt avec le contenu Ceci est un test. Le conteneur sort après cela mais reste en mémoire disponible pour que nous puissions faire nos investigations. Utilisons la commande diff pour découvrir ce qui a changé dans le système de fichiers du conteneur par rapport au système de fichiers de l’image :
$ docker container diff demo
La sortie devrait ressembler à ceci :
A /sample.txt
De toute évidence, un nouveau fichier, A, a été ajouté au système de fichiers du conteneur comme prévu. Étant donné que tous les calques issus de l’image sous-jacente (alpin dans ce cas) sont immuables, le changement ne peut se produire que dans le calque conteneur inscriptible.
Si nous supprimons maintenant le conteneur de la mémoire, sa couche de conteneur sera également supprimée et avec elle toutes les modifications seront supprimées de manière irréversible. Si nous avons besoin que nos modifications persistent même au-delà de la durée de vie du conteneur, ce n’est pas une solution. Heureusement, nous avons de meilleures options sous la forme de volumes Docker. Apprenons à les connaître.
Création de volumes
Étant donné que, à l’heure actuelle, lorsque les conteneurs Docker pour Mac ou Windows ne fonctionnent pas nativement sur OS X ou Windows, mais plutôt dans une machine virtuelle (masquée) créée par Docker pour Mac et Windows, il est préférable d’utiliser Docker -machine pour créer et utiliser une machine virtuelle explicite exécutant Docker. À ce stade, nous supposons que Docker Toolbox est installé sur votre système. Sinon, veuillez revenir au Chapitre 2, Configuration d’un environnement de travail, où nous fournissons des instructions détaillées sur la façon d’installer Toolbox.
Utilisez docker-machine pour répertorier toutes les machines virtuelles en cours d’exécution dans VirtualBox :
$ docker-machine ls
Si vous n’avez pas de machine virtuelle appelée node-1 répertoriée, créez-en une:
$ docker-machine create –driver virtualbox node-1
Si vous avez une machine virtuelle appelée node-1 mais qu’elle ne fonctionne pas, veuillez la démarrer :
$ docker-machine start node-1
Maintenant que tout est prêt, SSH dans cette machine virtuelle appelée node-1 :
$ docker-machine ssh node-1
Vous devriez être accueilli par une image de bienvenue de boot2docker .
Pour créer un nouveau volume de données, nous pouvons utiliser la commande docker volume create . Cela créera un volume nommé qui peut ensuite être monté dans un conteneur et être utilisé pour l’accès ou le stockage de données persistantes. La commande suivante crée un volume, my-data à l’aide du pilote de volume par défaut:
$ docker volume create my-data
Le pilote de volume par défaut est le soi-disant pilote local qui stocke les données localement dans le système de fichiers hôte. La manière la plus simple de savoir où les données sont stockées sur l’hôte est d’utiliser la commande inspect sur le volume que nous venons de créer. L’emplacement réel peut différer d’un système à l’autre et c’est donc le moyen le plus sûr de trouver le dossier cible:
$ docker volume inspect my-data
[
{
“CreatedAt”: “2018-01-28T21:55:41Z”,
“Driver”: “local”,
“Labels”: {},
“Mountpoint”: “/mnt/sda1/var/lib/docker/volumes/my-data/_ data”,
“Name”: “my-data”,
“Options”: {},
“Scope”: “local”
}
]
Le dossier hôte se trouve dans la sortie sous Mountpoint . Dans notre cas, lorsque vous utilisez docker-machine avec une machine virtuelle LinuxKit exécutée dans VirtualBox, le dossier est / mnt / sda1 / var / lib / docker / volumes / my-data / _data.
Le dossier cible est souvent un dossier protégé et nous pourrions donc avoir besoin d’utiliser sudo pour naviguer vers ce dossier et y exécuter toutes les opérations. Dans notre cas, nous n’avons pas besoin d’utiliser sudo :
$ cd /mnt/sda1/var/lib/docker/volumes/my-data/_data
Si vous utilisez Docker pour Mac pour créer un volume sur votre ordinateur portable, puis inspectez le volume du docker sur le volume que vous venez de créer, le point de montage est affiché sous la forme / var / lib / docker / volumes / my-data / _data . Mais vous découvrirez qu’il n’y a pas un tel dossier sur le Mac. La raison en est que le chemin est en relation avec la machine virtuelle cachée que Docker pour Mac utilise pour exécuter des conteneurs. À l’heure actuelle, les conteneurs ne peuvent pas s’exécuter en mode natif sur OS X. Il en va de même pour les volumes créés avec Docker pour Windows.
Il existe d’autres pilotes de volume disponibles auprès de tiers sous forme de plugins. Nous pouvons utiliser le paramètre –driver dans la commande create pour sélectionner un autre pilote de volume. D’autres pilotes de volume utilisent différents types de systèmes de stockage pour sauvegarder un volume, tels que le stockage cloud, les lecteurs NFS, le stockage défini par logiciel et plus encore.
Montage d’un volume
Une fois que nous avons créé un volume nommé, nous pouvons le monter dans un conteneur. Pour cela, nous pouvons utiliser le paramètre -v dans la commande d’exécution du conteneur docker :
$ docker container run –name test -it \
-v my-data:/data alpine /bin/sh
La commande précédente monte le volume my-data dans le dossier / data à l’intérieur du conteneur. À l’intérieur du conteneur, nous pouvons maintenant créer des fichiers dans le dossier / data puis quitter :
# / cd /data
# / echo “Some data” > data.txt
# / echo “Some more data” > data2.txt
# / exit
Si nous naviguons vers le dossier hôte qui contient les données de volume et répertorions son contenu, nous devrions voir les deux fichiers que nous venons de créer à l’intérieur du conteneur :
$ cd /mnt/sda1/var/lib/docker/volumes/my-data/_data $ ls -l total 8
-rw-r–r– 1 root root 10 Jan 28 22:23 data.txt
-rw-r–r– 1 root root 15 Jan 28 22:23 data2.txt
On peut même essayer de sortir le contenu de disons le deuxième fichier :
$ cat data2.txt
Essayons de créer un fichier dans ce dossier à partir de l’hôte, puis utilisons le volume avec un autre conteneur :
$ echo “This file we create on the host” > host-data.txt
Supprimons maintenant le conteneur de test et exécutons-en un autre basé sur CentOS. Cette fois, nous montons même notre volume dans un autre dossier de conteneurs, /app/data :
$ docker container rm test
$ docker container run –name test2 -it \
-v my-data:/app/data \
Centos:7 /bin/bash
Une fois à l’intérieur du conteneur CentOS, nous pouvons naviguer vers le dossier / app / data où nous avons monté le volume et répertorier son contenu :
# / cd /app/data
# / ls -l
Comme prévu, nous devrions voir ces trois fichiers :
-rw-r–r– 1 root root 10 Jan 28 22:23 data.txt
-rw-r–r– 1 root root 15 Jan 28 22:23 data2.txt
-rw-r–r– 1 root root 32 Jan 28 22:31 host-data.txt
C’est la preuve définitive que les données d’un volume Docker persistent au-delà de la durée de vie d’un conteneur, et que les volumes peuvent être réutilisés par d’autres conteneurs, même différents de celui qui les a utilisés en premier.
Il est important de noter que le dossier à l’intérieur du conteneur sur lequel nous montons un volume Docker est exclu du système de fichiers union. En d’autres termes, chaque modification à l’intérieur de ce dossier et de l’un de ses sous-dossiers ne fera pas partie de la couche conteneur, mais persistera dans le stockage de sauvegarde fourni par le pilote de volume. Ce fait est vraiment important car la couche de conteneur est supprimée lorsque le conteneur correspondant est arrêté et supprimé du système.
Suppression de volumes
Les volumes peuvent être supprimés à l’aide de la commande docker volume rm . Il est important de se rappeler que la suppression d’un volume détruit irréversiblement les données contenues et doit donc être considérée comme une commande dangereuse. Docker nous aide un peu à cet égard car il ne nous permet pas de supprimer un volume qui est toujours utilisé par un conteneur. Assurez-vous toujours avant de supprimer ou de supprimer un volume que vous disposez d’une sauvegarde de ses données ou que vous n’avez vraiment plus besoin de ces données.
La commande suivante supprime notre volume my-data que nous avons créé précédemment :
$ docker volume rm my-data
Après avoir exécuté la commande précédente, vérifiez à nouveau que le dossier sur l’hôte a été supprimé.
Pour supprimer tous les conteneurs en cours d’exécution pour nettoyer le système, exécutez la commande suivante :
$ docker container rm -f $(docker container ls -aq)
Partage de données entre conteneurs
Les conteneurs sont comme des bacs à sable pour les applications qui s’exécutent à l’intérieur. Ceci est principalement bénéfique et souhaité afin de protéger les applications s’exécutant dans des conteneurs différents les unes des autres. Cela signifie également que l’ensemble du système de fichiers visible par une application exécutée à l’intérieur d’un conteneur est privé de cette application et qu’aucune autre application exécutée dans un autre conteneur ne peut interférer avec elle.
Parfois, cependant, nous voulons partager des données entre les conteneurs. Supposons qu’une application s’exécutant dans le conteneur A génère des données qui seront consommées par une autre application s’exécutant dans le conteneur B. Comment pouvons-nous y parvenir ? Eh bien, je suis sûr que vous l’avez déjà deviné – nous pouvons utiliser les volumes Docker à cet effet. Nous pouvons créer un volume et le monter sur le conteneur A ainsi que sur le conteneur B. De cette manière, les deux applications A et B ont accès aux mêmes données.
Maintenant, comme toujours lorsque plusieurs applications ou processus accèdent simultanément aux données, nous devons être très prudents pour éviter les incohérences. Pour éviter les problèmes de concurrence, tels que les conditions de concurrence, nous n’avons idéalement qu’une seule application ou un seul processus qui crée ou modifie des données, tandis que tous les autres processus accédant simultanément à ces données ne les lisent que. Nous pouvons appliquer un processus s’exécutant dans un conteneur pour pouvoir uniquement lire les données d’un volume en montant ce volume en lecture seule. Jetez un œil à la commande suivante :
$ docker container run -it –name writer \
-v shared-data:/data \
alpine /bin/sh
Ici, nous créons un conteneur appelé écrivain qui a un volume, des données partagées, monté en mode lecture / écriture par défaut. Essayez de créer un fichier à l’intérieur de ce conteneur :
# / echo “I can create a file” > /data/sample.txt
Cela devrait réussir. Quittez ce conteneur, puis exécutez la commande suivante :
$ docker container run -it –name reader \
-v shared-data:/app/data:ro \
ubuntu:17.04 /bin/bash
Et nous avons un conteneur appelé reader qui a le même volume monté qu’en lecture seule (ro). Tout d’abord, assurez-vous que vous pouvez voir le fichier créé dans le premier conteneur :
$ ls -l /app/data
total 4
-rw-r–r– 1 root root 20 Jan 28 22:55 sample.txt
Et puis essayez de créer un fichier :
# / echo “Try to break read/only” > /app/data/data.txt
Il échouera avec le message suivant :
bash: /app/data/data.txt: Read-only file system
Quittons le conteneur en tapant exit à l’invite de commandes. De retour sur l’hôte, nettoyons tous les conteneurs et volumes :
$ docker container rm -f $(docker container ls -aq)
$ docker volume rm $(docker volume ls -q)
Une fois cela fait, quittez la machine virtuelle de la machine docker en tapant également exit à l’invite de commandes. Vous devriez être de retour sur votre Docker pour Mac ou Windows.
Utilisez docker-machine pour arrêter la machine virtuelle : $ docker-machine stop node-1
Utilisation des volumes hôtes
Dans certains scénarios, comme lors du développement de nouvelles applications conteneurisées ou lorsqu’une application conteneurisée doit consommer des données d’un certain dossier produites, par exemple, par une application héritée, il est très utile d’utiliser des volumes qui montent un dossier hôte spécifique. Regardons l’exemple suivant :
$ docker container run –rm -it \
-v $(pwd)/src:/app/src \
alpine:latest /bin/sh
L’expression précédente démarre de manière interactive un conteneur alpin avec un shell et monte le sous-dossier src du répertoire en cours dans le conteneur à /app/src . Nous devons utiliser $ ( pwd ) (ou ‘ pwd ‘ d’ailleurs) qui est le répertoire courant, car lorsque nous travaillons avec des volumes, nous devons toujours utiliser des chemins absolus.
Les développeurs utilisent ces techniques tout le temps lorsqu’ils travaillent sur leur application qui s’exécute dans un conteneur, et veulent s’assurer que le conteneur contient toujours les dernières modifications qu’ils apportent au code, sans avoir besoin de reconstruire l’image et de réexécuter le conteneur après chaque changement.
Faisons un échantillon pour montrer comment cela fonctionne. Disons que nous voulons créer un site Web statique simple en utilisant Nginx comme serveur Web. Tout d’abord, créons un nouveau dossier sur l’hôte où nous placerons nos ressources Web, telles que les fichiers HTML, CSS et JavaScript, et accédez-y :
$ mkdir ~/my-web
$ cd ~/my-web
Ensuite, nous créons une simple page Web comme celle-ci :
$ echo “<h1>Personal Website</h1>” > index.html
Maintenant, nous ajoutons un Dockerfile qui contiendra les instructions sur la façon de construire l’image contenant notre exemple de site Web. Ajoutez un fichier appelé Dockerfile au dossier avec ce contenu :
FROM nginx:alpine
COPY . /usr/share/nginx/html
Le Dockerfile démarre avec la dernière version Alpine de Nginx, puis copie tous les fichiers du répertoire hôte actuel dans le dossier conteneurs, /usr/share/nginx/html. C’est là que Nginx s’attend à ce que les ressources Web soient situées. Maintenant, construisons l’image avec la commande suivante :
$ docker image build -t my-website:1.0 .
Et enfin, nous exécutons un conteneur à partir de cette image. Nous exécuterons le conteneur en mode détaché :
$ docker container run -d \ -p 8080:80 –name my-site\ my-website:1.0
Notez le paramètre -p 8080: 80 . Nous n’en avons pas encore discuté, mais nous le ferons en détail au chapitre 7 , Mise en réseau à hôte unique. Pour le moment, sachez que cela mappe le port de conteneur 80 sur lequel Nginx écoute les demandes entrantes vers le port 8080 de votre ordinateur portable où vous pouvez ensuite accéder à l’application. Maintenant, ouvrez un onglet de navigateur et accédez à http: // localhost: 8080 / index.html et vous devriez voir votre site Web qui se compose actuellement uniquement d’un titre, Site Web personnel .
Maintenant, éditez le fichier index.html dans votre éditeur préféré pour qu’il ressemble à ceci :
<h1>Personal Website</h1>
<p>This is some text</p>
Et enregistrez-le. Actualisez ensuite le navigateur. OK, ça n’a pas marché. Le navigateur affiche toujours la version précédente du fichier index.html qui ne comprend que le titre. Arrêtons et supprimons le conteneur actuel, puis reconstruisons l’image et réexécutons le conteneur :
$ docker container rm -f my-site $ docker image build -t my-website:1.0 .
$ docker container run -d \ -p 8080:80 –name my-site\ my-website:1.0
Cette fois, lorsque vous actualisez le navigateur, le nouveau contenu doit être affiché. Eh bien, cela a fonctionné, mais il y a beaucoup trop de friction. Imaginez que vous deviez le faire à chaque fois que vous apportiez une modification simple à votre site Web. Ce n’est pas durable.
Il est maintenant temps d’utiliser des volumes montés sur l’hôte. Encore une fois, supprimez le conteneur actuel et réexécutez-le avec le montage de volume :
$ docker container rm -f my-site
$ docker container run -d \
-v $(pwd):/usr/share/nginx/html \
-p 8080:80 –name my-site\
my-website:1.0
Maintenant, ajoutez un peu plus de contenu à index.html et enregistrez-le. Actualisez ensuite votre navigateur. Vous devriez voir les changements. Et c’est exactement ce que nous voulions atteindre ; nous appelons également cela une expérience de modification et de poursuite. Vous pouvez effectuer autant de modifications dans vos fichiers Web et toujours voire immédiatement le résultat dans le navigateur sans avoir à reconstruire l’image et à redémarrer le conteneur contenant votre site Web.
Il est important de noter que les mises à jour sont désormais propagées dans les deux sens. Si vous apportez des modifications sur l’hôte, elles seront propagées vers le conteneur et vice versa. Il est également important de noter que lorsque vous montez le dossier actuel dans le dossier cible du conteneur, /usr/share/nginx/html , le contenu qui s’y trouve déjà est remplacé par le contenu du dossier hôte.
Définition des volumes dans les images
Si nous revenons un instant à ce que nous avons appris sur les conteneurs dans le chapitre 3, Utilisation des conteneurs, nous avons ceci : le système de fichiers de chaque conteneur lorsqu’il est démarré et composé des couches immuables de l’image sous-jacente plus une couche de conteneur inscriptible spécifique à ce même conteneur. Toutes les modifications que les processus en cours d’exécution à l’intérieur du conteneur apportent au système de fichiers seront conservées dans cette couche de conteneur. Une fois le conteneur arrêté et retiré du système, la couche de conteneur correspondante est supprimée du système et irréversiblement perdue.
Certaines applications, telles que les bases de données exécutées dans des conteneurs, doivent conserver leurs données au-delà de la durée de vie du conteneur. Dans ce cas, ils peuvent utiliser des volumes. Pour rendre les choses un peu plus explicites, regardons un exemple concret. MongoDB est une base de données de documents open source populaire. De nombreux développeurs utilisent MongoDB comme service de stockage pour leurs applications. Les responsables de MongoDB ont créé une image et l’ont publiée sur Docker Hub qui peut être utilisée pour exécuter une instance de la base de données dans un conteneur. Cette base de données produira des données qui doivent être conservées à long terme. Mais les responsables de MongoDB ne savent pas qui utilise cette image et comment elle est utilisée. Ils n’ont donc aucune influence sur la commande docker container run avec laquelle les utilisateurs de la base de données démarreront ce conteneur. Comment peuvent-ils maintenant définir des volumes ?
Heureusement, il existe un moyen de définir des volumes dans le Dockerfile . Le mot clé pour ce faire est VOLUME et nous pouvons soit ajouter le chemin absolu à un seul dossier ou une liste de chemins séparés par des virgules. Ces chemins représentent les dossiers du système de fichiers du conteneur. Regardons quelques exemples de telles définitions de volume :
VOLUME /app/data
VOLUME /app/data, /app/profiles, /app/config
VOLUME [“/app/data”, “/app/profiles”, “/app/config”]
La première ligne définit un seul volume à monter dans /app/data. La deuxième ligne définit trois volumes comme une liste séparée par des virgules et le dernier définit la même chose que la deuxième ligne, mais cette fois la valeur est formatée comme un tableau JSON.
Lorsqu’un conteneur est démarré, Docker crée automatiquement un volume et le monte dans le dossier cible correspondant du conteneur pour chaque chemin défini dans le Dockerfile. Étant donné que chaque volume est créé automatiquement par Docker, il aura un SHA-256 comme ID.
Au moment de l’exécution du conteneur, les dossiers définis comme volumes dans le Dockerfile sont exclus du système de fichiers union et donc toute modification dans ces dossiers ne modifie pas la couche de conteneur mais est conservée dans le volume respectif. Il incombe désormais aux ingénieurs d’exploitation de s’assurer que le stockage de sauvegarde des volumes est correctement sauvegardé.
Nous pouvons utiliser la commande docker image inspect pour obtenir des informations sur les volumes définis dans le Dockerfile. Voyons ce que MongoDB nous donne. Tout d’abord, nous tirons l’image avec la commande suivante :
$ docker image pull mongo:3.7
Ensuite, nous inspectons cette image et utilisons le paramètre –format pour extraire uniquement la partie essentielle de l’énorme quantité de données :
$ docker image inspect \
–format='{{json .ContainerConfig.Volumes}}’ \
mongo:3.7 | jq
Qui renverra le résultat suivant :
{
“/data/configdb”: {},
“/data/db”: {}
}
De toute évidence, le Dockerfile pour MongoDB définit deux volumes dans /data/configdb et /data/db.
Maintenant, exécutons une instance de MongoDB comme suit :
$ docker run –name my-mongo -d mongo:3.7
Nous pouvons maintenant utiliser la commande docker container inspect pour obtenir des informations sur les volumes qui ont été créés, entre autres. Utilisez cette commande pour obtenir simplement les informations de volume :
$ docker inspect –format ‘{{json .Mounts}}’ my-mongo | jq
L’expression devrait produire quelque chose comme ceci :
[
{
“Type”: “volume”,
“Name”: “b9ea0158b5…”,
“Source”: “/var/lib/docker/volumes/b9ea0158b…/_data”,
“Destination”: “/data/configdb”,
“Driver”: “local”,
“Mode”: “”,
“RW”: true,
“Propagation”: “”
},
{
“Type”: “volume”,
“Name”: “5becf84b1e…”,
“Source”: “/var/lib/docker/volumes/5becf84b1…/_data”,
“Destination”: “/data/db”,
“Driver”: “local”,
“Mode”: “”,
“RW”: true,
“Propagation”: “”
}
]
Notez que les valeurs des champs Nom et Source ont été coupées pour plus de lisibilité. Le champ Source nous donne le chemin vers le répertoire hôte où les données produites par MongoDB à l’intérieur du conteneur seront stockées.
Obtention d’informations sur le système Docker
Chaque fois que nous devons dépanner notre système, les commandes présentées dans cette section sont essentielles. Ils nous fournissent beaucoup d’informations sur le moteur Docker installé sur l’hôte et sur le système d’exploitation hôte. Commençons par présenter la commande docker version . Il fournit de nombreuses informations sur le client et le serveur Docker que votre configuration actuelle utilise. Si vous entrez la commande dans la CLI, vous devriez voir quelque chose de similaire à ceci :
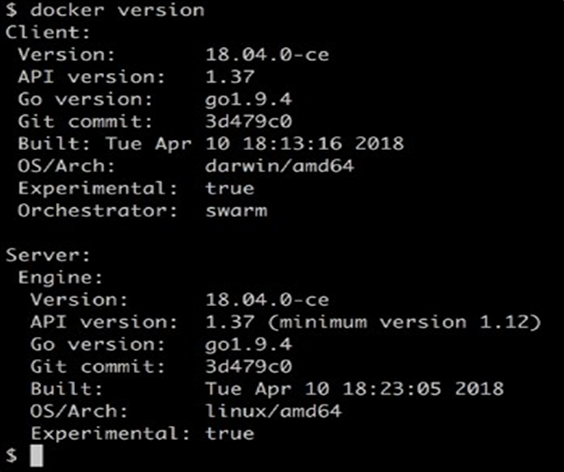
Informations de version sur Docker
Dans mon cas, je peux voir que sur le client et le serveur, j’utilise la version 18.04.0-cerc2 du moteur Docker. Je peux également voir que mon orchestrateur est Swarm et plus encore.
Maintenant, pour clarifier ce qu’est le client et ce qu’est le serveur, regardons le diagramme suivant :
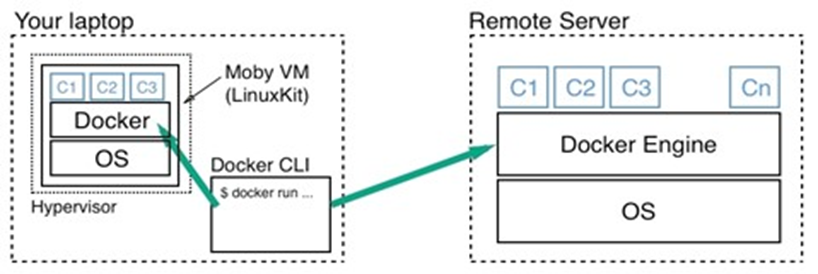
CLI accédant à différents hôtes Docker
Vous pouvez voir que le client est la petite CLI à travers laquelle nous envoyons des commandes Docker à l’API distante de l’hôte Docker. L’hôte Docker est le runtime du conteneur qui héberge les conteneurs et peut s’exécuter sur la même machine que la CLI, où il peut s’exécuter sur un serveur distant, sur site ou dans le cloud. Nous pouvons utiliser la CLI pour gérer différents serveurs. Pour ce faire, nous définissons un ensemble de variables d’environnement telles que DOCKER_HOST, DOCKER_TLS_VERIFY et DOCKER_CERT_PATH. Si ces variables d’environnement ne sont pas définies sur votre ordinateur de travail et que vous utilisez Docker pour Mac ou Windows, cela signifie que vous utilisez le moteur Docker qui s’exécute sur votre ordinateur.
La prochaine commande importante est la commande info du système docker. Cette commande fournit des informations sur le mode dans lequel le moteur Docker fonctionne (mode Swarm ou non), le pilote de stockage utilisé pour le système de fichiers union, la version du noyau Linux que nous avons sur notre hôte, et bien plus encore. Veuillez regarder attentivement la sortie générée par votre système lors de l’exécution de la commande. Analyser ce type d’information est indiqué :
Sortie des informations du système Docker Command
Liste de la consommation des ressources
Au fil du temps, un hôte Docker peut accumuler pas mal de ressources telles que des images, des conteneurs et des volumes en mémoire et sur disque. Comme dans tout bon ménage, nous devons garder notre environnement propre et libérer les ressources inutilisées pour récupérer de l’espace. Sinon, Docker ne nous permettra plus d’ajouter de nouvelles ressources, ce qui signifie que des actions telles que l’extraction d’une image peuvent échouer en raison du manque d’espace disponible sur le disque ou en mémoire.
La CLI Docker fournit une petite commande système pratique qui répertorie la quantité de ressources actuellement utilisées sur notre système et la quantité de cet espace qui peut éventuellement être récupérée. La commande est :
$ docker system df
Si vous exécutez cette commande sur votre système, vous devriez voir une sortie similaire à ceci :
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 21 9 1.103GB 845.3MB (76%)
Containers 14 11 9.144kB 4.4kB (48%)
Local Volumes 14 14 340.3MB 0B (0%)
Build Cache 0B 0B
La dernière ligne de la sortie, le cache de génération, ne s’affiche que sur les versions plus récentes de Docker. Cette information a été ajoutée récemment. La sortie précédente est expliquée comme suit :
- Dans mon cas, la sortie me dit que sur mon système, j’ai actuellement 21 images mises en cache localement, dont 9 sont en cours d’utilisation. Une image est considérée comme étant en cours d’utilisation si actuellement au moins un conteneur en cours d’exécution ou arrêté est basé sur elle. Ces images occupent 1,1 Go d’espace disque. Techniquement, près de 845 Mo peuvent être récupérés car les images correspondantes ne sont pas actuellement utilisées.
- De plus, j’ai 11 conteneurs en cours d’exécution sur mon système et trois conteneurs arrêtés pour un total de 14 conteneurs. Je peux récupérer l’espace occupé par les conteneurs arrêtés qui est de 4,4 ko dans mon cas.
- J’ai également 14 volumes actifs sur mon hôte qui consomment ensemble environ 340 Mo d’espace disque. Étant donné que tous les volumes sont en cours d’utilisation, je ne peux récupérer aucun espace pour le moment.
- Enfin, mon Build Cache est actuellement vide et donc bien sûr je ne peux pas y récupérer d’espace.
Si je veux des informations encore plus détaillées sur la consommation de ressources sur mon système, je peux exécuter la même commande en mode verbeux en utilisant l’indicateur -v :
$ docker system df -v
Cela me donnera une liste détaillée de toutes les images, conteneurs et volumes avec leur taille respective. Une sortie possible pourrait ressembler à ceci :
Sortie détaillée des ressources système consommées par Docker
Cette sortie détaillée devrait nous donner suffisamment d’informations détaillées pour prendre une décision éclairée quant à savoir si nous devons ou non commencer à nettoyer notre système, et quelles parties nous pourrions avoir besoin de nettoyer.
Élagage des ressources inutilisées
Une fois que nous avons conclu qu’un nettoyage est nécessaire, Docker nous fournit des commandes dites d’élagage. Pour chaque ressource, comme les images, les conteneurs, les volumes et les réseaux, il existe une commande d’élagage.
Conteneurs d’élagage
Dans cette section, nous voulons récupérer les ressources système inutilisées en élaguant les conteneurs.
Commençons par cette commande :
$ docker container prune
La commande précédente supprimera tous les conteneurs du système qui ne sont pas en cours d’exécution. Docker demandera une confirmation avant de supprimer les conteneurs qui sont actuellement en état de sortie ou créés. Si vous souhaitez ignorer cette étape de confirmation, vous pouvez utiliser l’indicateur -f (ou –force) :
$ docker container prune -f
Dans certaines circonstances, nous pouvons vouloir supprimer tous les conteneurs de notre système, même ceux en cours d’exécution. Nous ne pouvons pas utiliser la commande prune pour cela. À la place, nous devons utiliser une commande, telle que l’expression combinée suivante :
$ docker container rm -f $(docker container ls -aq)
Veuillez faire attention à la commande précédente. Il supprime tous les conteneurs sans avertissement, même ceux en cours d’exécution ! S’il vous plaît, avant de continuer, examinez à nouveau la commande précédente en détail et essayez d’expliquer ce qui se passe exactement et pourquoi.
Élagage des images
Viennent ensuite les images. Si nous voulons libérer tout l’espace occupé par les couches d’image inutilisées, nous pouvons utiliser la commande suivante :
$ docker image prune
Après avoir reconfirmé à Docker que nous voulons en effet libérer l’espace occupé par les couches d’image inutilisées, celles-ci sont supprimées. Maintenant, je dois spécifier ce que nous voulons dire lorsque nous parlons de couches d’image inutilisées. Comme vous vous en souvenez du chapitre précédent, une image est constituée d’une pile de couches immuables. Maintenant, lorsque nous créons plusieurs fois une image personnalisée, chaque fois que nous apportons des modifications, par exemple, au code source de l’application pour laquelle nous construisons l’image, nous recréons des couches et les versions précédentes de la même couche deviennent orphelines. Pourquoi est-ce le cas ? La raison en est que les couches sont immuables, comme expliqué en détail dans le chapitre précédent. Ainsi, lorsqu’un élément de la source utilisé pour créer une couche est modifié, la couche même doit être reconstruite et la version précédente sera abandonnée.
Sur un système où nous construisons souvent des images, le nombre de couches d’images orphelines peut augmenter considérablement au fil du temps. Toutes ces couches orphelines sont supprimées avec la commande d’élagage précédente.
Semblable à la commande prune pour les conteneurs, nous pouvons éviter que Docker nous demande une confirmation en utilisant l’indicateur de force :
$ docker image prune -f
Il existe une version encore plus radicale de la commande image prune. Parfois, nous ne voulons pas simplement supprimer les couches d’images orphelines, mais toutes les images qui ne sont pas actuellement utilisées sur notre système. Pour cela, nous pouvons utiliser le drapeau -a (ou –all) :
$ docker image prune –force –all
Après l’exécution de la commande précédente, seules les images actuellement utilisées par un ou plusieurs conteneurs resteront dans notre cache d’images local.
Volumes d’élagage
Les volumes Docker sont utilisés pour permettre un accès permanent aux données par les conteneurs. Ces données peuvent être importantes et les commandes décrites dans cette section doivent donc être appliquées avec un soin particulier.
Si vous savez que vous souhaitez récupérer l’espace occupé par les volumes et détruire irréversiblement les données sous-jacentes, vous pouvez utiliser la commande suivante :
$ docker volume prune
Cette commande supprimera tous les volumes qui ne sont pas actuellement utilisés par au moins un conteneur.
Il s’agit d’une commande destructrice et ne peut pas être annulée. Vous devez toujours créer une sauvegarde des données associées aux volumes avant de les supprimer, sauf lorsque vous êtes sûr que les données n’ont plus de valeur.
Pour éviter la corruption du système ou le dysfonctionnement des applications, Docker ne vous permet pas de supprimer les volumes actuellement utilisés par au moins un conteneur. Cela s’applique même à la situation où un volume est utilisé par un conteneur arrêté. Vous devez toujours supprimer les conteneurs qui utilisent un volume en premier.
Un indicateur utile lors de l’élagage des volumes est l’indicateur -f ou –filter qui nous permet de spécifier l’ensemble de volumes que nous envisageons pour l’élagage. Regardez la commande suivante :
$ docker volume prune –filter ‘label=demo’
Cela n’appliquera la commande qu’aux volumes qui ont une étiquette avec la valeur de démonstration. Le format d’indicateur de filtrage est clé = valeur. S’il y a plus d’un filtre nécessaire, alors nous pouvons utiliser plusieurs drapeaux :
$ docker volume prune –filter ‘label=demo’ –filter ‘label=test’
L’indicateur de filtre peut également être utilisé lors de l’élagage d’autres ressources telles que les conteneurs et les images.
Réseaux d’élagage
Les dernières ressources pouvant être élaguées sont les réseaux. Nous discuterons des réseaux en détail dans le chapitre 7, Réseaux à hôte unique. Pour supprimer tous les réseaux inutilisés, nous utilisons la commande suivante :
$ docker network prune
Cela supprimera les réseaux auxquels aucun conteneur ou service n’est actuellement connecté. Veuillez ne pas trop vous soucier des réseaux pour le moment. Nous reviendrons vers eux et tout cela aura beaucoup plus de sens pour vous.
Tout élagaguer
Si nous voulons simplement tout tailler à la fois sans avoir à entrer plusieurs commandes, nous pouvons utiliser la commande suivante :
$ docker system prune
La CLI Docker nous demandera une confirmation, puis supprimera tous les conteneurs, images, volumes et réseaux inutilisés en une seule fois et dans le bon ordre.
Encore une fois, pour éviter que Docker ne nous demande une confirmation, nous pouvons simplement utiliser l’indicateur de force avec la commande.
Consommation des événements du système Docker
Le moteur Docker, lors de la création, de l’exécution, de l’arrêt et de la suppression de conteneurs et d’autres ressources telles que des volumes ou des réseaux, génère un journal des événements. Ces événements peuvent être consommés par des systèmes externes, tels que certains services d’infrastructure qui les utilisent pour prendre des décisions éclairées. Un exemple d’un tel service pourrait être un outil qui crée un inventaire de tous les conteneurs qui s’exécutent actuellement sur le système.
Nous pouvons nous connecter à ce flux d’événements système et les afficher, par exemple dans un terminal, en utilisant la commande suivante :
$ docker system events
Cette commande est une commande de blocage. Ainsi, lorsque vous l’exécutez dans votre session de terminal, la session correspondante est bloquée. Par conséquent, nous vous recommandons de toujours ouvrir une fenêtre supplémentaire lorsque vous souhaitez utiliser cette commande.
En supposant que nous avons exécuté la commande précédente dans une fenêtre de terminal supplémentaire, nous pouvons maintenant la tester et exécuter un conteneur comme celui-ci :
$ docker container run –rm alpine echo “Hello World”
La sortie produite devrait ressembler à ceci :
2018-01-28T15:08:57.318341118-06:00 container create
8e074342ef3b20cfa73d17e4ef7796d424aa8801661765ab5024acf166c6ecf3
(image=alpine, name=confident_hopper)
2018-01-28T15:08:57.320934314-06:00 container attach
8e074342ef3b20cfa73d17e4ef7796d424aa8801661765ab5024acf166c6ecf3
(image=alpine, name=confident_hopper)
2018-01-28T15:08:57.354869473-06:00 network connect c8fd270e1a776c5851c9fa1e79927141a1e1be228880c0aace4d0daebccd190f (container=8e074342ef3b20cfa73d17e4ef7796d424aa8801661765ab5024acf
166c6ecf3, name=bridge, type=bridge)
2018-01-28T15:08:57.818494970-06:00 container start
8e074342ef3b20cfa73d17e4ef7796d424aa8801661765ab5024acf166c6ecf3
(image=alpine, name=confident_hopper)
2018-01-28T15:08:57.998941548-06:00 container die
8e074342ef3b20cfa73d17e4ef7796d424aa8801661765ab5024acf166c6ecf3
(exitCode=0, image=alpine, name=confident_hopper)
2018-01-28T15:08:58.304784993-06:00 network disconnect c8fd270e1a776c5851c9fa1e79927141a1e1be228880c0aace4d0daebccd190f (container=8e074342ef3b20cfa73d17e4ef7796d424aa8801661765ab5024acf
166c6ecf3, name=bridge, type=bridge)
2018-01-28T15:08:58.412513530-06:00 container destroy
8e074342ef3b20cfa73d17e4ef7796d424aa8801661765ab5024acf166c6ecf3
(image=alpine, name=confident_hopper)
Dans cette sortie, nous pouvons suivre le cycle de vie exact du conteneur. Le conteneur est créé, démarré, puis détruit. Si la sortie générée par cette commande ne vous convient pas, vous pouvez toujours la modifier en utilisant le paramètre –format. La valeur du format doit être écrite à l’aide de la syntaxe du modèle Go. L’exemple suivant génère le type, l’image et l’action de l’événement :
$ docker system events –format ‘Type={{.Type}} Image={{.Actor.Attributes.image}} Action={{.Action}}’
Si nous exécutons exactement la même commande d’exécution de conteneur que précédemment, la sortie générée ressemble maintenant à ceci :
Type=container Image=alpine Action=create
Type=container Image=alpine Action=attach
Type=network Image=<no value> Action=connect
Type=container Image=alpine Action=start
Type=container Image=alpine Action=die
Type=network Image=<no value> Action=disconnect
Type=container Image=alpine Action=destroy
Résumé
Dans ce chapitre, nous avons présenté les volumes Docker qui peuvent être utilisés pour conserver les états produits par les conteneurs et les rendre durables. Nous pouvons également utiliser des volumes pour fournir aux conteneurs des données provenant de diverses sources. Nous avons appris à créer, monter et utiliser des volumes. Nous avons appris diverses techniques de définition de volumes, par exemple par nom, en montant un répertoire hôte ou en définissant des volumes dans une image de conteneur.
Dans ce chapitre, nous avons également discuté de diverses commandes au niveau du système qui nous fournissent soit de nombreuses informations pour dépanner un système, soit pour gérer et élaguer les ressources utilisées par Docker. Enfin, nous avons appris comment visualiser et potentiellement consommer le flux d’événements généré par le runtime du conteneur.
Dans le chapitre suivant, nous allons obtenir une introduction aux principes fondamentaux de l’orchestration de conteneurs. Là, nous allons discuter de ce qui est nécessaire lorsque nous devons gérer et exécuter non seulement un ou quelques conteneurs, mais potentiellement des centaines d’entre eux sur de nombreux nœuds d’un cluster. Nous verrons qu’il y a beaucoup de défis à résoudre. C’est là que les moteurs d’orchestration entrent en jeu.
Questions
Veuillez essayer de répondre aux questions suivantes pour évaluer vos progrès d’apprentissage :
1. Comment allez-vous créer un volume de données nommé avec un nom, par exemple mes produits, en utilisant le pilote par défaut ?
2. Comment allez-vous exécuter un conteneur en utilisant l’image alpine et monter le volume my-products en mode lecture seule dans le dossier du conteneur / data ?
3. Comment localisez-vous le dossier associé aux volumes myproducts et accédez-y ? Aussi, comment allez-vous créer un fichier, sample.txt avec du contenu ?
4. Comment allez-vous exécuter un autre conteneur alpin sur lequel vous montez le volume myproducts dans le dossier / app-data, en mode lecture / écriture ? À l’intérieur de ce conteneur, accédez au dossier / app-data et créez un fichier hello.txt avec du contenu.
5. Comment allez-vous monter un volume hôte, par exemple ~ / mon-projet, dans un conteneur ?
6. Comment supprimerez-vous tous les volumes inutilisés de votre système ?
7. Comment allez-vous déterminer la version exacte du noyau Linux et de Docker fonctionnant sur votre système ?
Architecture d’application distribuée
Dans le chapitre précédent, nous avons appris comment utiliser les volumes Docker pour conserver l’état créé ou modifié, ainsi que pour partager des données entre des applications exécutées dans des conteneurs. Nous avons également appris à travailler avec les événements générés par le démon Docker et à nettoyer les ressources inutilisées.
Dans ce chapitre, nous présentons le concept d’une architecture d’application distribuée et discutons des divers modèles et meilleures pratiques nécessaires pour exécuter une application distribuée avec succès. Enfin, nous discuterons des exigences supplémentaires qui doivent être remplies pour exécuter une telle application en production.
Dans ce chapitre, nous couvrirons les sujets suivants :
- Qu’est-ce qu’une architecture d’application distribuée ?
- Modèles et meilleures pratiques
- Fonctionnement en production
Après avoir terminé ce chapitre, vous pourrez effectuer les opérations suivantes :
- Nommer au moins quatre caractéristiques d’une architecture d’application distribuée
- Nommez au moins quatre modèles qui doivent être implémentés pour une application déjà distribuée en production
Qu’est-ce qu’une architecture d’application distribuée ?
Dans cette section, nous allons expliquer en détail ce que nous entendons lorsque nous parlons d’une architecture d’application distribuée. Tout d’abord, nous devons nous assurer que tous les mots ou acronymes que nous utilisons ont un sens et que nous parlons tous la même langue.
Définition de la terminologie
Dans ce chapitre et les suivants, nous parlerons beaucoup de concepts qui pourraient ne pas être familiers à tout le monde. Pour nous assurer que nous parlons tous la même langue, présentons et décrivons brièvement les plus importants de ces concepts ou mots :
| VM | Acronym for virtual machine. This is a virtual computer. |
| Node | Individual server used to run applications. This can be a physical server, often called bare metal, or a VM. A node can be a mainframe, supercomputer, standard business server, or even a Raspberry Pi. Nodes can be computers in a company’s own data center or in the cloud. Normally, a node is part of a cluster. |
| Cluster | Group of nodes connected by a network used to run distributed applications. |
| Network | Physical and software-defined communication paths between individual nodes of a cluster and programs running on those nodes. |
| Port | Channel on which an application such a web server listens for incoming requests. |
| Service | This, unfortunately, is a very overloaded term and its real meaning depends on the context in which it is used. If we use the term service in the context of an application such as an application service, then it usually means that this is a piece of software that implements a limited set of functionality which is then used by other parts of the application. As we progress through this book, other types of services that have a slightly different definition will be discussed. |
Naïvement, une architecture d’application distribuée est l’opposé d’une architecture d’application monolithique, mais il n’est pas déraisonnable de regarder cette architecture monolithique en premier. Traditionnellement, la plupart des applications d’entreprise ont été écrites de telle manière que le résultat peut être considéré comme un seul programme étroitement couplé qui s’exécute sur un serveur nommé quelque part dans un centre de données. Tout son code est compilé en un seul binaire ou en quelques binaires très étroitement couplés qui doivent être colocalisés lors de l’exécution de l’application. Le fait que le serveur, ou l’hôte plus général, sur lequel l’application s’exécute possède un nom bien défini ou une adresse IP statique est également important dans ce contexte. Regardons le schéma suivant pour illustrer un peu plus clairement ce type d’architecture d’application :
Architecture d’application monolithique
Dans le diagramme précédent, nous voyons un serveur nommé blue-box-12a avec une adresse IP de 172.52.13.44 exécutant une application appelée pet-shop, qui est un monolithe composé d’un module principal et de quelques bibliothèques étroitement couplées.
Maintenant, regardons le diagramme suivant :
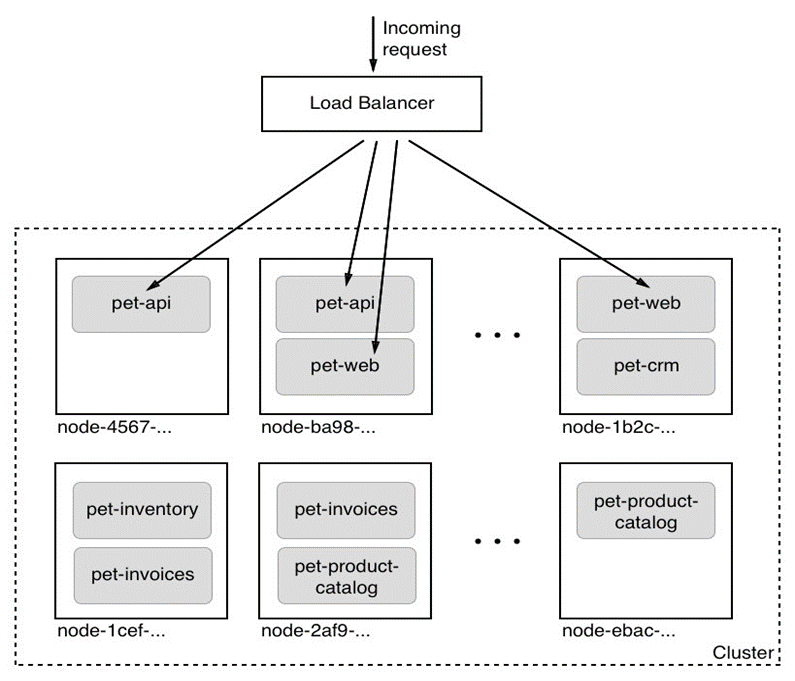
Architecture d’application distribuée
Ici, tout d’un coup, nous n’avons plus un seul serveur nommé, mais nous en avons beaucoup et ils n’ont pas de noms conviviaux, mais plutôt des ID uniques qui peuvent être quelque chose comme un unique universel identifiant (UUID). L’application pour animalerie, tout d’un coup, ne consiste plus non plus en un seul bloc monolithique, mais plutôt en une pléthore de services interactifs mais faiblement couplés tels que pet- api, pet-web et animal-inventaire. De plus, chaque service s’exécute dans plusieurs instances de ce cluster de serveurs ou d’hôtes.
Vous vous demandez peut-être pourquoi nous en discutons dans un article sur les conteneurs Docker, et vous avez raison de demander. Bien que tous les sujets que nous allons étudier s’appliquent également à un monde où les conteneurs n’existent pas (encore), il est important de réaliser que les conteneurs et les moteurs d’orchestration de conteneurs aident à résoudre tous les problèmes de manière beaucoup plus efficace et directe. La plupart des problèmes qui étaient auparavant très difficiles à résoudre dans une architecture d’application distribuée deviennent assez simples dans un monde conteneurisé.
Modèles et meilleures pratiques
Une architecture d’application distribuée présente de nombreux avantages convaincants, mais elle présente également un inconvénient très important par rapport à une architecture d’application monolithique – la première est beaucoup plus complexe. Pour apprivoiser cette complexité, l’industrie a mis au point des pratiques exemplaires et des modèles importants. Dans les sections suivantes, nous allons examiner plus en détail certaines des plus importantes.
Composants à couplage lâche
La meilleure façon d’aborder un sujet complexe a toujours été de le diviser en sous-problèmes plus petits et plus faciles à gérer. Par exemple, il serait incroyablement complexe de construire une maison en une seule étape. Il est beaucoup plus facile de construire la maison à partir de pièces simples qui sont ensuite combinées dans le résultat final.
Il en va de même pour le développement de logiciels. Il est beaucoup plus facile de développer une application très complexe si nous divisons cette application en composants plus petits qui interagissent et forment ensemble l’application globale. Maintenant, il est beaucoup plus facile de développer ces composants individuellement s’ils ne sont que faiblement couplés les uns aux autres. Cela signifie que le composant A ne fait aucune hypothèse sur le fonctionnement interne des composants B et C, par exemple, mais s’intéresse uniquement à la façon dont il peut communiquer avec ces deux composants à travers une interface bien définie. Si chaque composant a une interface publique simple et bien définie à travers laquelle la communication avec les autres composants du système et le monde extérieur se produit, cela nous permet de développer chaque composant individuellement, sans dépendances implicites avec d’autres composants. Au cours du processus de développement, d’autres composants du système peuvent être remplacés par des talons ou des maquettes pour nous permettre de tester notre composant.
Avec ou sans état
Chaque application métier significative crée, modifie ou utilise des données. Les données sont également appelées état. Un service d’application qui crée ou modifie des données persistantes est appelé un composant avec état. Les composants avec état typiques sont les services de base de données ou les services qui créent des fichiers. D’un autre côté, les composants d’application qui ne créent ni ne modifient les données persistantes sont appelés composants sans état.
Dans une architecture d’application distribuée, les composants sans état sont beaucoup plus simples à gérer que les composants avec état. Les composants sans état peuvent être facilement augmentés et réduits. Ils peuvent également être rapidement et sans problème supprimés et redémarrés sur un nœud complètement différent du cluster, tout cela car ils ne sont associés à aucune donnée persistante.
Dans ce contexte, il est utile de concevoir un système de manière à ce que la plupart des services d’application soient sans état. Il est préférable de pousser tous les composants avec état à la limite de l’application et de limiter leur nombre. La gestion des composants avec état est difficile.
Découverte de service
Alors que nous créons des applications composées de nombreux composants ou services individuels qui communiquent entre eux, nous avons besoin d’un mécanisme qui permet aux composants individuels de se retrouver dans le cluster. Se retrouver signifie généralement qu’il faut savoir sur quel nœud le composant cible s’exécute et sur quel port il écoute la communication. Le plus souvent, les nœuds sont identifiés par une adresse IP et un port, qui n’est qu’un nombre dans une plage bien définie.
Techniquement, nous pourrions indiquer au service A, qui souhaite communiquer avec une cible, le service B, quelles sont l’adresse IP et le port de la cible. Cela peut se produire, par exemple, via une entrée dans un fichier de configuration :
Les composants sont câblés
Bien que cela puisse très bien fonctionner dans le contexte d’une application monolithique qui s’exécute sur un ou seulement quelques serveurs bien connus et organisés, elle se désintègre totalement dans une architecture d’application distribuée. Tout d’abord, dans ce scénario, nous avons de nombreux composants, et leur suivi manuel devient un cauchemar. Ce n’est certainement pas évolutif. De plus, le service A ne devrait ou ne saura généralement jamais sur quel nœud du cluster les autres composants s’exécutent. Leur emplacement peut même ne pas être stable car le composant B pourrait être déplacé du nœud X vers un autre nœud Y, pour diverses raisons externes à l’application. Ainsi, nous avons besoin d’un autre moyen par lequel le service A peut localiser le service B, ou tout autre service d’ailleurs. Ce qui est le plus couramment utilisé est une autorité externe qui connaît la topologie du système à un moment donné. Cette autorité ou ce service externe connaît tous les nœuds et leurs adresses IP qui appartiennent actuellement au cluster ; il connaît tous les services qui s’exécutent et où ils s’exécutent. Souvent, ce type de service est appelé service DNS, où DNS signifie Domain Name System. Comme nous le verrons, Docker a un service DNS implémenté dans le cadre du moteur sous-jacent. Kubernetes utilise également un service DNS pour faciliter la communication entre les composants exécutés dans le cluster :
Les composants consultent un service de localisation externe
Dans le diagramme précédent, nous voyons comment le service A souhaite communiquer avec le service B. Mais il ne peut pas le faire directement ; il doit d’abord interroger l’autorité externe, un service de registre, ici appelé service DNS, sur la localisation du service B. Le service de registre répondra avec les informations demandées et distribuera l’adresse IP et le numéro de port avec lesquels le service A peut atteindre Le service B. Le service A utilise ensuite ces informations et établit la communication avec le service B.Bien sûr, c’est une image naïve de ce qui se passe réellement à un bas niveau, mais c’est une bonne image pour comprendre le modèle architectural de la découverte du service.
Routage
Le routage est le mécanisme d’envoi de paquets de données d’un composant source vers un composant cible. Le routage est classé en différents types. On utilise le modèle dit OSI (voir référence dans la section Lectures complémentaires de ce chapitre) pour distinguer les différents types de routage. Dans le contexte des conteneurs et de l’orchestration des conteneurs, le routage au niveau des couches 2, 3, 4 et 7 est pertinent. Nous approfondirons le routage dans les chapitres suivants. Ici, disons simplement que le routage de couche 2 est le type de routage le plus bas niveau, qui connecte une adresse MAC à une adresse MAC, tandis que le routage de couche 7, également appelé routage de niveau application, est le plus haut niveau. Ce dernier est, par exemple, utilisé pour acheminer les demandes ayant un identifiant cible qui est une URL telle que example.com/pets vers le composant cible approprié dans notre système.
Équilibrage de charge
L’équilibrage de charge est utilisé chaque fois que le service A demande un service au service B, mais ce dernier s’exécute dans plusieurs instances, comme illustré dans le diagramme suivant :
Demande de service A équilibrée par rapport au service B
Si nous avons plusieurs instances d’un service tel que le service B en cours d’exécution dans notre système, nous voulons nous assurer que chacune de ces instances reçoit une charge de travail égale. Cette tâche est générique, ce qui signifie que nous ne voulons pas que l’appelant doive effectuer l’équilibrage de charge, mais plutôt un service externe qui intercepte l’appel et prend en charge la partie de la décision vers laquelle des instances de service cible transférer l’appel. Ce service externe est appelé équilibreur de charge. Les équilibreurs de charge peuvent utiliser différents algorithmes pour décider comment distribuer les appels entrants aux instances de service cible. L’algorithme le plus couramment utilisé est appelé round robin. Cet algorithme affecte simplement les requêtes de manière répétitive, en commençant par l’instance 1 puis 2 jusqu’à l’instance n. Une fois la dernière instance servie, l’équilibreur de charge recommence avec l’instance numéro 1.
Programmation défensive
Lors du développement d’un service pour une application distribuée, il est important de se rappeler que ce service ne va pas être autonome, mais dépend d’autres services d’application ou même de services externes fournis par des tiers, tels que des services de validation de carte de crédit ou des informations sur les stocks services, pour n’en nommer que deux. Tous ces autres services sont externes au service que nous développons. Nous n’avons aucun contrôle sur leur exactitude ou leur disponibilité à un moment donné. Ainsi, lors du codage, nous devons toujours assumer le pire et espérer le meilleur. En supposant que le pire signifie que nous devons traiter explicitement les défaillances potentielles.
Nouvelles tentatives
Lorsqu’il existe un risque qu’un service externe soit temporairement indisponible ou ne réponde pas suffisamment, la procédure suivante peut être utilisée. Lorsque l’appel à l’autre service échoue ou expire, le code appelant doit être structuré de telle sorte que le même appel soit répété après un court temps d’attente. Si l’appel échoue à nouveau, l’attente devrait être un peu plus longue avant le prochain essai. Les appels doivent être répétés jusqu’à un nombre maximum de fois, augmentant à chaque fois le temps d’attente. Après cela, le service devrait abandonner et fournir un service dégradé, ce qui pourrait signifier renvoyer des données mises en cache ou aucune donnée, selon la situation.
Journalisation
Les opérations importantes dans un service doivent toujours être enregistrées. Les informations de journalisation doivent être classées pour avoir une valeur réelle. Une liste courante de catégories est débogage, info, avertissement, erreur et fatal. Les informations de journalisation doivent être collectées par un service d’agrégation de journaux central et ne pas être stockées sur un nœud individuel du cluster. Les journaux agrégés sont faciles à analyser et à filtrer pour obtenir des informations pertinentes.
Traitement des erreurs
Comme mentionné précédemment, chaque service d’application dans une application distribuée dépend d’autres services. En tant que développeurs, nous devons toujours nous attendre au pire et disposer d’une gestion des erreurs appropriée. L’une des meilleures pratiques les plus importantes consiste à échouer rapidement. Codez le service de manière à ce que les erreurs irrécupérables soient découvertes le plus tôt possible et, si une telle erreur est détectée, faites échouer le service immédiatement. Mais n’oubliez pas de consigner des informations significatives dans STDERR ou STDOUT, qui peuvent être utilisées par les développeurs ou les opérateurs système ultérieurement pour suivre les dysfonctionnements du système. De plus, renvoyez une erreur utile à l’appelant, indiquant aussi précisément que possible pourquoi l’appel a échoué.
Un exemple d’échec rapide consiste à toujours vérifier les valeurs d’entrée fournies par l’appelant. Les valeurs sont-elles dans les plages attendues et complètes ? Sinon, n’essayez pas de poursuivre le traitement, mais abandonnez immédiatement l’opération.
Redondance
Un système essentiel à la mission doit être disponible tout le temps, 24 heures sur 24, 365 jours par an. Les temps d’arrêt ne sont pas acceptables, car cela pourrait entraîner une énorme perte d’opportunités ou de réputation pour l’entreprise. Dans une application hautement distribuée, la probabilité d’une défaillance d’au moins l’un des nombreux composants impliqués n’est pas négligeable. On peut dire que la question n’est pas de savoir si un composant échouera, mais plutôt quand une défaillance se produira.
Pour éviter les temps d’arrêt lorsque l’un des nombreux composants du système tombe en panne, chaque partie individuelle du système doit être redondante. Cela inclut les composants de l’application ainsi que toutes les parties de l’infrastructure. Cela signifie que si, par exemple, nous avons un service de paiement dans le cadre de notre application, nous devons exécuter ce service de manière redondante. La façon la plus simple de le faire est d’exécuter plusieurs instances de ce même service sur différents nœuds de notre cluster. Il en va de même, par exemple, pour un routeur de périphérie ou un équilibreur de charge. Nous ne pouvons pas nous permettre que cela diminue. Ainsi, le routeur ou l’équilibreur de charge doit être redondant.
Contrôles d’intégrité
Nous avons mentionné à plusieurs reprises que dans une architecture d’application distribuée, avec ses nombreuses parties, la défaillance d’un composant individuel est très probable et ce n’est qu’une question de temps jusqu’à ce qu’elle se produise. Pour cette raison, nous exécutons chaque composant du système de manière redondante. Les services proxy équilibrent ensuite la charge du trafic sur les instances individuelles d’un service.
Mais maintenant, il y a un autre problème. Comment le proxy ou le routeur sait-il si une certaine instance de service est disponible ou non ? Il aurait pu tomber en panne ou ne pas répondre. Pour résoudre ce problème, on utilise ce qu’on appelle des contrôles d’intégrité. Le proxy, ou un autre service système au nom du proxy, interroge périodiquement toutes les instances de service et vérifie leur état. Les questions sont essentiellement Êtes-vous toujours là ? Êtes-vous en bonne santé ? La réponse de chaque service est Oui ou Non, ou le bilan de santé expire si l’instance ne répond plus.
Si le composant répond Non ou qu’un délai d’attente se produit, le système tue l’instance correspondante et fait tourner une nouvelle instance à sa place. Si tout cela se produit de manière entièrement automatisée, alors nous disons que nous avons un système d’autoguérison en place.
Schéma du disjoncteur
Un disjoncteur est un mécanisme utilisé pour éviter la panne d’une application distribuée en raison d’une défaillance en cascade de nombreux composants essentiels. Les disjoncteurs aident à éviter qu’un composant défaillant n’abatte d’autres services dépendants dans un effet domino. Comme les disjoncteurs dans un système électrique, qui protègent une maison contre les incendies en raison de la défaillance d’un appareil branché défectueux en interrompant la ligne électrique, les disjoncteurs dans une application distribuée interrompent la connexion du service A au service B si ce dernier ne répond pas ou fonctionne mal.
Cela peut être réalisé en enveloppant un appel de service protégé dans un objet disjoncteur. Cet objet surveille les échecs. Une fois que le nombre de pannes atteint un certain seuil, le disjoncteur se déclenche. Tous les appels suivants au disjoncteur seront renvoyés avec une erreur, sans que l’appel protégé soit effectué du tout :

Modèle de disjoncteur
Fonctionnement en production
Pour exécuter avec succès une application distribuée en production, nous devons prendre en compte quelques aspects supplémentaires au-delà des meilleures pratiques et modèles présentés dans les sections précédentes. Un domaine spécifique qui me vient à l’esprit est l’introspection et la surveillance. Passons en revue les aspects les plus importants en détail.
Journalisation
Une fois qu’une application distribuée est en production, il n’est pas possible de la déboguer. Mais comment savoir alors qu’elle est exactement la cause première d’un dysfonctionnement de l’application signalé par un utilisateur ? La solution à ce problème consiste à produire des informations de journalisation abondantes et significatives. Les développeurs doivent instrumenter leurs services d’application de manière à produire des informations utiles, par exemple lorsqu’une erreur se produit ou qu’une situation potentiellement inattendue ou indésirable se produit. Souvent, ces informations sont sorties vers STDOUT et STDERR, d’où elles sont ensuite collectées par des démons système qui écrivent les informations dans des fichiers locaux ou les transmettent à un service d’agrégation de journaux central.
S’il y a suffisamment d’informations dans les journaux, les développeurs peuvent utiliser ces journaux pour rechercher la cause première des erreurs dans le système qui ont été signalées.
Dans une architecture d’application distribuée, avec ses nombreux composants, la journalisation est encore plus importante que dans une application monolithique. Les chemins d’exécution d’une seule requête à travers tous les composants de l’application peuvent être très complexes. N’oubliez pas non plus que les composants sont répartis sur un cluster de nœuds. Ainsi, il est logique de consigner tout ce qui est important et à chaque entrée de journal d’ajouter des éléments tels que l’heure exacte à laquelle il s’est produit, le composant dans lequel il s’est produit et le nœud sur lequel le composant a fonctionné, pour n’en nommer que quelques-uns. En outre, les informations de journalisation doivent être regroupées dans un emplacement central afin qu’elles soient facilement disponibles pour les développeurs et les opérateurs système à analyser.
Traçage
Le suivi est utilisé pour découvrir comment une demande individuelle est acheminée via une application distribuée et combien de temps est passé globalement pour la demande et dans chaque composant individuel. Ces informations, si elles sont collectées, peuvent être utilisées comme l’une des sources de tableaux de bord qui montrent le comportement et l’intégrité du système.
Surveillance
Les opérateurs aiment avoir des tableaux de bord montrant des mesures clés en direct du système, qui leur montrent la santé globale de l’application en un coup d’œil. Ces mesures peuvent être des mesures non fonctionnelles telles que l’utilisation de la mémoire et du processeur, le nombre de plantages d’un système ou d’un composant d’application, l’intégrité d’un nœud, etc., ainsi que des mesures fonctionnelles et donc spécifiques à l’application telles que le nombre de retraits dans un système de commande ou le nombre d’articles en rupture de stock dans un service d’inventaire.
Le plus souvent, les données de base utilisées pour agréger les nombres utilisés pour un tableau de bord sont extraites des informations de journalisation. Il peut s’agir de journaux système, qui seront principalement utilisés pour les mesures non fonctionnelles, et de journaux au niveau de l’application, pour les mesures fonctionnelles.
Mises à jour de l’application
L’un des avantages concurrentiels pour une entreprise est de pouvoir réagir en temps opportun aux situations changeantes du marché. Cela consiste en partie à pouvoir ajuster rapidement une application pour répondre à des besoins nouveaux et modifiés ou pour ajouter de nouvelles fonctionnalités. Plus vite nous pourrons mettre à jour nos applications, mieux ce sera. De nos jours, de nombreuses entreprises déploient des fonctionnalités nouvelles ou modifiées plusieurs fois par jour.
Étant donné que les mises à jour d’application sont si fréquentes, ces mises à jour doivent être non perturbatrices. Nous ne pouvons pas permettre au système de s’arrêter pour maintenance lors de la mise à niveau. Tout doit se passer de manière transparente et transparente.
Mises à jour continues
Une façon de mettre à jour une application ou un service d’application consiste à utiliser des mises à jour continues. L’hypothèse ici est que le logiciel particulier qui doit être mis à jour s’exécute dans plusieurs instances. Ce n’est qu’à cette condition que nous pourrons utiliser ce type de mise à jour.
Ce qui se passe, c’est que le système arrête une instance du service actuel et la remplace par une instance du nouveau service. Dès que la nouvelle instance est prête, le trafic sera traité. Habituellement, la nouvelle instance est surveillée pendant un certain temps pour voir si elle fonctionne ou non comme prévu et, si c’est le cas, la prochaine instance du service actuel est supprimée et remplacée par une nouvelle instance. Ce modèle est répété jusqu’à ce que toutes les instances de service aient été remplacées.
Puisqu’il y a toujours quelques instances en cours d’exécution à un moment donné, actuel ou nouveau, l’application est opérationnelle tout le temps. Aucun temps d’arrêt n’est nécessaire.
Déploiements bleu-vert
Dans les déploiements bleu-vert, la version actuelle du service d’application, appelée bleu, gère tout le trafic d’application. Nous installons ensuite la nouvelle version du service d’application, appelée verte, sur le système de production. Le nouveau service n’est pas encore câblé avec le reste de l’application.
Une fois le vert installé, on peut exécuter des tests de fumée par rapport à ce nouveau service et, si ceux-ci réussissent, le routeur peut être configuré pour canaliser tout le trafic qui était auparavant passé au bleu vers le nouveau service, le vert. Le comportement du vert est alors observé de près et, si tous les critères de réussite sont remplis, le bleu peut être déclassé. Mais si, pour une raison quelconque, le vert montre un comportement inattendu ou indésirable, le routeur peut être reconfiguré pour retourner tout le trafic au bleu. Le vert peut ensuite être supprimé et corrigé, et un nouveau déploiement bleu-vert peut être exécuté avec la version corrigée :
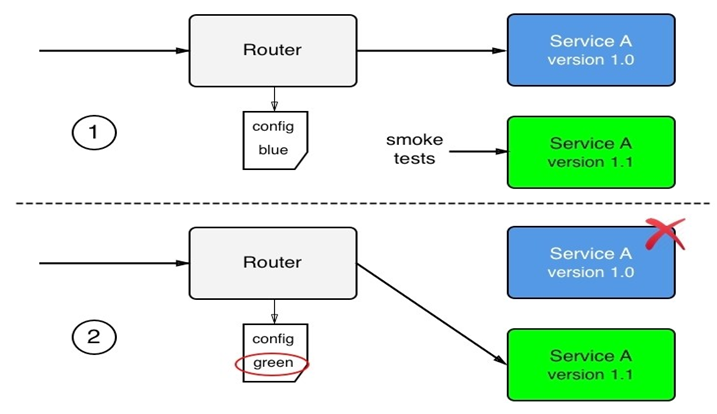
Déploiement bleu-vert
Libérations des Canaries
Les versions Canary sont des versions où nous avons la version actuelle du service d’application et la nouvelle version installée sur le système en parallèle. En tant que tels, ils ressemblent à des déploiements bleu-vert. Au début, tout le trafic est toujours acheminé via la version actuelle. Nous configurons ensuite un routeur pour qu’il achemine un petit pourcentage, disons 1%, du trafic global vers la nouvelle version du service d’application. Le comportement du nouveau service est ensuite surveillé de près pour savoir s’il fonctionne ou non comme prévu. Si tous les critères de réussite sont remplis, le routeur est configuré pour acheminer plus de trafic, disons 5% cette fois, via le nouveau service. Encore une fois, le comportement du nouveau service est étroitement surveillé et, s’il réussit, de plus en plus de trafic y est acheminé jusqu’à atteindre 100%. Une fois que tout le trafic est acheminé vers le nouveau service et qu’il est stable depuis un certain temps, l’ancienne version du service peut être mise hors service.
Pourquoi appelons-nous cela une sortie des Canaries ? Il porte le nom des mineurs de charbon qui utiliseraient les oiseaux canaris comme système d’alerte précoce dans les mines. Les oiseaux canaris sont particulièrement sensibles aux gaz toxiques et si un tel oiseau canari mourait, les mineurs savaient qu’ils devaient abandonner la mine immédiatement.
Modifications irréversibles des données
Si une partie de notre processus de mise à jour consiste à exécuter un changement irréversible de notre état, tel qu’un changement de schéma irréversible dans une base de données relationnelle de support, nous devons y remédier avec un soin particulier. Il est possible d’exécuter de telles modifications sans interruption si l’on utilise la bonne approche. Il est important de reconnaître que, dans une telle situation, on ne peut pas déployer les modifications de code qui nécessitent la nouvelle structure de données dans le magasin de données en même temps que les modifications apportées aux données. Au contraire, toute la mise à jour doit être séparée en trois étapes distinctes. Dans la première étape, on déploie un schéma rétro compatible et un changement de données. Si cela réussit, alors on déploie le nouveau code dans la deuxième étape. Encore une fois, si cela réussit, on nettoie le schéma à la troisième étape et supprime la compatibilité descendante :
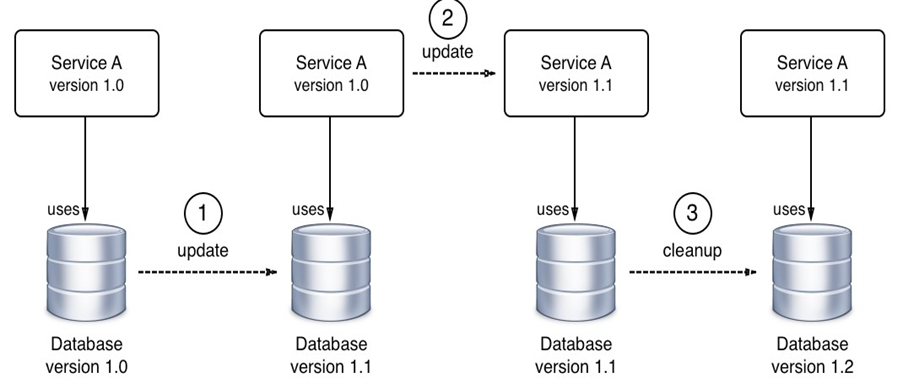
Déployer un changement irréversible de données ou de schéma
Rollback
Si nous avons des mises à jour fréquentes de nos services d’application qui s’exécutent en production, tôt ou tard, il y aura un problème avec l’une de ces mises à jour. Peut-être qu’un développeur, tout en corrigeant un bogue, en a introduit un nouveau, qui n’a pas été détecté par tous les tests automatisés, et peut-être manuels, donc l’application se comporte mal et il est impératif que nous rétablissions le service à la bonne version précédente. À cet égard, une restauration est une reprise après une catastrophe.
Encore une fois, dans une architecture d’application distribuée, il ne s’agit pas de savoir si un retour en arrière ne sera jamais nécessaire, mais plutôt quand un retour en arrière devra se produire. Ainsi, nous devons absolument être sûrs que nous pouvons toujours revenir à une version précédente de tout service qui compose notre application. Les annulations ne peuvent pas être une réflexion après coup, mais doivent être une partie testée et éprouvée de notre processus de déploiement.
Si nous utilisons des déploiements bleu-vert pour mettre à jour nos services, les restaurations devraient être assez simples. Tout ce que nous devons faire est de basculer le routeur de la nouvelle version verte du service vers la version bleue précédente.
Résumé
Dans ce chapitre, nous avons appris ce qu’est une architecture d’application distribuée et quels modèles et meilleures pratiques sont utiles ou nécessaires pour exécuter avec succès une application distribuée. Enfin, nous avons discuté de ce qui est nécessaire en plus d’exécuter une telle application en production.
Dans le prochain chapitre, nous allons plonger dans la mise en réseau limitée à un seul hôte. Nous allons discuter en détail comment les conteneurs vivant sur le même hôte peuvent communiquer entre eux et comment les clients externes peuvent accéder aux applications conteneurisées si nécessaire.
Questions
Veuillez répondre aux questions suivantes pour évaluer votre compréhension du contenu de ce chapitre.
1. Quand et pourquoi chaque partie d’une architecture d’application distribuée doit-elle être redondante ? Expliquez en quelques phrases courtes.
2. Pourquoi avons-nous besoin de services DNS ? Expliquez-en 3 à 5 phrases.
3. Qu’est-ce qu’un disjoncteur et pourquoi est-il nécessaire ?
4. Quelles sont les différences importantes entre une application monolithique et une application distribuée ou multiservice ?
5. Qu’est-ce qu’un déploiement bleu-vert ?
Réseau à hôte unique
Dans le dernier chapitre, nous avons découvert les modèles architecturaux les plus importants et les meilleurs pratiques utilisés lors du traitement d’une architecture d’application distribuée.
Dans ce chapitre, nous présenterons le modèle de mise en réseau de conteneurs Docker et son implémentation sur un seul hôte sous la forme d’un réseau en pont. Ce chapitre présente également le concept de réseaux définis par logiciel et comment ils sont utilisés pour sécuriser les applications conteneurisées. Enfin, il montre comment les ports à conteneurs peuvent être ouverts au public et rendre ainsi les composants conteneurisés accessibles au monde extérieur.
Ce chapitre contiendra les rubriques suivantes :
- Le modèle de réseau de conteneurs
- Pare-feu réseau
- Le réseau de ponts
- Le réseau hôte
- Le réseau nul
- Exécution dans un espace de noms de réseau existant
- Gestion des ports
Après avoir terminé ce module, vous pourrez effectuer les opérations suivantes :
- Rédiger le modèle de mise en réseau de conteneurs – avec tous les composants essentiels sur un tableau blanc
- Créer et supprimer un réseau de ponts personnalisé
- Exécuter un conteneur attaché à un réseau de pont personnalisé
- Inspecter un réseau de ponts
- Isolez les conteneurs les uns des autres en les exécutant sur différents réseaux de ponts
- Publier un port conteneur sur un port hôte de votre choix
Exigences techniques
Pour ce chapitre, la seule chose dont vous aurez besoin est un hôte Docker capable d’exécuter des conteneurs Linux. Vous pouvez utiliser votre ordinateur portable avec Docker pour Mac ou Windows ou Docker Toolbox installé.
Le modèle de réseau de conteneurs
Jusqu’à présent, nous avons travaillé avec des conteneurs simples. Mais en réalité, une application métier conteneurisée se compose de plusieurs conteneurs qui doivent collaborer pour atteindre un objectif. Par conséquent, nous avons besoin d’un moyen pour les conteneurs individuels de communiquer entre eux. Ceci est réalisé en établissant des voies que nous pouvons utiliser pour envoyer des paquets de données dans les deux sens entre les conteneurs. Ces voies sont appelées réseaux . Docker a défini un modèle de mise en réseau très simple, appelé modèle de réseau de conteneurs ( CNM ), pour spécifier les exigences que tout logiciel qui implémente un réseau de conteneurs doit satisfaire. Voici une représentation graphique du CNM :

Le CNM comprend trois éléments : sandbox, point de terminaison et réseau :
- Sandbox : le bac à sable isole parfaitement un conteneur du monde extérieur. Aucune connexion réseau entrante n’est autorisée dans le conteneur en bac à sable. Pourtant, il est très peu probable qu’un conteneur ait une quelconque valeur dans un système si aucune communication avec lui n’est possible. Pour contourner cela, nous avons l’élément numéro deux, qui est le point final.
- Point de terminaison : un point de terminaison est une passerelle contrôlée du monde extérieur vers le bac à sable du réseau qui protège le conteneur. Le point de terminaison connecte le sandbox du réseau (mais pas le conteneur) au troisième élément du modèle, qui est le réseau.
- Réseau : le réseau est la voie qui transporte les paquets de données d’une instance de communication d’un point d’extrémité à un autre, ou finalement d’un conteneur à un autre.
Il est important de noter qu’un sandbox réseau peut avoir de zéro à de nombreux points de terminaison, ou, dit différemment, chaque conteneur vivant dans un sandbox réseau peut être attaché à aucun réseau du tout ou il peut être attaché à plusieurs réseaux différents en même temps. Dans le diagramme précédent, le milieu des trois sandbox du réseau est attaché aux deux réseaux 1 et 2 via un point d’extrémité respectif.
Ce modèle de mise en réseau est très générique et ne spécifie pas où les conteneurs individuels qui communiquent entre eux s’exécutent sur un réseau. Tous les conteneurs pourraient, par exemple, s’exécuter sur un seul et même hôte (local) ou être répartis sur un cluster d’hôtes (global).
Bien sûr, le CNM n’est qu’un modèle décrivant le fonctionnement du réseautage entre les conteneurs. Pour pouvoir utiliser la mise en réseau avec nos conteneurs, nous avons besoin de véritables implémentations du CNM. Pour la portée locale et globale, nous avons plusieurs implémentations du CNM. Dans le tableau suivant, nous donnons un bref aperçu des implémentations existantes et de leurs principales caractéristiques. La liste n’a pas d’ordre particulier :
| Network | Company | Scope | Description |
| Bridge | Docker | Local | Simple network based on Linux bridges allowing networking on a single host |
| Macvlan | Docker | Local | Configures multiple layer 2 (that is, MAC) addresses on a single physical host interface |
| Overlay | Docker | Global | Multinode-capable container network based on Virtual Extensible LAN (VXLan) |
| Weave Net | Weaveworks | Global | Simple, resilient, multihost Docker networking |
| Contiv Network Plugin | Cisco | Global | Open source container networking |
Tous les types de réseaux non directement fournis par Docker peuvent être ajoutés à un hôte Docker en tant que plug-in.
Pare-feu réseau
Docker a toujours eu le mantra de la sécurité en premier. Cette philosophie a eu une influence directe sur la conception et la mise en œuvre de la mise en réseau dans un environnement Docker unique et multi hôte. Les réseaux définis par logiciel sont faciles et peu coûteux à créer, et pourtant ils pare-feu parfaitement les conteneurs qui sont attachés à ce réseau à partir d’autres conteneurs non attachés et du monde extérieur. Tous les conteneurs appartenant au même réseau peuvent communiquer librement entre eux, tandis que d’autres n’ont aucun moyen de le faire :
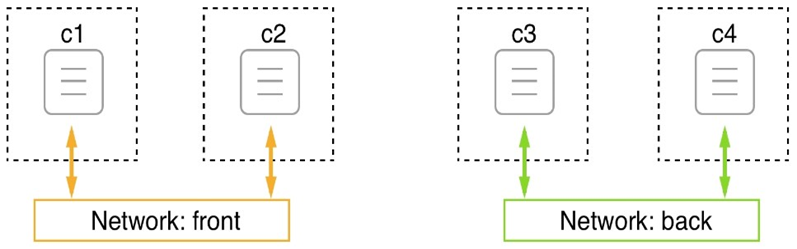
15/5000
Réseaux Docker
Dans le schéma précédent, nous avons deux réseaux appelés avant et arrière. Attachés au réseau avant, nous avons des conteneurs c1 et c2, et attachés au réseau arrière, nous avons des conteneurs c3 et c4. c1 et c2 peuvent communiquer librement l’un avec l’autre, tout comme c3 et c4 . Mais c1 et c2 n’ont aucun moyen de communiquer avec c3 ou c4, et vice versa.
Maintenant que la situation où nous avons une application composée de trois services, WebAPI , ProductCatalog et base de données ? Nous voulons que webAPI puisse communiquer avec productCatalog, mais pas avec la base de données, et nous voulons que productCatalog puisse communiquer avec le service de base de données. Nous pouvons résoudre cette situation en plaçant WebAPI et la base de données sur les différents réseaux et attacher ProductCatalog à ces deux réseaux, comme le montre le schéma suivant :
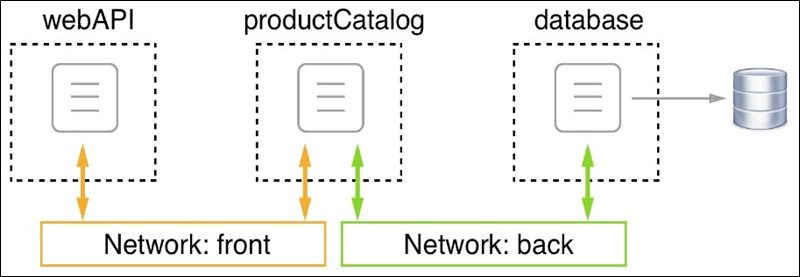
Conteneur attaché à plusieurs réseaux
Étant donné que la création de SDN est bon marché et que chaque réseau offre une sécurité supplémentaire en isolant les ressources des accès non autorisés, il est fortement recommandé de concevoir et d’exécuter des applications afin qu’elles utilisent plusieurs réseaux et exécutent uniquement des services sur le même réseau qui ont absolument besoin de communiquer entre eux. Dans l’exemple précédent, il n’est absolument pas nécessaire que le composant API Web communique directement avec le service de base de données, nous les avons donc mis sur différents réseaux. Si le pire des cas se produit et qu’un pirate informatique compromet l’API Web, il n’a pas la possibilité d’accéder à la base de données à partir de là sans d’abord pirater également le service de catalogue de produits.
Le réseau de ponts
Le réseau de pont Docker est la première implémentation du modèle de réseau de conteneurs que nous allons examiner en détail. Cette implémentation réseau est basée sur le pont Linux. Lorsque le démon Docker s’exécute pour la première fois, il crée un pont Linux et l’appelle docker0. Il s’agit du comportement par défaut et peut être modifié en modifiant la configuration. Docker crée ensuite un réseau avec ce pont Linux et appelle le pont réseau. Tous les conteneurs que nous créons sur un hôte Docker et que nous ne lions pas explicitement à un autre réseau conduisent Docker à se connecter automatiquement à ce réseau de pont.
Pour vérifier que nous avons bien un réseau appelé bridge de type bridge défini sur notre hôte, nous pouvons lister tous les réseaux sur l’hôte avec la commande suivante :
$ docker network ls
Cela devrait fournir une sortie similaire à la suivante :

Dans votre cas, les ID seront différents, mais le reste de la sortie devrait être identique. Nous avons en effet un premier réseau appelé bridge utilisant le driver bridge. La portée étant locale signifie simplement que ce type de réseau est limité à un seul hôte et ne peut pas s’étendre sur plusieurs hôtes. Dans un chapitre ultérieur, nous discuterons également d’autres types de réseaux qui ont une portée globale, ce qui signifie qu’ils peuvent s’étendre sur des clusters d’hôtes entiers.
Voyons maintenant un peu plus en détail ce qu’est ce réseau de ponts. Pour cela, nous allons utiliser la commande Docker inspect :
$ docker network inspect bridge
Une fois exécuté, cela génère une grande quantité d’informations détaillées sur le réseau en question. Ces informations doivent ressembler à ceci :
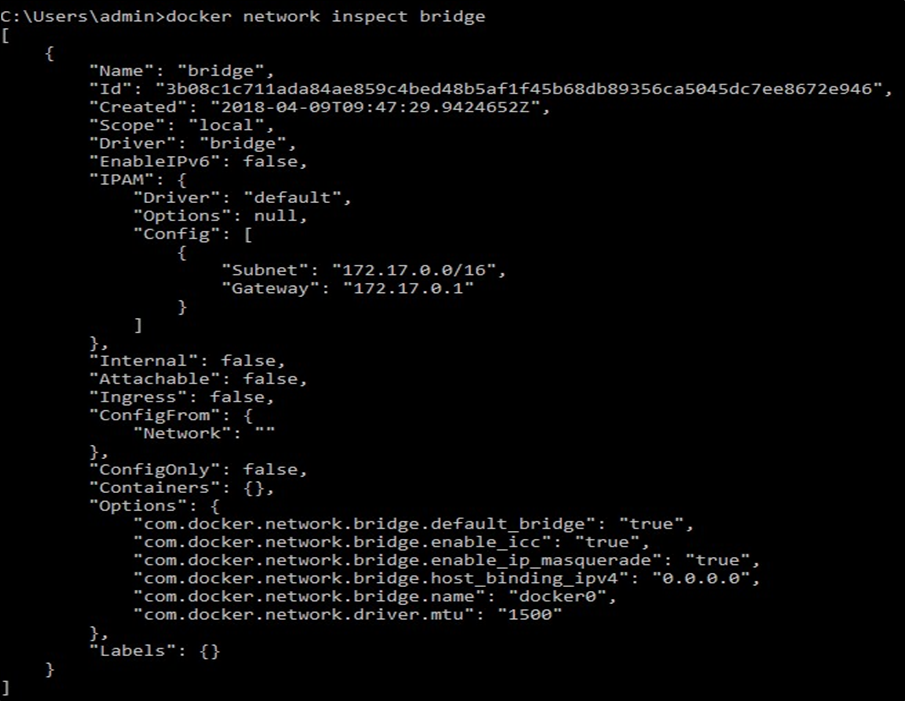
Sortie générée lors de l’inspection du réseau du pont Docker
Nous avons déjà vu les valeurs ID, Name, Driver et Scope lorsque nous avons répertorié tous les réseaux, ce n’est donc pas nouveau. Mais regardons le bloc de gestion des adresses IP ( IPAM ). IPAM est un logiciel utilisé pour suivre les adresses IP utilisées sur un ordinateur. La partie importante du bloc IPAM est le nœud Config avec ses valeurs pour Subnet et Gateway. Le sous-réseau du réseau en pont est défini par défaut comme 172.17.0.0/16.
Cela signifie que tous les conteneurs attachés à ce réseau obtiendront une adresse IP attribuée par Docker qui est prise dans la plage donnée, qui est 172.17.0.2 à 172.17.255.255. L’adresse 172.17.0.1 est réservée au routeur de ce réseau dont le rôle dans ce type de réseau est pris en charge par le pont Linux. On peut s’attendre à ce que le tout premier conteneur qui sera attaché à ce réseau par Docker obtienne le 172.17.0.2 adresse. Tous les conteneurs suivants recevront un nombre plus élevé ; le schéma suivant illustre ce fait :
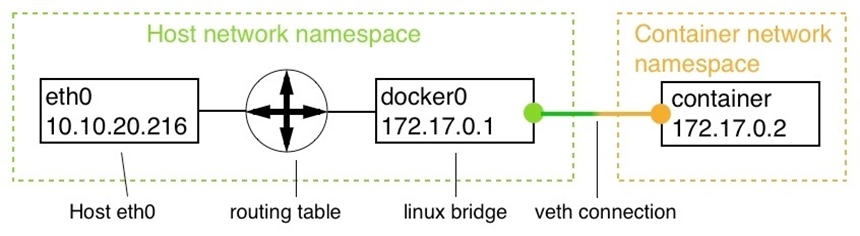
Le réseau des ponts
Dans le diagramme précédent, nous pouvons voir l’espace de noms réseau de l’hôte, qui inclut le point de terminaison eth0 de l’hôte, qui est généralement une carte réseau si l’hôte Docker s’exécute sur du métal nu ou une carte réseau virtuelle si l’hôte Docker est une machine virtuelle. Tout le trafic vers l’hôte passe par eth0. Le pont Linux est responsable du routage du trafic réseau entre le réseau de l’hôte et le sous-réseau du réseau de pont.
Par défaut, seul le trafic provenant de la sortie est autorisé et toute entrée est bloquée. Cela signifie que si les applications conteneurisées peuvent atteindre Internet, elles ne peuvent pas être atteintes par le trafic extérieur. Chaque conteneur attaché au réseau obtient sa propre connexion Ethernet virtuelle ( veth ) avec le pont. Ceci est illustré dans le diagramme suivant :
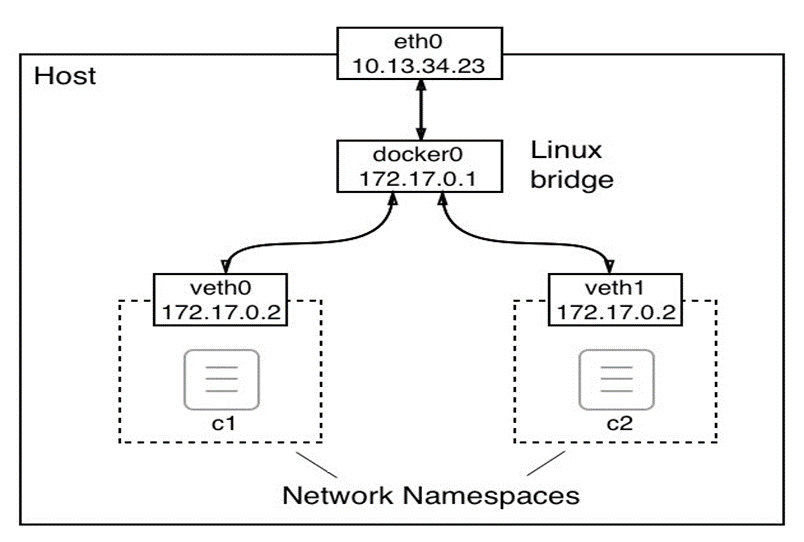
Détails du réseau de ponts
Le schéma précédent nous montre le monde du point de vue de l’hôte. Nous explorerons à quoi ressemble la situation depuis un conteneur plus loin dans cette section.
Nous ne sommes pas limités au seul réseau de ponts, car Docker nous permet de définir nos propres réseaux de ponts personnalisés. Ce n’est pas seulement une fonctionnalité intéressante, mais il est recommandé de ne pas exécuter tous les conteneurs sur le même réseau, mais d’utiliser des réseaux de ponts supplémentaires pour isoler davantage les conteneurs qui n’ont pas besoin de communiquer entre eux. Pour créer un réseau de ponts personnalisé appelé samplenet , utilisez la commande suivante:
$ docker network create –driver bridge sample-net
Si nous le faisons, nous pouvons ensuite inspecter le sous-réseau Docker créé pour ce nouveau réseau personnalisé comme suit :
$ docker network inspect sample-net | grep Subnet
Cela renvoie la valeur suivante :
“Subnet”: “172.18.0.0/16”,
De toute évidence, Docker vient d’attribuer le prochain bloc gratuit d’adresses IP à notre nouveau réseau de ponts personnalisé. Si, pour une raison quelconque, nous voulons spécifier notre propre plage de sous-réseaux lors de la création d’un réseau, nous pouvons le faire en utilisant le paramètre –subnet :
$ docker network create –driver bridge –subnet “10.1.0.0/16” test-net
Pour éviter les conflits dus aux adresses IP en double, veillez à ne pas créer de réseaux avec des sous-réseaux qui se chevauchent.
Maintenant que nous avons discuté de ce qu’est un réseau de pont et comment créer un réseau de pont personnalisé, nous voulons comprendre comment attacher des conteneurs à ces réseaux. Tout d’abord, exécutons de manière interactive un conteneur Alpine sans spécifier le réseau à attacher :
$ docker container run –name c1 -it –rm alpine:latest /bin/sh
Dans une autre fenêtre de terminal, examinons le conteneur c1 :
$ docker container inspect c1
Dans la vaste production, concentrons-nous un instant sur la partie qui fournit des informations liées au réseau. Il se trouve sous le nœud NetworkSettings. Je l’ai répertorié dans la sortie suivante :
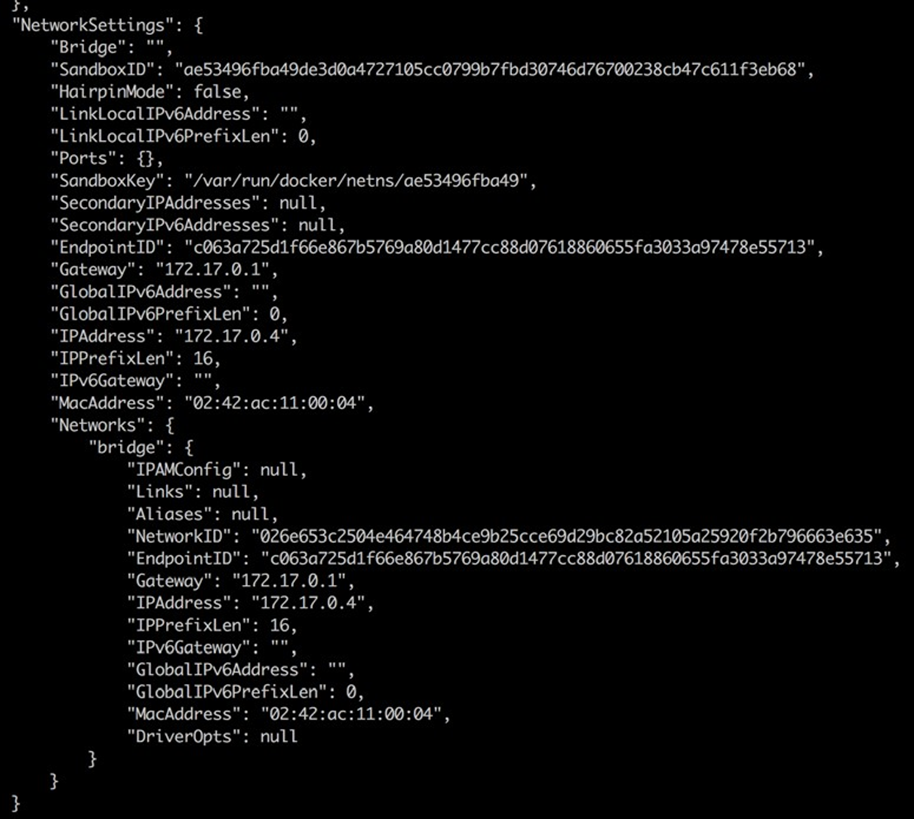
Section des paramètres réseau des métadonnées du conteneur
Dans la sortie précédente, nous pouvons voir que le conteneur est en effet attaché au réseau de pont puisque le NetworkID est égal à 026e65 …, ce que nous pouvons voir dans le code précédent est l’ID du réseau de pont. Nous pouvons également voir que le conteneur a obtenu l’adresse IP de 172.17.0.4 attribuée comme prévu et que la passerelle est à 172.17.0.1. Veuillez noter que le conteneur avait également un MacAddress associé avec. Ceci est important car le pont Linux utilise l’adresse Mac pour le routage.
Jusqu’à présent, nous l’avons abordé de l’extérieur de l’espace de noms réseau du conteneur. Voyons maintenant à quoi ressemble la situation lorsque nous ne sommes pas seulement à l’intérieur du conteneur, mais à l’intérieur de l’espace de noms réseau du conteneur. À l’intérieur du conteneur c1, utilisons l’outil ip pour inspecter ce qui se passe. Exécutez la commande ip addr et observez la sortie générée comme suit :
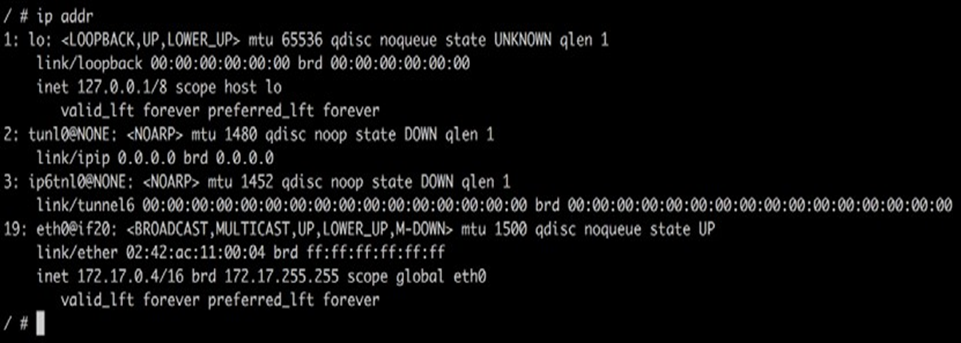
La partie intéressante de la sortie précédente est le nombre 19, le point de terminaison eth0 . Le point de terminaison veth0 que le pont Linux a créé en dehors de l’espace de noms du conteneur est mappé sur eth0 à l’intérieur du conteneur. Docker mappe toujours le premier point de terminaison d’un espace de noms de réseau de conteneurs à eth0, comme vu de l’intérieur de l’espace de noms. Si l’espace de noms du réseau est attaché à un réseau supplémentaire, ce point de terminaison sera mappé sur eth1, etc.
Étant donné qu’à ce stade, nous ne sommes pas vraiment intéressés par un autre point de terminaison que eth0, nous aurions pu utiliser une variante plus spécifique de la commande, qui nous aurait donné les éléments suivants :
/ # ip addr show eth0
195: eth0@if196: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether 02:42:ac:11:00:02 brd
ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope
global eth0
valid_lft forever preferred_lft forever.
Dans la sortie, nous pouvons également voir quelle adresse MAC (02: 42: ac: 11: 00: 02) et quelle IP ( 172.17.0.2 ) ont été associées à cet espace de noms de réseau de conteneurs par Docker.
Nous pouvons également obtenir des informations sur la façon dont les demandes sont acheminées en utilisant la commande ip route :
/ # ip route default via 172.17.0.1 dev eth0 172.17.0.0/16 dev eth0 scope link src 172.17.0.2
Cette sortie nous indique que tout le trafic vers la passerelle à 172.17.0.1 est acheminé via le périphérique eth0.
Maintenant, exécutons un autre conteneur appelé c2 sur le même réseau :
$ docker container run –name c2 -d alpine:latest ping 127.0.0.1
Le conteneur c2 sera également attaché au réseau de pont, car nous n’avons spécifié aucun autre réseau. Son adresse IP sera la prochaine libre du sous-réseau, qui est 172.17.0.3, comme nous pouvons facilement le tester :
$ docker container inspect –format “{{.NetworkSettings.IPAddress}}” c2
172.17.0.3
Maintenant, nous avons deux conteneurs attachés au réseau de ponts. Nous pouvons essayer d’inspecter à nouveau ce réseau pour trouver une liste de tous les conteneurs qui lui sont attachés dans la sortie :
$ docker network inspect bridge
Les informations se trouvent sous le nœud Conteneurs :
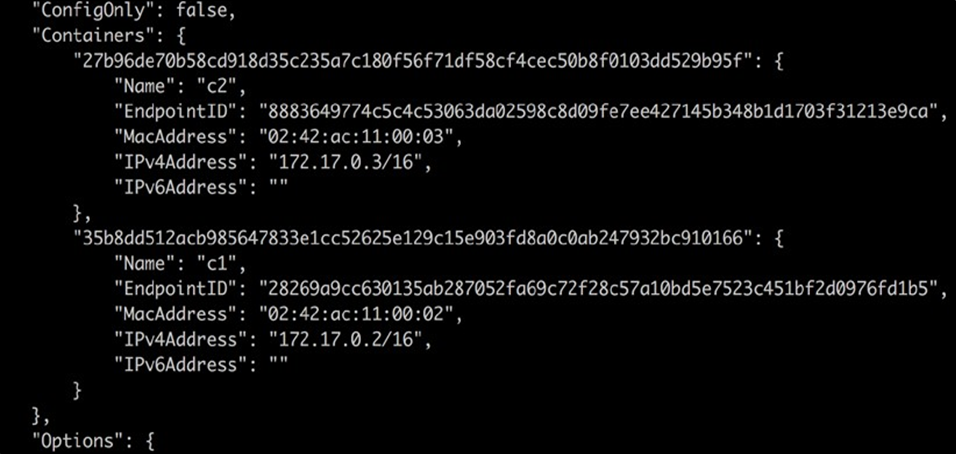
La section conteneurs de la sortie du réseau docker inspecte le pont
Encore une fois, nous avons raccourci la sortie à l’essentiel pour la lisibilité.
Maintenant, créons deux conteneurs supplémentaires, c3 et c4, et attachons-les au testnet . Pour cela, nous utilisons le paramètre –network:
$ docker container run –name c3 -d –network test-net \ alpine:latest ping 127.0.0.1 $ docker container run –name c4 -d –network test-net \ alpine:latest ping 127.0.0.1
Inspectons le réseau test-net et confirmons que les conteneurs c3 et c4 y sont bien attachés:
$ docker network inspect test-net
Cela nous donnera la sortie suivante pour la section Conteneurs :
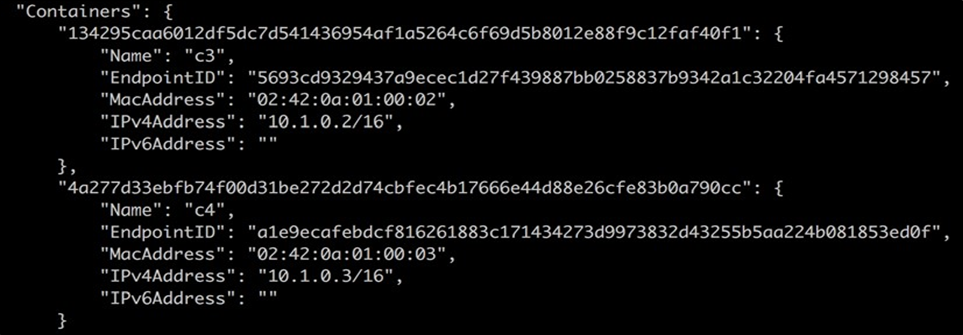
La section Conteneurs de la commande Docker Network inspecte Test-Net
La question suivante que nous allons nous poser est de savoir si les deux conteneurs c3 et c4 peuvent communiquer librement entre eux. Pour démontrer que c’est effectivement le cas, nous pouvons exécuter dans le conteneur c3 :
$ docker container exec -it c3 /bin/sh
Une fois à l’intérieur du conteneur, nous pouvons essayer d’envoyer une requête ping au conteneur c4 par nom et par adresse IP :
/ # ping c4
PING c4 (10.1.0.3): 56 data bytes
64 bytes from 10.1.0.3: seq=0 ttl=64 time=0.192 ms
64 bytes from 10.1.0.3: seq=1 ttl=64 time=0.148 ms …
Ce qui suit est le résultat du ping utilisant l’adresse IP du conteneur c4 :
/ # ping 10.1.0.3
PING 10.1.0.3 (10.1.0.3): 56 data bytes
64 bytes from 10.1.0.3: seq=0 ttl=64 time=0.200 ms
64 bytes from 10.1.0.3: seq=1 ttl=64 time=0.172 ms …
La réponse dans les deux cas nous confirme que la communication entre conteneurs attachés au même réseau fonctionne comme prévu. Le fait que nous puissions même utiliser le nom du conteneur auquel nous voulons nous connecter nous montre que la résolution de nom fournie par le service Docker DNS fonctionne à l’intérieur de ce réseau.
Maintenant, nous voulons nous assurer que le pont et les réseaux test-net sont pare-feu l’un de l’autre. Pour illustrer cela, nous pouvons essayer d’envoyer une requête ping au conteneur c2 à partir du conteneur c3, soit par son nom, soit par son adresse IP :
/ # ping c2 ping: bad address ‘c2’
Voici le résultat du ping utilisant à la place l’adresse IP du conteneur cible c2 :
/ # ping 172.17.0.3
PING 172.17.0.3 (172.17.0.3): 56 data bytes
^C
— 172.17.0.3 ping statistics —
43 packets transmitted, 0 packets received, 100% packet loss
La commande précédente est restée suspendue et je dû mettre fin à la commande avec Ctrl + C . De la réponse au ping c2 , nous pouvons également voir que la résolution de nom ne fonctionne pas sur les réseaux. C’est le comportement attendu. Les réseaux fournissent une couche supplémentaire d’isolement, et donc de sécurité, aux conteneurs.
Plus tôt, nous avons appris qu’un conteneur peut être attaché à plusieurs réseaux. Attachons un conteneur c5 aux réseaux sample-net et test-net en même temps :
$ docker container run –name c5 -d \
–network sample-net \ –network test-net \ alpine:latest ping 127.0.0.1
Nous pouvons alors tester que c5 est accessible à partir du conteneur c2 de la même manière que lorsque nous avons testé la même chose pour les conteneurs c4 et c2. Le résultat montrera que la connexion fonctionne bien.
Si nous voulons supprimer un réseau existant, nous pouvons utiliser la commande docker network rm, mais notez que l’on ne peut pas supprimer accidentellement un réseau auquel des conteneurs sont attachés :
$ docker network rm test-net
Error response from daemon: network test-net id 863192… has active endpoints
Avant de continuer, nettoyons et retirons tous les conteneurs :
$ docker container rm -f $(docker container ls -aq)
Ensuite, nous supprimons les deux réseaux personnalisés que nous avons créés :
$ docker network rm sample-net
$ docker network rm test-net
Le réseau hôte
Il existe des occasions où nous voulons exécuter un conteneur dans l’espace de noms réseau de l’hôte. Cela peut être nécessaire lorsque nous devons exécuter certains logiciels dans un conteneur utilisé pour analyser ou déboguer le trafic du réseau hôte. Mais gardez à l’esprit que ce sont des scénarios très spécifiques. Lors de l’exécution de logiciels d’entreprise dans des conteneurs, il n’y a aucune bonne raison d’exécuter les conteneurs respectifs attachés au réseau de l’hôte. Pour des raisons de sécurité, il est fortement recommandé de ne pas exécuter un tel conteneur attaché au réseau hôte dans un environnement de production ou de type production.
Cela dit, comment pouvons-nous exécuter un conteneur à l’intérieur de l’espace de noms réseau de l’hôte? En attachant simplement le conteneur au réseau hôte :
$ docker container run –rm -it –network host alpine:latest /bin/ sh
Si nous utilisons maintenant l’outil ip pour analyser l’espace de noms du réseau à partir du conteneur, nous verrons que nous obtenons exactement la même image que si nous exécutions l’outil ip directement sur l’hôte. Par exemple, si j’inspecte le périphérique eth0 sur mon hôte, j’obtiens ceci :
/ # ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_ fast state UP qlen 1000 link/ether 02:50:00:00:00:01 brd
ff:ff:ff:ff:ff:ff
inet 192.168.65.3/24 brd 192.168.65.255 scope
global eth0
valid_lft forever preferred_lft forever
inet6 fe80::c90b:4219:ddbd:92bf/64 scope link
valid_lft forever preferred_lft forever
Ici, je trouve que 192.168.65.3 est l’adresse IP à laquelle l’hôte a été attribué et que l’adresse MAC indiquée ici correspond également à celle de l’hôte.
Nous pouvons également inspecter les itinéraires pour obtenir les éléments suivants (raccourcis):
/ # ip route default via 192.168.65.1 dev eth0 src 192.168.65.3 metric 202 10.1.0.0/16 dev cni0 scope link src 10.1.0.1
127.0.0.0/8 dev lo scope host
172.17.0.0/16 dev docker0 scope link src 172.17.0.1
…
192.168.65.0/24 dev eth0 scope link src 192.168.65.3 metric 202
Avant de vous laisser passer à la section suivante de ce chapitre, je tiens à souligner une fois de plus que l’utilisation du réseau hôte est dangereuse et doit être évitée si possible.
Le réseau nul
Parfois, nous devons exécuter quelques services d’application ou travaux qui ne nécessitent aucune connexion réseau pour exécuter la tâche. Il est fortement conseillé d’exécuter ces applications dans un conteneur attaché au réseau none. Ce conteneur sera complètement isolé et donc à l’abri de tout accès extérieur. Lançons un tel conteneur :
$ docker container run –rm -it –network none alpine:latest /bin/ sh
Une fois à l’intérieur du conteneur, nous pouvons vérifier qu’aucun point de terminaison réseau eth0 n’est disponible :
/ # ip addr show eth0 ip: can’t find device ‘eth0’
Il n’y a également aucune information de routage disponible, comme nous pouvons le démontrer en utilisant la commande suivante :
/ # ip route
Cela ne renvoie rien.
Exécution dans un espace de noms de réseau existant
Normalement, Docker crée un nouvel espace de noms réseau pour chaque conteneur que nous exécutons. L’espace de noms réseau du conteneur correspond au bac à sable du modèle de réseau de conteneurs que nous avons décrit précédemment. Lorsque nous attachons le conteneur à un réseau, nous définissons un point de terminaison qui connecte l’espace de noms du réseau de conteneurs au réseau réel. De cette façon, nous avons un conteneur par espace de noms réseau.
Docker fournit un moyen supplémentaire de définir l’espace de noms réseau dans lequel s’exécute un conteneur. Lors de la création d’un nouveau conteneur, nous pouvons spécifier qu’il doit être attaché à ou peut-être devrions-nous dire inclus dans l’espace de noms réseau d’un conteneur existant. Avec cette technique, nous pouvons exécuter plusieurs conteneurs dans un même espace de noms de réseau :
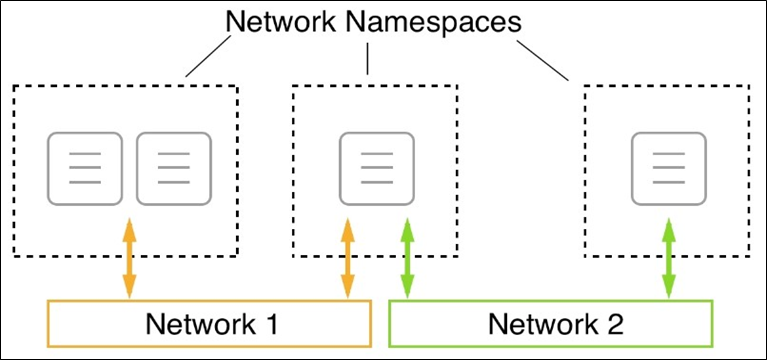
Plusieurs conteneurs s’exécutant dans un seul espace de noms de réseau
Dans le diagramme précédent, nous pouvons voir que dans l’espace de noms de réseau le plus à gauche, nous avons deux conteneurs. Les deux conteneurs, puisqu’ils partagent le même espace de noms, peuvent communiquer entre eux sur localhost. L’espace de noms du réseau (et non les conteneurs individuels) est ensuite attaché au réseau 1.
Cela est utile lorsque nous voulons déboguer le réseau d’un conteneur existant sans exécuter de processus supplémentaires à l’intérieur de ce conteneur. Nous pouvons simplement attacher un conteneur utilitaire spécial à l’espace de noms réseau du conteneur à inspecter. Cette fonctionnalité est également utilisée par Kubernetes lorsqu’il crée un module. Nous en apprendrons davantage sur Kubernetes et les pods dans les chapitres suivants de cet article.
Maintenant, montrons comment cela fonctionne.
1. Premièrement, nous créons un nouveau réseau de ponts :
$ docker network create –driver bridge test-net
2. Ensuite, nous exécutons un conteneur attaché à ce réseau :
$ docker container run –name web -d –network test-net nginx:alpine
3. Enfin, nous exécutons un autre conteneur et le connectons au réseau de notre conteneur Web :
$ docker container run -it –rm –network container:web alpine:latest /bin/sh
Plus précisément, notez comment nous définissons le réseau : – conteneur réseau : web. Cela indique à Docker que notre nouveau conteneur doit utiliser le même espace de noms réseau que le conteneur appelé web.
Étant donné que le nouveau conteneur se trouve dans le même espace de noms réseau que le conteneur Web exécutant Nginx, nous pouvons désormais accéder à Nginx sur localhost ! Nous pouvons le prouver en utilisant l’outil wget, qui fait partie du conteneur Alpine, pour se connecter à Nginx. Nous devrions voir ce qui suit :
/ # wget -qO – localhost
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title> …
</html>
Notez que nous avons raccourci la sortie pour plus de lisibilité. Veuillez également noter qu’il existe une différence importante entre l’exécution de deux conteneurs attachés au même réseau et deux conteneurs s’exécutant dans le même espace de noms de réseau. Dans les deux cas, les conteneurs peuvent communiquer librement entre eux, mais dans ce dernier cas, la communication se fait via localhost.
Pour nettoyer le conteneur et le réseau, nous pouvons utiliser la commande suivante :
$ docker container rm –force web
$ docker network rm test-net
Gestion des ports
Maintenant que nous savons comment isoler ou pare-feu les conteneurs les uns des autres en les plaçant sur différents réseaux, et que nous pouvons avoir un conteneur attaché à plusieurs réseaux, nous avons un problème qui reste non résolu. Comment exposer un service d’application au monde extérieur ? Imaginez un conteneur exécutant un serveur Web hébergeant notre webAPI d’avant. Nous voulons que les clients d’Internet puissent accéder à cette API. Nous l’avons conçu pour être une API accessible au public. Pour y parvenir, nous devons, au sens figuré, ouvrir une porte dans notre pare-feu à travers laquelle nous pouvons acheminer le trafic externe vers notre API. Pour des raisons de sécurité, nous ne voulons pas simplement ouvrir les portes grandes, mais avoir une seule porte contrôlée à travers laquelle le trafic circule.
Nous pouvons créer une telle porte en mappant un port de conteneur à un port disponible sur l’hôte. Nous appelons également ce port à conteneurs pour publier un port. N’oubliez pas que le conteneur possède sa propre pile de réseau virtuel, tout comme l’hôte. Par conséquent, les ports conteneurs et les ports hôtes existent de manière totalement indépendante et n’ont par défaut rien en commun. Mais nous pouvons désormais câbler un port conteneur avec un port hôte gratuit et canaliser le trafic externe via ce lien, comme illustré dans la capture d’écran suivante :
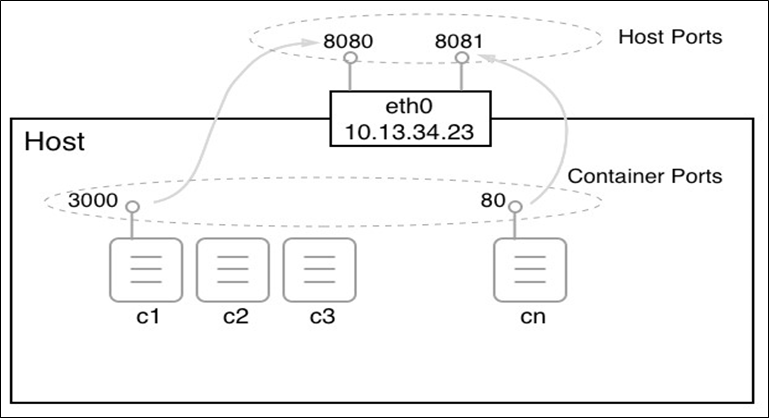
Mappage des ports de conteneurs aux ports hôtes
Mais maintenant, il est temps de montrer comment on peut réellement mapper un port conteneur à un port hôte. Cela se fait lors de la création d’un conteneur. Nous avons différentes manières de procéder :
- Premièrement, nous pouvons laisser Docker décider du port hôte auquel notre port de conteneur doit être mappé. Docker sélectionnera alors l’un des ports hôtes libres dans la plage de 32xxx. Ce mappage automatique est effectué en utilisant leparamètre -P :
$ docker container run –name web -P -d nginx:alpine
La commande précédente exécute un serveur Nginx dans un conteneur. Nginx écoute au port 80 à l’intérieur du conteneur. Avec le paramètre -P, nous demandons à Docker de mapper tous les ports de conteneur exposés à un port libre dans la plage 32xxx. Nous pouvons découvrir quel port hôte Docker utilise en utilisant la commande docker container port : $ docker container port web
80/tcp -> 0.0.0.0:32768
Le conteneur Nginx expose uniquement le port 80, et nous pouvons voir qu’il a été mappé sur le port hôte 32768. Si nous ouvrons une nouvelle fenêtre de navigateur et accédons à localhost : 32768, nous devrions voir la capture d’écran suivante :
La page d’accueil de Nginx
- Une autre façon de savoir quel port hôte Docker utilise pour notre conteneur est de l’inspecter. Le port hôte fait partie du nœud NetworkSettings :
$ docker container inspect web | grep HostPort
“HostPort”: “32768”
- Enfin, la troisième façon d’obtenir ces informations consiste à répertorier le conteneur :
$ docker container ls
CONTAINER ID IMAGE …
PORTS NAMES
56e46a14b6f7 nginx:alpine … 0.0.0.0:32768->80/tcp web
Veuillez noter que dans la sortie précédente, la partie / tcp nous indique que le port a été ouvert pour la communication avec le protocole TCP, mais pas pour le protocole UDP. TCP est la valeur par défaut, et si nous voulons spécifier que nous voulons ouvrir le port pour UDP, nous devons le spécifier explicitement. Le 0.0.0.0 dans le mappage nous indique que le trafic provenant de n’importe quelle adresse IP hôte peut désormais atteindre le port de conteneur 80 du conteneur Web.
Parfois, nous voulons mapper un port conteneur à un port hôte très spécifique. Nous pouvons le faire en utilisant le paramètre -p (ou –publish ). Voyons comment cela se fait avec la commande suivante :
$ docker container run –name web2 -p 8080:80 -d nginx:alpine
La valeur du paramètre -p se présente sous la forme <port hôte>: <port conteneur> .
Par conséquent, dans le cas précédent, nous mappons le port de conteneur 80 au port hôte 8080. Une fois le conteneur web2 exécuté, nous pouvons le tester dans le navigateur en accédant à localhost:8080, et nous devrions être accueillis par la même page d’accueil Nginx que nous avons vue dans l’exemple précédent qui traitait du mappage de port automatique.
Lorsque vous utilisez le protocole UDP pour la communication sur un certain port, le paramètre de publication ressemblera à -p 3000: 4321 / udp . Notez que si nous voulons autoriser la communication avec les protocoles TCP et UDP sur le même port, nous devons mapper chaque protocole séparément.
Résumé
Dans ce chapitre, nous avons appris comment les conteneurs fonctionnant sur un seul hôte peuvent communiquer entre eux. Nous avons d’abord examiné le CNM qui définit les exigences d’un réseau de conteneurs, puis nous avons examiné plusieurs implémentations du CNM, comme le réseau de ponts. Nous avons ensuite examiné en détail le fonctionnement du réseau de ponts et également le type d’informations que Docker nous fournit sur les réseaux et les conteneurs attachés à ces réseaux. Nous avons également appris à adopter deux perspectives différentes, à la fois à l’extérieur et à l’intérieur du conteneur.
Dans le chapitre suivant, nous allons présenter Docker Compose. Nous découvrirons comment créer une application composée de plusieurs services, chacun s’exécutant dans un conteneur, et comment Docker Compose nous permet de créer, d’exécuter et de mettre à l’échelle facilement une telle application en utilisant une approche déclarative.
Questions
Pour évaluer vos compétences, veuillez essayer de répondre aux questions suivantes :
- Nommez les trois éléments principaux du modèle de réseau de conteneurs (CNM).
- Comment allez-vous créer un réseau de ponts personnalisé appelé par exemple frontend ?
- Comment allez-vous exécuter deux conteneurs nginx: alpin attachés au réseau frontal.
- Pour le réseau frontal, obtenez les éléments suivants :
- IP de tous les conteneurs attachés.
- Le sous-réseau associé au réseau.
- Quel est l’objectif du réseau hôte ?
- Nommez un ou deux scénarios où l’utilisation du réseau hôte est appropriée.
- À quoi sert le réseau none ?
- Dans quels scénarios le réseau none doit-il être utilisé ?
Docker Compose
Dans le chapitre précédent, nous avons beaucoup appris sur le fonctionnement du réseau de conteneurs sur un seul hôte Docker. Nous avons introduit le modèle de réseau de conteneurs (CNM), qui constitue la base de toute mise en réseau entre les conteneurs Docker, puis nous nous sommes plongés dans les différentes implémentations du CNM, en particulier le réseau de ponts.
Ce chapitre présente le concept d’une application composée de plusieurs services, chacun s’exécutant dans un conteneur, et comment Docker Compose nous permet de créer, d’exécuter et de mettre à l’échelle facilement une telle application en utilisant une approche déclarative.
Le chapitre couvre les sujets suivants :
- Démystifier déclaratif contre impératif
- Exécution d’une application multiservice
- Mise à l’échelle d’un service
- Construire et pousser une application
Après avoir terminé ce chapitre, le lecteur pourra effectuer les opérations suivantes :
- Expliquer en quelques phrases courtes les principales différences entre une approche impérative et déclarative pour définir et exécuter une application
- Décrire dans leurs propres mots la différence entre un conteneur et un service Docker Compose
- Créez un fichier Docker Compose YAML pour une application multiservice simple
- Créez, envoyez, déployez et démontez une application multiservice simple à l’aide de Docker Compose
- Utilisez Docker Compose pour faire évoluer un service d’application de haut en bas
Exigences techniques
Le code accompagnant ce chapitre est disponible sur. https://github.com/appswithdockerandkubernetes/labs/tree/master/ch08.
Démystifier déclaratif contre impératif
Docker Compose est un outil fourni par Docker qui est principalement utilisé lorsque l’on a besoin d’exécuter et d’orchestrer des conteneurs fonctionnant sur un seul hôte Docker. Cela comprend, mais sans s’y limiter, le développement, l’intégration continue (CI), les tests automatisés et l’assurance qualité manuelle.
Docker Compose utilise des fichiers au format YAML en entrée. Par défaut, Docker Compose s’attend à ce que ces fichiers soient appelés docker-compose.yml, mais d’autres noms sont possibles. Le contenu d’un docker-compose.yml est censé être un moyen déclaratif de décrire et d’exécuter une application conteneurisée pouvant être constituée de plusieurs conteneurs.
Alors, quel est le sens de déclaratif ?
Tout d’abord, déclaratif est l’antonyme de l’impératif. Eh bien, cela n’aide pas beaucoup. Maintenant que j’ai introduit une autre définition, je dois expliquer les deux :
- Impératif : c’est un moyen de résoudre les problèmes en spécifiant la procédure exacte à suivre par le système.
Si je dis impérativement à un système tel que le démon Docker comment exécuter une application, cela signifie que je dois décrire étape par étape ce que le système doit faire et comment il doit réagir en cas de situation inattendue. Je dois être très explicite et précis dans mes instructions. Je dois couvrir tous les cas marginaux et la façon dont ils doivent être traités.
- Déclaratif : C’est une manière dont nous pouvons résoudre les problèmes sans exiger du programmeur qu’il spécifie une procédure exacte à suivre.
Une approche déclarative signifie que je dis au moteur Docker quel est mon état souhaité pour une application et qu’il doit déterminer par lui-même comment atteindre cet état souhaité et comment le réconcilier si le système s’en écarte.
Docker recommande clairement l’approche déclarative lors du traitement des applications conteneurisées. Par conséquent, l’outil Docker Compose utilise cette approche.
Exécution d’une application multiservice
Dans la plupart des cas, les applications ne se composent pas d’un seul bloc monolithique, mais plutôt de plusieurs services d’application qui fonctionnent ensemble. Lorsque vous utilisez des conteneurs Docker, chaque service d’application s’exécute dans son propre conteneur. Lorsque nous voulons exécuter une telle application multiservice, nous pouvons démarrer tous les conteneurs participants avec la commande bien connue Docker Container Run. Mais c’est au mieux inefficace. Avec l’outil Docker Compose, on nous donne un moyen de définir l’application de manière déclarative dans un fichier qui utilise le format YAML.
Voyons le contenu d’un simple fichier docker-compose.yml :
version: “3.5” services: web:
image: appswithdockerandkubernetes/ch08 web:1.0 ports: – 3000:3000 db:
image: appswithdockerandkubernetes/ch08-db:1.0 volumes: – pets-data:/var/lib/postgresql/data
volumes: pets-data:
Les lignes du fichier sont expliquées comme suit :
- version : dans cette ligne, nous spécifions la version du format Docker Compose que nous voulons utiliser. Au moment de la rédaction, il s’agit de la version 3.5.
- services : Dans cette section, nous spécifions les services qui composent notre application dans le bloc services . Dans notre exemple, nous avons deux services d’application et nous les appelons web et db :
° web : le service web utilise l’image appswithdockerandkubernetes / ch08-web: 1.0 depuis le Docker
Hub et publie le port de conteneur 3000 sur le port hôte, également 3000.
° db : Le service db , d’autre part, utilise l’image appswithdockerandkubernetes / ch08-db: 1.0 , qui est une base de données PostgreSQL personnalisée. Nous montons un volume appelé pets-data dans le conteneur du service db .
- volumes : les volumes utilisés par l’un des services doivent être déclarés dans cette section. Dans notre exemple, il s’agit de la dernière section du fichier. La première fois que l’application est exécutée, un volume appelé pets-data sera créé par Docker puis, lors des exécutions suivantes, si le volume est toujours là, il sera réutilisé. Cela peut être important lorsque l’application, pour une raison quelconque, se bloque et doit être redémarrée. Ensuite, les données précédentes sont toujours présentes et prêtes à être utilisées par le service de base de données redémarré.
Accédez au sous-dossier ch08 du dossier labs et démarrez l’application à l’aide de Docker Compose :
$ docker-compose up
Si nous entrons la commande précédente, l’outil supposera qu’il doit y avoir un fichier dans le répertoire courant appelé docker-compose.yml et il l’utilisera pour s’exécuter. Dans notre cas, c’est bien le cas et l’application va démarrer. Nous devrions voir la sortie comme suit :

Exécution de l’exemple d’application, partie 1
Exécution de l’exemple d’application, partie 2
La sortie précédente est expliquée comme suit :
- Dans la première partie de la sortie, nous pouvons voir comment Docker Compose tire les deux images qui constituent notre application. Ceci est suivi de la création d’un réseau ch08_default et d’un volume ch08_pets-data, suivis des deux conteneurs ch08_web_1 et ch08_db_1, un pour chaque service, web et db . Tous les noms sont automatiquement préfixés par Docker Compose avec le nom du répertoire parent, qui dans ce cas est appelé ch08.
- Après cela, nous voyons les journaux produits par les deux conteneurs. Chaque ligne de la sortie est commodément préfixée avec le nom du service, et la sortie de chaque service est dans une couleur différente. Ici, la part du lion est produite par la base de données et une seule ligne provient du service Web.
Nous pouvons maintenant ouvrir un onglet de navigateur et naviguer vers localhost:3000 / pet . Nous devrions être accueillis par une belle image de chat et quelques informations supplémentaires sur le conteneur dont il est issu, comme le montre la capture d’écran suivante :
L’exemple d’application dans le navigateur
Actualisez le navigateur plusieurs fois pour voir d’autres images de chat. L’application sélectionne l’image actuelle de manière aléatoire dans un ensemble de 12 images dont les URL sont stockées dans la base de données.
Comme l’application est en cours d’exécution en mode interactif et donc le terminal où nous avons couru Docker Compose est bloqué, nous pouvons annuler l’application en appuyant sur Ctrl + C. Si nous le faisons, nous verrons ce qui suit :
^CGracefully stopping… (press Ctrl+C again to force)
Stopping ch08_web_1 … done
Stopping ch08_db_1 … done
Nous remarquerons que le service de base de données s’arrête immédiatement tandis que le service Web prend environ 10 secondes pour le faire. La raison en est que le service de base de données écoute et réagit au signal SIGTERM envoyé par Docker alors que le service Web ne le fait pas, et donc Docker le tue après 10 secondes.
Si nous réexécutons l’application, la sortie sera beaucoup plus courte :
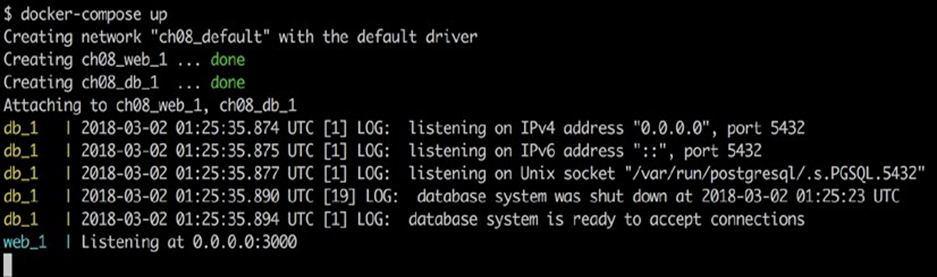
Sortie de docker-compose up
Cette fois, nous n’avons pas eu à télécharger les images et la base de données n’a pas eu à s’initialiser à partir de zéro, mais il s’agissait simplement de réutiliser les données qui étaient déjà présentes dans le volume pets-data de l’exécution précédente.
Nous pouvons également exécuter l’application en arrière-plan. Tous les conteneurs s’exécuteront en tant que démons. Pour cela, nous avons juste besoin d’utiliser le paramètre -d, comme indiqué dans le code suivant :
$ docker-compose up -d
Docker Compose nous offre beaucoup plus de commandes que simplement up. Nous pouvons l’utiliser pour lister tous les services qui font partie de l’application :
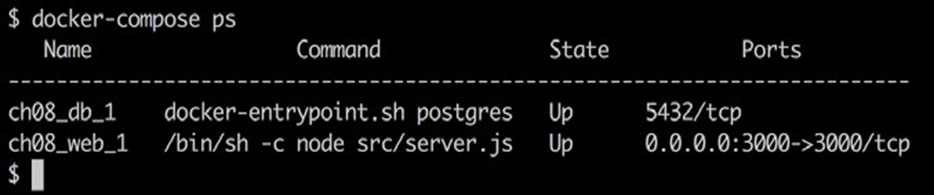
Sortie de docker-Compose ps
Cette commande est similaire à Docker Container LS, à la seule différence qu’elle répertorie uniquement les conteneurs qui font partie de l’application.
Pour arrêter et nettoyer l’application, nous utilisons la commande docker-compose down :
$ docker-compose down
Stopping ch08_web_1 … done
Stopping ch08_db_1 … done
Removing ch08_web_1 … done
Removing ch08_db_1 … done
Removing network ch08_default
Si nous voulons également supprimer le volume de la base de données, nous pouvons utiliser la commande suivante :
$ docker volume rm ch08_pets-data
Pourquoi y a-t-il un préfixe ch08 dans le nom du volume ? Dans le fichier docker-compose.yml, nous avons appelé le volume pour utiliser pets-data. Mais comme nous l’avons déjà mentionné, Docker Compose préfixe tous les noms avec le nom du dossier parent du fichier docker-compose.yml plus un trait de soulignement. Dans ce cas, le dossier parent est appelé ch08.
Mise à l’échelle d’un service
Supposons maintenant, un instant, que notre exemple d’application soit en direct sur le Web et connaisse un grand succès. Des tas de gens veulent voir nos images d’animaux mignons. Alors maintenant, nous sommes confrontés à un problème depuis que notre application a commencé à ralentir. Pour contrer ce problème, nous voulons exécuter plusieurs instances du service Web. Avec Docker Compose, cela se fait facilement.
L’exécution de plusieurs instances est également appelée mise à l’échelle. Nous pouvons utiliser cet outil pour faire évoluer notre service Web jusqu’à, disons, trois instances :
$ docker-compose up –scale web=3
Si nous faisons cela, nous serons surpris. La sortie ressemblera à la capture d’écran suivante:
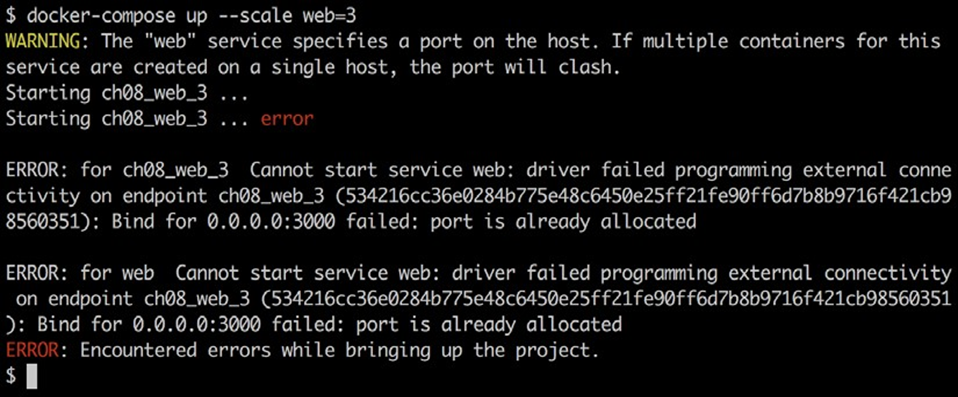
Sortie de docker-compose –scale
Les deuxième et troisième instance du service Web ne démarrent pas. Le message d’erreur nous explique pourquoi : nous ne pouvons pas utiliser le même port hôte plus d’une fois. Lorsque les instances 2 et 3 tentent de démarrer, Docker se rend compte que le port 3000 est déjà pris par la première instance. Que pouvons-nous faire ? Eh bien, nous pouvons simplement laisser Docker décider du port hôte à utiliser pour chaque instance.
Si, dans la section ports du fichier de composition, nous spécifions uniquement le port conteneur et omettons le port hôte, Docker sélectionne automatiquement un port éphémère. Faisons exactement ceci :
1. Tout d’abord, décomposons l’application :
$ docker-compose down
2. Ensuite, nous modifions le fichier docker-compose.yml pour qu’il se présente comme suit:
version: “3.5” services: web:
image: appswithdockerandkubernetes/ch08-web:1.0 ports: – 3000 db:
image: appswithdockerandkubernetes/ch08-db:1.0 volumes: – pets-data:/var/lib/postgresql/data
volumes: pets-data:
3. Maintenant, nous pouvons redémarrer l’application et la faire évoluer immédiatement après:
$ docker-compose up -d
$ docker-compose scale web=3
Starting ch08_web_1 … done
Creating ch08_web_2 … done
Creating ch08_web_3 … done
4. Si nous faisons maintenant un ps de composition de docker , nous devrions voir la capture d’écran suivante:
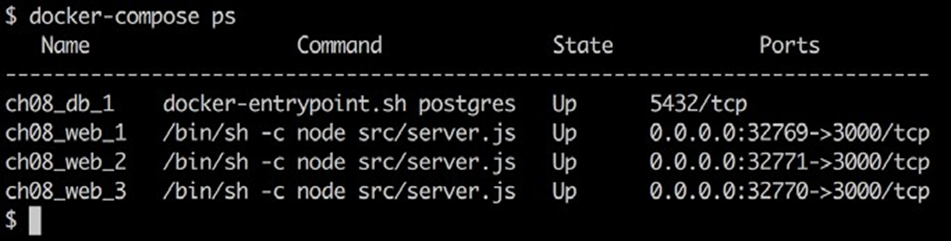
Sortie de docker-Compose ps
5. Comme nous pouvons le voir, chaque service a été associé à un port hôte différent. Nous pouvons essayer de voir s’ils fonctionnent, par exemple, en utilisant curl. Testons la troisième instance, ch08_web_3 :
$ curl -4 localhost:32770
Pets Demo Application
La réponse, Pets Demo Application, nous dit qu’en effet, notre application fonctionne toujours comme prévu. Essayez-le pour les deux autres instances pour en être sûr.
Construire et pousser une application
Nous pouvons également utiliser la commande docker-compose build pour simplement construire les images d’une application définie dans le fichier de composition sous-jacent. Mais pour que cela fonctionne, nous devrons ajouter les informations de construction au fichier docker-compose. Dans le dossier, nous avons un fichier, docker-compose.dev.yml , qui a déjà ajouté ces instructions:
version: “3.5”
services:
web:
build: web
image: appswithdockerandkubernetes/ch08 web:1.0 ports: – 3000:3000 db:
build: database
image: appswithdockerandkubernetes/ch08-db:1.0
volumes:
– pets-data:/var/lib/postgresql/data
volumes:
pets-data:
Veuillez noter la clé de construction pour chaque service. La valeur de cette clé indique le contexte ou le dossier dans lequel Docker s’attend à trouver le Dockerfile pour créer l’image correspondante.
Utilisons maintenant ce fichier :
$ docker-compose -f docker-compose.dev.yml build
Le paramètre -f indiquera à l’application Docker Compose quel fichier composer à utiliser.
Pour pousser toutes les images vers Docker Hub, nous pouvons utiliser le push docker-compose. Nous devons être connectés à Docker Hub pour que cela réussisse, sinon nous obtenons une erreur d’authentification lors de la poussée. Ainsi, dans mon cas, je fais ce qui suit :
$ docker login -u appswithdockerandkubernetes -p <password>
En supposant que la connexion réussit, je peux ensuite pousser le code suivant :
$ docker-compose -f docker-compose.dev.yml push
La commande précédente envoie les deux images au compte appswithdockerandkubernetes sur Docker Hub.
Résumé
Dans ce chapitre, nous avons présenté l’outil docker-compose. Cet outil est principalement utilisé pour exécuter et faire évoluer des applications multiservices sur un seul hôte Docker. En règle générale, les développeurs et les serveurs CI fonctionnent avec des hôtes uniques et ces deux sont les principaux utilisateurs de Docker Compose. L’outil utilise des fichiers YAML en entrée qui contiennent la description de l’application de manière déclarative.
L’outil peut également être utilisé pour créer et envoyer des images parmi de nombreuses autres tâches utiles. Le code accompagnant ce chapitre se trouve dans labs / ch08.
Dans le chapitre suivant, nous allons présenter les orchestrateurs. Un orchestrateur est un logiciel d’infrastructure utilisé pour exécuter et gérer des applications conteneurisées dans un cluster et il s’assure que ces applications sont dans leur état souhaité à tout moment.
Questions
Pour évaluer vos progrès d’apprentissage, veuillez répondre aux questions suivantes :
1. Comment allez-vous utiliser docker-compose pour exécuter une application en mode démon ?
2. Comment allez-vous utiliser docker-compose pour afficher les détails du service en cours d’exécution ?
3. Comment allez-vous faire évoluer un service Web particulier pour dire trois instances ?
Orchestrateurs
Dans le chapitre précédent, nous avons présenté Docker Compose, un outil qui nous permet de travailler avec des applications multiservices définies de manière déclarative sur un seul hôte Docker.
Ce chapitre présente le concept d’orchestrateurs. Il enseigne pourquoi les orchestrateurs sont nécessaires et comment ils fonctionnent conceptuellement. Ce chapitre fournira également un aperçu des orchestrateurs les plus populaires et nomme quelques-uns de leurs avantages et inconvénients.
Dans ce chapitre, nous couvrirons les sujets suivants :
- Que sont les orchestrateurs et pourquoi en avons-nous besoin ?
- Les tâches d’un orchestrateur
- Présentation des orchestrateurs populaires
Après avoir terminé ce chapitre, vous pourrez :
- Nommez trois à quatre tâches dont un orchestrateur est responsable
- Énumérez deux à trois des orchestrateurs les plus populaires
- Expliquez à un profane intéressé dans vos propres mots et avec des analogies appropriées pourquoi nous avons besoin d’orchestrateurs de conteneurs
Que sont les orchestrateurs et pourquoi en avons-nous besoin ?
Au chapitre 6, Architecture d’application distribuée, nous avons appris quels modèles et meilleures pratiques sont couramment utilisés pour créer, expédier et exécuter avec succès une application hautement distribuée. Maintenant, si notre application hautement distribuée est conteneurisée, nous sommes confrontés aux mêmes problèmes ou défis auxquels une application distribuée non conteneurisée est confrontée. Certains de ces défis sont ceux abordés dans le chapitre 6, Architecture d’application distribuée, découverte de service, équilibrage de charge, mise à l’échelle, etc.
Semblable à ce que Docker a fait avec les conteneurs – standardiser l’emballage et l’expédition des logiciels avec l’introduction de conteneurs – nous aimerions avoir un outil ou un logiciel d’infrastructure qui gère tous ou la plupart des défis mentionnés. Ce logiciel s’avère être ce que nous appelons des orchestrateurs ou, comme nous les appelons également, des moteurs d’orchestration.
Si ce que je viens de dire n’a pas encore beaucoup de sens pour vous, alors regardons-le sous un angle différent. Prenez un artiste qui joue d’un instrument. Ils peuvent jouer de la musique merveilleuse à un public tout seul, juste l’artiste et leur instrument. Mais maintenant, prenez un orchestre de musiciens. Mettez-les tous dans une pièce, donnez-leur les notes d’une symphonie, demandez-leur de la jouer et quittez la pièce. Sans directeur, ce groupe de musiciens très talentueux ne pourrait pas jouer cette pièce en harmonie ; cela ressemblerait à une cacophonie. Ce n’est que si l’orchestre a un chef d’orchestre qui orchestre le groupe de musiciens que la musique résultante de l’orchestre sera agréable à nos oreilles :

Un orchestrateur de conteneurs est comme le chef d’orchestre
Au lieu de musiciens, nous avons maintenant des conteneurs, et au lieu de différents instruments, nous avons des conteneurs qui ont des exigences différentes pour les hôtes de conteneur à exécuter. Et au lieu que la musique soit jouée dans des tempi différents, nous avons des conteneurs qui communiquent les uns avec les autres de manière particulière et doivent augmenter et diminuer. À cet égard, un orchestrateur de conteneurs a à peu près le même rôle qu’un chef d’orchestre. Il s’assure que les conteneurs et autres ressources d’un cluster jouent ensemble en harmonie.
J’espère que vous pouvez maintenant voire plus clairement ce qu’est un orchestrateur de conteneurs et pourquoi nous en avons besoin. Nous pouvons maintenant nous demander comment l’orchestrateur va atteindre le résultat escompté, à savoir s’assurer que tous les conteneurs du cluster jouent ensemble en harmonie. Eh bien, la réponse est que l’orchestrateur doit exécuter des tâches très spécifiques, similaires à la manière dont le chef d’orchestre a également un ensemble de tâches qu’il exécute afin d’apprivoiser et d’élever en même temps l’orchestre.
Les tâches d’un orchestrateur
Alors, quelles sont les tâches que nous attendons d’un orchestrateur qui en vaille la peine pour nous? Examinons-les en détail. La liste suivante présente les tâches les plus importantes que, au moment de la rédaction, les utilisateurs d’entreprise attendent généralement de leur orchestrateur.
Réconcilier l’état souhaité
Lorsque vous utilisez un orchestrateur, on lui dit de manière déclarative comment on veut qu’il exécute une application ou un service d’application donné. Nous avons appris ce que signifie déclaratif et impératif dans le chapitre 8, Docker Compose . Une partie de cette façon déclarative de décrire le service d’application que nous voulons exécuter est des éléments tels que l’image de conteneur à utiliser, le nombre d’instances à exécuter de ce service, les ports à ouvrir, etc. Cette déclaration des propriétés de notre service d’application est ce que nous appelons l’ état souhaité .
Ainsi, lorsque nous demandons à l’orchestrateur la première fois de créer un nouveau service d’application basé sur la déclaration, l’orchestrateur s’assure de planifier autant de conteneurs dans le cluster que demandé. Si l’image de conteneur n’est pas encore disponible sur les nœuds cibles du cluster où les conteneurs sont censés s’exécuter, le planificateur s’assure qu’ils sont téléchargés à partir du registre d’images en premier. Ensuite, les conteneurs sont démarrés avec tous les paramètres, tels que les réseaux auxquels se connecter ou les ports à exposer. L’orchestrateur travaille aussi dur que possible pour faire correspondre exactement en réalité dans le cluster ce qu’il a obtenu dans notre déclaration.
Une fois que notre service est opérationnel à la demande, c’est-à-dire qu’il s’exécute dans l’état souhaité, l’orchestrateur continue de le surveiller. Chaque fois que l’orchestrateur découvre une divergence entre l’état réel du service et son état souhaité, il fait de nouveau de son mieux pour concilier l’état souhaité.
Quelle pourrait être une telle divergence entre les états réels et souhaités d’un service d’application ? Eh bien, disons que l’une des répliques du service, c’est-à-dire l’un des conteneurs, se bloque en raison, par exemple, d’un bogue, alors l’orchestrateur découvrira que l’état réel diffère de l’état souhaité dans le nombre de répliques – là manque une réplique. L’orchestrateur planifie immédiatement une nouvelle instance sur un autre nœud de cluster, qui remplace l’instance bloquée. Une autre différence pourrait être qu’il y a trop d’instances du service d’application en cours d’exécution, si le service a été réduit. Dans ce cas, l’orchestrateur supprimera simplement au hasard autant d’instances que nécessaire pour atteindre la parité entre le nombre réel et le nombre souhaité d’instances. Une autre anomalie peut être due au fait que l’orchestrateur découvre qu’une instance du service d’application exécute une version incorrecte (peut-être ancienne) de l’image de conteneur sous-jacente. À présent, vous devriez obtenir l’image, non ?
Ainsi, au lieu de surveiller activement les services de notre application s’exécutant dans le cluster et de corriger tout écart par rapport à l’état souhaité, nous déléguons cette tâche fastidieuse à l’orchestrateur. Cela fonctionne très bien, si nous utilisons une manière déclarative et non impérative de décrire l’état souhaité de nos services d’application.
Services répliqués et globaux
Il existe deux types de services assez différents que nous pourrions vouloir exécuter dans un cluster géré par un orchestrateur. Ce sont des services répliqués et globaux . Un service répliqué est un service qui doit être exécuté dans un nombre spécifique d’instances, par exemple 10. Un service global, à son tour, est un service qui doit avoir une instance en cours d’exécution sur chaque nœud de travail unique du cluster. J’ai utilisé le terme nœud de travail ici. Dans un cluster géré par un orchestrateur, nous avons généralement deux types de nœuds, les gestionnaires et les travailleurs. Un nœud de gestionnaire est généralement exclusivement utilisé par l’orchestrateur pour gérer le cluster et n’exécute aucune autre charge de travail. Les nœuds de travail, à leur tour, exécutent les applications réelles.
Ainsi, l’orchestrateur s’assure que, pour un service global, une instance de celui-ci s’exécute sur chaque nœud de travail, quel qu’en soit le nombre. Nous n’avons pas besoin de nous soucier du nombre d’instances, mais seulement que sur chaque nœud, il est garanti d’exécuter une seule instance du service.
Encore une fois, nous pouvons pleinement compter sur l’orchestrateur pour s’occuper de cet exploit. Dans un service répliqué, nous serons toujours garantis de trouver le nombre exact d’instances souhaité, tandis que pour un service global, nous pouvons être assurés que sur chaque nœud de travail, il y aura toujours exactement une instance du service. L’orchestrateur travaillera toujours aussi dur que possible pour garantir cet état souhaité.
Dans Kubernetes, un service global est également appelé un ensemble de démons.
Découverte de service
Lorsque nous décrivons un service d’application de manière déclarative, nous ne sommes jamais censés dire à l’orchestrateur sur quels nœuds de cluster les différentes instances du service doivent s’exécuter. Nous laissons à l’orchestrateur le soin de décider quels nœuds conviennent le mieux à cette tâche.
Il est, bien sûr, techniquement possible de demander à l’orchestrateur d’utiliser des règles de placement très déterministes, mais ce serait un anti-modèle et n’est pas recommandé du tout.
Donc, si nous supposons maintenant que le moteur d’orchestration dispose d’un libre arbitre complet quant à l’emplacement des instances individuelles du service d’application et, en outre, que les instances peuvent se bloquer et être reprogrammées par l’orchestrateur sur différents nœuds, alors nous nous rendrons compte qu’il est une tâche futile pour nous de garder une trace de l’endroit où les instances individuelles s’exécutent à un moment donné. Encore mieux, nous ne devrions même pas essayer de le savoir car ce n’est pas important.
OK, vous pourriez dire, mais qu’en est-il si j’ai deux services, A et B, et que le service A dépend du service B ; une instance donnée du service A ne devrait-elle pas savoir où trouver une instance du service B?
Là, je dois dire haut et fort – non, ça ne devrait pas. Ce type de connaissances n’est pas souhaitable dans une application hautement distribuée et évolutive. Nous devons plutôt compter sur l’orchestrateur pour nous fournir les informations dont nous avons besoin pour atteindre les autres instances de service dont nous dépendons. C’est un peu comme dans l’ancien temps de la téléphonie, où nous ne pouvions pas appeler directement nos amis mais nous devions appeler le bureau central de la compagnie de téléphone, où un opérateur nous dirigeait ensuite vers la bonne destination. Dans notre cas, l’orchestrateur joue le rôle de l’opérateur, acheminant une demande provenant d’une instance de Service A vers une instance disponible de Service B. L’ensemble de ce processus est appelé découverte de service.
Routage
Nous avons appris jusqu’à présent que dans une application distribuée, nous avons de nombreux services en interaction. Lorsque le service A interagit avec le service B, cela se produit par l’échange de paquets de données. Ces paquets de données doivent en quelque sorte être canalisés du service A vers le service B. Ce processus de canalisation des paquets de données d’une source vers une destination est également appelé routage. En tant qu’auteurs ou opérateurs d’une application, nous nous attendons à ce que l’orchestrateur assume cette tâche de routage. Comme nous le verrons dans les chapitres suivants, le routage peut se produire à différents niveaux. C’est comme dans la vraie vie. Supposons que vous travaillez dans une grande entreprise dans l’un de leurs immeubles de bureaux. Maintenant, vous avez un document qui doit être transmis à un autre employé de l’entreprise. Le service postal interne récupérera le document dans votre boîte d’envoi et l’apportera au bureau de poste situé dans le même bâtiment. Si la personne cible travaille dans le même bâtiment, le document peut alors être directement transmis à cette personne. Si, en revanche, la personne travaille dans un autre bâtiment du même bloc, le document sera transmis au bureau de poste de ce bâtiment cible, d’où il sera ensuite distribué au destinataire via le service postal interne. Troisièmement, si le document est destiné à un employé travaillant dans une autre succursale de l’entreprise située dans une ville ou même un pays différent, le document est transmis à un service postal externe tel qu’UPS, qui le transportera à l’emplacement cible, à partir d’où, encore une fois, le service postal interne prend le relais et le livre au destinataire.
Des choses similaires se produisent lors du routage des paquets de données entre les services d’application exécutés dans des conteneurs. Les conteneurs source et cible peuvent être situés sur le même nœud de cluster, ce qui correspond à la situation où les deux employés travaillent dans le même bâtiment. Le conteneur cible peut être exécuté sur un nœud de cluster différent, ce qui correspond à la situation où les deux employés travaillent dans des bâtiments différents du même bloc. Enfin, la troisième situation est lorsqu’un paquet de données provient de l’extérieur du cluster et doit être routé vers le conteneur cible s’exécutant à l’intérieur du cluster.
Toutes ces situations et bien plus doivent être gérées par l’orchestrateur.
Équilibrage de charge
Dans une application distribuée hautement disponible, tous les composants doivent être redondants. Cela signifie que chaque service d’application doit être exécuté dans plusieurs instances afin que si une instance échoue, le service dans son ensemble est toujours opérationnel.
Pour vous assurer que toutes les instances d’un service fonctionnent et ne restent pas inactives, vous devez vous assurer que les demandes de service sont réparties également entre toutes les instances. Ce processus de répartition de la charge de travail entre les instances de service est appelé équilibrage de charge. Il existe différents algorithmes pour la répartition de la charge de travail. Habituellement, un équilibreur de charge fonctionne à l’aide de ce que l’on appelle l’algorithme à tour de rôle, qui garantit que la charge de travail est répartie également entre les instances à l’aide d’un algorithme cyclique.
Encore une fois, nous attendons de l’orchestrateur qu’il s’occupe des demandes d’équilibrage de charge d’un service à un autre ou de sources externes à des services internes.
Mise à l’échelle
Lorsque nous exécutons notre application distribuée conteneurisée dans un cluster géré par un orchestrateur, nous voulons également un moyen simple de gérer les augmentations attendues ou inattendues de la charge de travail. Pour gérer une charge de travail accrue, nous planifions généralement simplement des instances supplémentaires d’un service qui subit cette charge accrue. Les équilibreurs de charge seront alors automatiquement configurés pour répartir la charge de travail sur davantage d’instances cibles disponibles.
Mais dans des scénarios réels, la charge de travail varie au fil du temps. Si nous regardons un site d’achat tel qu’Amazon, il pourrait avoir une charge élevée pendant les heures de pointe du soir, lorsque tout le monde est à la maison et fait des achats en ligne ; il peut subir des charges extrêmes lors de journées spéciales telles que le Black Friday ; et il peut y avoir très peu de trafic tôt le matin. Ainsi, les services doivent non seulement pouvoir évoluer, mais aussi se réduire lorsque la charge de travail diminue.
Nous nous attendons également à ce que les orchestrateurs distribuent les instances d’un service de manière significative lors de l’augmentation ou de la réduction. Il ne serait pas judicieux de planifier toutes les instances du service sur le même nœud de cluster, car si ce nœud tombe en panne, tout le service tombe en panne. L’ordonnanceur de l’orchestrateur, qui est responsable du placement des conteneurs, doit également envisager de ne pas placer toutes les instances dans le même rack d’ordinateurs, car si l’alimentation du rack tombe en panne, à nouveau l’ensemble du service est affecté. De plus, les instances de service des services critiques devraient même être réparties entre les centres de données pour éviter les pannes. Toutes ces décisions et bien d’autres sont de la responsabilité de l’orchestrateur.
Auto-guérison
De nos jours, les orchestrateurs sont très sophistiqués et peuvent faire beaucoup pour nous afin de maintenir un système sain. Les orchestrateurs surveillent tous les conteneurs en cours d’exécution dans le cluster et remplacent automatiquement les conteneurs bloqués ou qui ne répondent pas par de nouvelles instances. Les orchestrateurs surveillent l’intégrité des nœuds de cluster et les retirent de la boucle du planificateur si un nœud devient défectueux ou est en panne. Une charge de travail située sur ces nœuds est automatiquement replanifiée sur différents nœuds disponibles.
Toutes ces activités où l’orchestrateur surveille l’état actuel et répare automatiquement les dommages ou réconcilient l’état souhaité conduisent à un soi-disant système d’auto-guérison . Nous n’avons pas, dans la plupart des cas, à engager activement et réparer les dommages. L’orchestrateur le fera automatiquement pour nous.
Mais il y a quelques situations que l’orchestrateur ne peut pas gérer sans notre aide. Imaginez une situation où une instance de service s’exécute dans un conteneur. Le conteneur est opérationnel et, de l’extérieur, semble parfaitement sain. Mais l’application à l’intérieur est dans un état malsain. L’application n’a pas planté, elle ne peut plus fonctionner comme prévu. Comment l’orchestrateur pourrait-il savoir cela sans que nous lui donnions un indice ? Ça ne peut pas ! Être dans un état malsain ou invalide signifie quelque chose de complètement différent pour chaque service d’application. En d’autres termes, l’état de santé dépend du service. Seuls les auteurs du service ou ses opérateurs savent ce que signifie la santé dans le cadre d’un service.
Désormais, les orchestrateurs définissent des coutures ou des sondes, sur lesquelles un service d’application peut communiquer avec l’orchestrateur dans quel état il se trouve. Il existe deux types fondamentaux de sonde :
- Le service peut indiquer à l’orchestrateur qu’il est sain ou non
- Le service peut indiquer à l’orchestrateur qu’il est prêt ou temporairement indisponible
La façon dont le service détermine l’une des réponses précédentes dépend entièrement du service. L’orchestrateur définit uniquement comment il va demander, par exemple, via une requête HTTP GET, ou quel type de réponses il attend, par exemple, OK ou PAS D’ACCORD.
Si nos services implémentent une logique pour répondre aux questions de santé ou de disponibilité précédentes, alors nous avons un véritable système d’auto-réparation, car l’orchestrateur peut tuer les instances de service malsaines et les remplacer par de nouvelles instances saines, et il peut prendre des instances de service temporairement indisponibles.
Déploiements sans interruption de service
De nos jours, il devient de plus en plus difficile de justifier un temps d’arrêt complet pour une application critique qui doit être mise à jour. Cela signifie non seulement des occasions manquées, mais cela peut également nuire à la réputation de l’entreprise. Les clients utilisant l’application ne sont tout simplement plus prêts à accepter un tel inconvénient et se détourneront rapidement. De plus, nos cycles de sortie deviennent de plus en plus courts. Là où, dans le passé, nous avions une ou deux nouvelles versions par an, de nos jours, beaucoup d’entreprises mettent à jour leurs applications plusieurs fois par semaine ou même plusieurs fois par jour.
La solution à ce problème consiste à proposer une stratégie de mise à jour des applications sans interruption de service. L’orchestrateur doit pouvoir mettre à jour les services d’application individuels par lots. Ceci est également appelé mises à jour continues. À un moment donné, une seule ou quelques-unes du nombre total d’instances d’un service donné sont supprimées et remplacées par la nouvelle version du service. Ce n’est que si les nouvelles instances sont opérationnelles et ne produisent pas d’erreurs inattendues ou ne montrent aucun mauvais comportement que le prochain lot d’instances sera mis à jour. Cette opération est répétée jusqu’à ce que toutes les instances soient remplacées par leur nouvelle version. Si, pour une raison quelconque, la mise à jour échoue, nous nous attendons à ce que l’orchestrateur rétablisse automatiquement les instances mises à jour vers leur version précédente.
D’autres déploiements sans interruption possible sont les versions dites canaries et les déploiements bluegreen. Dans les deux cas, la nouvelle version d’un service est installée en parallèle avec la version actuelle active. Mais au départ, la nouvelle version n’est accessible qu’en interne. Les opérations peuvent ensuite exécuter des tests de fumée par rapport à la nouvelle version et lorsque la nouvelle version semble fonctionner correctement, dans le cas d’un déploiement bleu-vert, le routeur passe du bleu actuel à la nouvelle version verte. Pendant un certain temps, la nouvelle version verte du service est étroitement surveillée et, si tout va bien, l’ancienne version bleue peut être déclassée. Si, en revanche, la nouvelle version verte ne fonctionne pas comme prévu, il suffit de remettre le routeur à l’ancienne version bleue pour obtenir un rollback complet.
Dans le cas d’une version canari, le routeur est configuré de telle manière qu’il achemine un petit pourcentage, disons 1%, du trafic global via la nouvelle version du service, tandis que 99% du trafic est toujours acheminé via l’ancienne version. Le comportement de la nouvelle version est étroitement surveillé et comparé au comportement de l’ancienne version. Si tout semble bon, le pourcentage du trafic acheminé via le nouveau service est légèrement augmenté. Ce processus est répété jusqu’à ce que 100% du trafic soit acheminé via le nouveau service. Si le nouveau service fonctionne depuis un certain temps et que tout semble correct, l’ancien service peut être mis hors service.
La plupart des orchestrateurs prennent en charge au moins le type de mise à jour progressive de déploiement sans interruption de service. Les versions bleu-vert et canaris sont souvent assez faciles à mettre en œuvre.
Affinité et connaissance de l’emplacement
Parfois, certains services d’application nécessitent la disponibilité d’un matériel dédié sur les nœuds sur lesquels ils s’exécutent. Par exemple, les services I / O-lié requiers nœuds du cluster avec une haute performance attaché disque SSD (SSD), ou certains services nécessitent une unité de traitement accéléré (APU). Les orchestrateurs nous permettent de définir des affinités de nœuds par service d’application. L’orchestrateur s’assurera alors que son planificateur planifie uniquement les conteneurs sur les nœuds de cluster qui remplissent les critères requis.
La définition d’une affinité pour un nœud particulier doit être évitée ; cela introduirait un point de défaillance unique et compromettrait ainsi la haute disponibilité. Définissez toujours un ensemble de plusieurs nœuds de cluster comme cible pour un service d’application.
Certains moteurs d’orchestration prennent également en charge ce que l’on appelle la détection d’emplacement ou la géo-reconnaissance. Cela signifie que l’on peut demander à l’orchestrateur de répartir également les instances d’un service sur un ensemble d’emplacements différents. On pourrait, par exemple, définir un centre de données d’étiquette avec les valeurs possibles ouest, centre et est et appliquer l’étiquette à tous les nœuds de cluster avec la valeur qui correspond à la région géographique dans laquelle se trouve le nœud respectif. Ensuite, on demande à l’orchestrateur d’utiliser cette étiquette pour la géo-connaissance d’un certain service d’application. Dans ce cas, si l’on demande neuf répliques du service, l’orchestrateur s’assurera que trois instances sont déployées sur des nœuds dans chacun des trois centres de données, ouest, centre et est.
La géo-prise de conscience peut même être définie de manière hiérarchique ; par exemple, on peut avoir un centre de données comme discriminateur de niveau supérieur, suivi de la zone de disponibilité puis du rack de serveur.
La géo-prise de conscience ou la prise de conscience de l’emplacement est utilisée pour réduire la probabilité de pannes dues à des pannes d’alimentation ou des pannes de centre de données. Si les instances d’application sont réparties sur des racks de serveurs, des zones de disponibilité ou même des centres de données, il est extrêmement improbable que tout tombe en panne à la fois. Une région sera toujours disponible.
Sécurité
De nos jours, la sécurité informatique est un sujet très brûlant. La cyberguerre est à un niveau record. La plupart des entreprises prestigieuses ont été victimes d’attaques de pirates, avec des conséquences très coûteuses. L’un des pires cauchemars de chaque directeur de l’information (CIO) ou chef de la technologie (CTO) est de se réveiller le matin et d’entendre dans les nouvelles que leur entreprise a été victime d’une attaque de pirate et que des informations sensibles ont été volées ou compromis.
Pour contrer la plupart de ces menaces à la sécurité, nous devons établir une chaîne logistique de logiciels sécurisée et appliquer une défense de sécurité en profondeur. Examinons certaines des tâches que l’on peut attendre d’un orchestrateur de niveau entreprise.
Communication sécurisée et identité du nœud cryptographique
Tout d’abord, nous voulons nous assurer que notre cluster géré par l’orchestrateur est sécurisé. Seuls les nœuds approuvés peuvent rejoindre le cluster. Chaque nœud qui rejoint le cluster obtient une identité de nœud cryptographique et toutes les communications entre les nœuds doivent être chiffrées. Pour cela, les nœuds peuvent utiliser la sécurité de couche de transport mutuelle (MTLS). Pour authentifier les nœuds du cluster entre eux, des certificats sont utilisés. Ces certificats sont automatiquement renouvelés périodiquement ou sur demande pour protéger le système en cas de fuite d’un certificat.
La communication qui se produit dans un cluster peut être séparée en trois types. On parle d’avions de communication. Il existe des plans de gestion, de contrôle et de données :
- Le plan de gestion est utilisé par les gestionnaires ou les maîtres de cluster pour, par exemple, planifier des instances de service, exécuter des contrôles d’intégrité ou créer et modifier toutes les autres ressources du cluster, telles que les volumes de données, les secrets ou les réseaux.
- Le plan de contrôle est utilisé pour échanger des informations d’état importantes entre tous les nœuds du cluster. Ce type d’informations est, par exemple, utilisé pour mettre à jour les tables IP locales sur les clusters qui sont utilisés à des fins de routage.
- Le plan de données est l’endroit où les services d’application communiquent entre eux et échangent des données.
Normalement, les orchestrateurs se soucient principalement de sécuriser le plan de gestion et de contrôle. La sécurisation du plan de données est laissée à l’utilisateur, mais l’orchestrateur peut faciliter cette tâche.
Réseaux sécurisés et politiques de réseau
Lors de l’exécution de services d’application, tous les services n’ont pas besoin de communiquer avec tous les autres services du cluster. Ainsi, nous voulons pouvoir mettre en sandbox des services les uns des autres et exécuter uniquement ces services dans le même sandbox de mise en réseau qui a absolument besoin de communiquer entre eux. Tous les autres services et tout le trafic réseau provenant de l’extérieur du cluster ne devraient pas avoir la possibilité d’accéder aux services en bac à sable.
Il existe au moins deux façons dont ce sandboxing basé sur le réseau peut se produire. Nous pouvons utiliser un réseau défini par logiciel (SDN) pour regrouper les services d’application ou nous pouvons avoir un réseau plat et utiliser des stratégies de réseau pour contrôler qui a et n’a pas accès à un service ou groupe de services particulier.
Contrôle d’accès basé sur les rôles (RBAC)
L’une des tâches les plus importantes, à côté de la sécurité, qu’un orchestrateur doit remplir pour le préparer à l’entreprise est de fournir un accès basé sur les rôles au cluster et à ses ressources. RBAC définit comment les sujets, les utilisateurs ou les groupes d’utilisateurs du système, organisés en équipes, etc., peuvent accéder au système et le manipuler. Il s’assure que le personnel non autorisé ne peut pas nuire au système ni voir les ressources disponibles dans le système qu’il n’est pas censé connaître ou voir.
Une entreprise typique peut avoir des groupes d’utilisateurs tels que Développement, QA et Prod, et chacun de ces groupes peut être associé à un ou plusieurs utilisateurs. John Doe, le développeur, est membre du groupe de développement et, à ce titre, peut accéder aux ressources dédiées à l’équipe de développement, mais il ne peut pas accéder, par exemple, aux ressources de l’équipe Prod, dont Ann Harbour est membre. À son tour, elle ne peut pas interférer avec les ressources de l’équipe de développement.
Une façon de mettre en œuvre le RBAC consiste à définir les subventions. Une subvention est une association entre un sujet, un rôle et une collection de ressources. Ici, un rôle est composé d’un ensemble d’autorisations d’accès à une ressource. Ces autorisations peuvent consister à créer, arrêter, supprimer, répertorier ou afficher des conteneurs ; déployer un nouveau service d’application ; pour répertorier les nœuds de cluster ou afficher les détails d’un nœud de cluster ; et beaucoup plus.
Une collection de ressources est un groupe de ressources logiquement liées du cluster, telles que des services d’application, des secrets, des volumes de données ou des conteneurs.
Secrets
Dans notre vie quotidienne, nous avons plein de secrets. Les secrets sont des informations qui ne sont pas censées être connues du public, comme la combinaison nom d’utilisateur et mot de passe que vous utilisez pour accéder à votre compte bancaire en ligne, ou le code de votre téléphone portable ou de votre casier au gymnase.
Lors de l’écriture de logiciels, nous devons également souvent utiliser des secrets. Par exemple, nous avons besoin d’un certificat pour authentifier notre service d’application avec un service externe auquel nous voulons accéder, où nous avons besoin d’un jeton pour authentifier et autoriser notre service lors de l’accès à une autre API. Dans le passé, pour des raisons de commodité, les développeurs venaient de coder en dur ces valeurs ou de les mettre en texte clair dans certains fichiers de configuration externes. Là, ces informations très sensibles ont été accessibles à un large public qui, en réalité, n’aurait jamais dû avoir l’occasion de découvrir ces secrets.
Heureusement, de nos jours, les orchestrateurs offrent ce que l’on appelle des secrets pour traiter ces informations sensibles de manière hautement sécurisée. Les secrets peuvent être créés par du personnel autorisé ou de confiance. Les valeurs de ces secrets sont ensuite chiffrées et stockées dans la base de données d’état de cluster hautement disponible. Les secrets, puisqu’ils sont cryptés, sont désormais sécurisés au repos. Une fois qu’un secret est demandé par un service d’application autorisée, le secret est transmis uniquement aux nœuds de cluster qui exécutent en fait une instance de ce service particulier, et la valeur secrète ne sont jamais stockées sur le nœud mais monté dans le récipient dans un tmpfs RAM- volume basé. Ce n’est qu’à l’intérieur du conteneur respectif que la valeur secrète est disponible en texte clair.
Nous avons déjà mentionné que les secrets sont sécurisés au repos. Une fois qu’ils sont demandés par un service, le gestionnaire de cluster ou le maître déchiffre le secret et l’envoie par câble aux nœuds cibles. Alors, qu’en est-il des secrets sécurisés en transit ? Eh bien, nous avons appris plus tôt que les nœuds de cluster utilisent MTLS pour leur communication, donc le secret, bien que transmis en texte clair, est toujours sécurisé car les paquets de données seront cryptés par MTLS. Ainsi, les secrets sont sécurisés au repos et en transit. Seuls les services autorisés à utiliser des secrets n’auront jamais accès à ces valeurs secrètes.
Approbation du contenu
Pour plus de sécurité, nous voulons nous assurer que seules les images de confiance s’exécutent dans notre cluster de production. Certains orchestrateurs nous permettent de configurer un cluster afin qu’il ne puisse exécuter que des images signées. La confiance dans le contenu et la signature d’images consistent à s’assurer que les auteurs de l’image sont bien ceux que nous attendons d’eux, à savoir nos développeurs de confiance ou, mieux encore, notre serveur CI de confiance. De plus, avec la confiance du contenu, nous voulons garantir que l’image que nous obtenons est fraîche et non une image ancienne et peut-être vulnérable. Et enfin, nous voulons nous assurer que l’image ne peut pas être compromise par des pirates malveillants en transit. Ce dernier est souvent appelé une attaque d’homme au milieu (MITM).
En signant des images à la source et en validant la signature sur la cible, nous pouvons garantir que les images que nous voulons exécuter ne sont pas compromises.
Temps de fonctionnement inversé
Le dernier point que je souhaite aborder dans le contexte de la sécurité est la disponibilité inverse. Qu’est-ce que nous entendons par là ? Imaginez que vous avez configuré et sécurisé un cluster de production.
Sur ce cluster, vous exécutez quelques applications stratégiques de votre entreprise. Maintenant, un pirate a réussi à trouver une faille de sécurité dans l’une de vos piles de logiciels et a obtenu un accès root à l’un de vos nœuds de cluster. Cela seul est déjà assez mauvais mais, pire encore, ce pirate pourrait maintenant masquer leur présence sur ce nœud, ils sont root sur la machine, après tout, puis l’utiliser comme base pour attaquer d’autres nœuds de votre cluster.
L’accès root sous Linux ou tout système d’exploitation de type Unix signifie que l’on peut tout faire sur ce système. Il s’agit du niveau d’accès le plus élevé que quelqu’un puisse avoir. Sous Windows, le rôle équivalent est celui d’un administrateur.
Mais que faire si nous exploitons le fait que les conteneurs sont éphémères et que les nœuds de cluster sont rapidement provisionnés, généralement en quelques minutes s’ils sont entièrement automatisés ? Nous venons de tuer chaque nœud de cluster après un certain temps de fonctionnement de, disons, 1 jour. L’orchestrateur est chargé de vider le nœud, puis de l’exclure du cluster. Une fois le nœud hors du cluster, il est détruit et remplacé par un nœud fraîchement provisionné.
De cette façon, le pirate a perdu sa base et le problème a été éliminé. Ce concept n’est pas encore largement disponible, cependant, mais il me semble qu’il s’agit d’un énorme pas vers une sécurité accrue et, pour autant que j’en ai discuté avec des ingénieurs travaillant dans ce domaine, il n’est pas difficile à mettre en œuvre.
Introspection
Jusqu’à présent, nous avons discuté de nombreuses tâches dont l’orchestrateur est responsable et qu’il peut exécuter de manière totalement autonome. Mais il est également nécessaire que les opérateurs humains puissent voir et analyser ce qui fonctionne actuellement sur le cluster et dans quel état ou état de santé les applications individuelles sont. Pour tout cela, nous avons besoin de la possibilité d’introspection. L’orchestrateur doit faire apparaître des informations cruciales d’une manière facilement consommable et compréhensible.
L’orchestrateur doit collecter les métriques système de tous les nœuds du cluster et les rendre accessibles aux opérateurs. Les mesures incluent l’utilisation du processeur, de la mémoire et du disque, la consommation de bande passante du réseau, etc. Les informations devraient être facilement disponibles, nœud par nœud, ainsi que sous forme agrégée.
Nous voulons également que l’orchestrateur nous donne accès aux journaux produits par les instances de service ou les conteneurs. De plus, l’orchestrateur devrait nous fournir un accès exécutable à chaque conteneur si nous avons l’autorisation appropriée pour le faire. Avec un accès exec aux conteneurs, on peut ensuite déboguer les conteneurs qui se comportent mal.
Dans les applications hautement distribuées, où chaque demande à l’application passe par de nombreux services jusqu’à ce qu’elle soit complètement traitée, le suivi des demandes est une tâche vraiment importante. Idéalement, l’orchestrateur nous aide à mettre en œuvre une stratégie de traçage ou nous donne de bonnes directives à suivre.
Enfin, les opérateurs humains peuvent mieux surveiller un système lorsqu’ils travaillent avec une représentation graphique de toutes les métriques collectées et des informations de journalisation et de traçage. Ici, nous parlons de tableaux de bord. Chaque orchestrateur décent devrait offrir au moins un tableau de bord de base avec une représentation graphique des paramètres système les plus critiques.
Mais les opérateurs humains ne sont pas du tout préoccupés par l’introspection. Nous devons également pouvoir connecter des systèmes externes à l’orchestrateur pour consommer ces informations. Une API doit être disponible, sur laquelle les systèmes externes peuvent accéder aux données telles que l’état du cluster, les métriques et les journaux et utiliser ces informations pour prendre des décisions automatisées, telles que la création d’alertes de téléavertisseur ou de téléphone, l’envoi d’e-mails ou le déclenchement d’une sirène d’alarme si certains seuils sont dépassés par le système.
Présentation des orchestrateurs populaires
Au moment de la rédaction de ce document, il existe de nombreux moteurs d’orchestration et en cours d’utilisation. Mais il y a quelques gagnants clairs. La première place est clairement détenue par Kubernetes, qui règne en maître. Un deuxième lointain est le propre SwarmKit de Docker, suivi par d’autres tels que Microsoft Azure Kubernetes Service (AKS), Apache Mesos ou AWS Elastic Container Service ( ECS ).
Kubernetes
Kubernetes a été conçu à l’origine par Google et ensuite donné à la Cloud Native Computing Foundation (CNCF). Kubernetes a été modelé sur le système propriétaire Borg de Google, qui gère des conteneurs à grande échelle depuis des années. Kubernetes était la tentative de Google de revenir à la planche à dessin et de recommencer complètement et de concevoir un système qui incorpore toutes les leçons apprises avec Borg.
Contrairement à Borg, qui est une technologie propriétaire, Kubernetes était open source dès le début. C’était un choix très judicieux de Google, car il a attiré un grand nombre de contributeurs de l’extérieur de l’entreprise et, en seulement quelques années, un écosystème encore plus massif s’est développé autour de Kubernetes. On peut dire à juste titre que Kubernetes est le chouchou de la communauté dans l’espace d’orchestration de conteneurs. Aucun autre orchestrateur n’a été capable de produire autant de battage médiatique et d’attirer autant de personnes talentueuses désireuses de contribuer de manière significative à la réussite du projet en tant que contributeur ou adopteur précoce.
À cet égard, Kubernetes dans l’espace d’orchestration de conteneurs me ressemble beaucoup à ce que Linux est devenu dans l’espace du système d’exploitation du serveur. Linux est devenu de facto la norme des systèmes d’exploitation serveur. Toutes les entreprises concernées, telles que Microsoft, IBM, Amazon, RedHat et même Docker, ont adopté Kubernetes.
Et il y a une chose qui ne peut être niée : Kubernetes a été conçu dès le début pour une évolutivité massive. Après tout, il a été conçu avec Google Borg à l’esprit.
Un aspect négatif que l’on pourrait exprimer contre Kubernetes est qu’il est complexe à mettre en place et à gérer, au moins au moment de la rédaction. Il y a un obstacle important à surmonter pour les nouveaux arrivants. La première étape est raide. Mais une fois que l’on a travaillé avec cet orchestrateur pendant un certain temps, tout a du sens. La conception globale est soigneusement pensée et exécutée très bien.
Dans la dernière version de Kubernetes, 1.10, dont la disponibilité générale (GA) était en mars 2018, la plupart des lacunes initiales par rapport à d’autres orchestrateurs tels que Docker Swarm ont été éliminées. Par exemple, la sécurité et la confidentialité ne sont plus seulement une réflexion après coup, mais font partie intégrante du système.
De nouvelles fonctionnalités sont mises en œuvre à une vitesse incroyable. Les nouvelles versions ont lieu tous les 3 mois environ, plus précisément tous les 100 jours environ. La plupart des nouvelles fonctionnalités sont dictées par la demande, c’est-à-dire que les entreprises utilisant Kubernetes pour orchestrer leurs applications critiques peuvent exprimer leurs besoins. Cela rend l’entreprise Kubernetes prête. Il serait faux de supposer que cet orchestrateur est uniquement destiné aux start-ups et non aux entreprises peu enclines à prendre des risques. Le contraire est le cas. Sur quoi fonder cette affirmation ? Eh bien, ma revendication est justifiée par le fait que des sociétés telles que Microsoft, Docker et RedHat, dont les clients sont principalement des grandes entreprises, ont pleinement adopté Kubernetes et fournissent un support de niveau entreprise pour celui-ci s’il est utilisé et intégré dans leurs offres d’entreprise.
Kubernetes prend en charge les conteneurs Linux et Windows.
Docker Swarm
Il est bien connu que Docker a popularisé et banalisé les conteneurs de logiciels. Docker n’a pas inventé les conteneurs, mais les a standardisés et les a largement diffusés, notamment en proposant le registre d’images gratuit Docker Hub. Initialement, Docker s’est concentré principalement sur le développeur et le cycle de vie du développement. Mais les entreprises qui ont commencé à utiliser et à aimer les conteneurs ont rapidement voulu également utiliser des conteneurs, non seulement lors du développement ou du test de nouvelles applications, mais également pour exécuter ces applications en production.
Initialement, Docker n’avait rien à offrir dans cet espace, alors d’autres entreprises se sont jetées dans ce vide et ont offert de l’aide aux utilisateurs. Mais cela n’a pas pris longtemps et Docker a reconnu qu’il y avait une énorme demande pour un orchestrateur simple mais puissant. La première tentative de Docker était un produit appelé Swarm classique. Il s’agissait d’un produit autonome qui permettait aux utilisateurs de créer un cluster de machines hôtes Docker pouvant être utilisé pour exécuter et faire évoluer leurs applications conteneurisées de manière hautement disponible et autoréparable.
Cependant, la configuration d’un Docker Swarm classique a été difficile. Beaucoup d’étapes manuelles compliquées ont été impliquées. Les clients ont adoré le produit mais ont eu du mal avec sa complexité. Docker a donc décidé qu’il pouvait faire mieux. Il est retourné à la planche à dessin et est venu avec SwarmKit. SwarmKit a été présenté à DockerCon 2016 à Seattle et faisait partie intégrante de la dernière version du moteur Docker. Oui, vous avez raison, SwarmKit était et est toujours à ce jour une partie intégrante du moteur Docker. Ainsi, si vous installez un hôte Docker, vous disposez automatiquement de SwarmKit.
SwarmKit a été conçu dans un souci de simplicité et de sécurité. Le mantra était et est toujours qu’il doit être presque trivial de mettre en place un essaim, et l’essaim doit être hautement sécurisé hors de la boîte. Docker Swarm fonctionne sur l’hypothèse du moindre privilège.
L’installation d’un Docker Swarm complet et hautement disponible est littéralement aussi simple que de démarrer avec un init de docker swarm sur le premier nœud du cluster, qui devient le soi-disant leader, puis un docker swarm join <join-token> sur tous les autres nœuds. Le jeton de jointure est généré par le leader lors de l’initialisation. L’ensemble du processus prend moins de 5 minutes sur un essaim avec jusqu’à 10 nœuds. S’il est automatisé, cela prend encore moins de temps.
Comme je l’ai déjà mentionné, la sécurité était au sommet de la liste des incontournables lorsque Docker a conçu et développé SwarmKit. Les conteneurs assurent la sécurité en s’appuyant sur les espaces de noms et les cgroups du noyau Linux ainsi que sur la liste blanche des appels système Linux (seccomp) et la prise en charge des capacités Linux et du module de sécurité Linux (LSM). Maintenant, en plus de cela, SwarmKit ajoute des MTLS et des secrets qui sont chiffrés au repos et en transit. En outre, Swarm définit le soi-disant modèle de réseau de conteneurs (CNM), qui permet aux SDN qui fournissent le sandboxing pour les services d’application s’exécutant sur l’essaim.
Docker SwarmKit prend en charge les conteneurs Linux et Windows.
Service Microsoft Azure Kubernetes (AKS)
AKS est l’offre de Microsoft d’un cluster Kubernetes entièrement hébergé, hautement disponible, évolutif et tolérant aux pannes. Il vous charge de provisionner et de gérer un cluster Kubernetes et vous permet de vous concentrer sur le déploiement et l’exécution de vos applications conteneurisées. Avec AKS, un utilisateur peut littéralement provisionner un cluster prêt pour la production en quelques minutes. De plus, les applications s’exécutant sur un tel cluster peuvent facilement atteindre le riche écosystème de services fournis par Azure tels que Log Analytics ou la gestion des identités.
Il s’agit d’un puissant service d’orchestration basé sur les dernières versions de Kubernetes qui a du sens si vous êtes déjà fortement investi dans l’écosystème Azure. Chaque cluster AKS peut être géré via le portail Azure, via des modèles Azure Resource Manager ou via Azure CLI. Les applications sont déployées et maintenues à l’aide du célèbre kubectl CLI de Kubernetes .
Microsoft, dans ses propres mots, affirme ce qui suit :
AKS permet de déployer et de gérer rapidement et facilement des applications conteneurisées sans expertise en orchestration de conteneurs. Il élimine également la charge des opérations et de la maintenance en cours en provisionnant, mettant à niveau et adaptant les ressources à la demande, sans mettre vos applications hors ligne.
Apache Mesos et Marathon
Apache Mesos est un projet open source et a été initialement conçu pour faire en sorte qu’un cluster de serveurs ou de nœuds ressemble à un seul grand serveur de l’extérieur. Mesos est un logiciel qui simplifie la gestion des clusters d’ordinateurs. Les utilisateurs de Mesos ne devraient pas avoir à se soucier des serveurs individuels, mais supposent simplement qu’ils ont un gigantesque pool de ressources à leur disposition, ce qui correspond à l’agrégat de toutes les ressources de tous les nœuds du cluster.
Mesos, en termes informatiques, est déjà assez vieux, du moins par rapport aux autres orchestrateurs. Il a été présenté publiquement pour la première fois en 2009. Mais à l’époque, bien sûr, il n’était pas conçu pour exécuter des conteneurs, car Docker n’existait même pas encore. Semblable à ce que Docker fait avec les conteneurs, Mesos utilise des groupes de contrôle Linux pour isoler des ressources telles que le processeur, la mémoire ou les E / S de disque pour des applications ou des services individuels.
Mesos est vraiment l’infrastructure sous-jacente pour d’autres services intéressants construits en plus. Du point de vue des conteneurs en particulier, Marathon est important. Marathon est un orchestrateur de conteneurs fonctionnant au-dessus de Mesos qui peut évoluer vers des milliers de nœuds.
Marathon prend en charge plusieurs temps d’exécution de conteneurs, tels que Docker ou ses propres conteneurs Mesos. Il prend en charge non seulement les services d’application sans état mais également avec état, par exemple, les bases de données telles que PostgreSQL ou MongoDB. Semblable à Kubernetes et Docker SwarmKit, il prend en charge la plupart des fonctionnalités décrites précédemment dans ce chapitre, telles que la haute disponibilité, les contrôles d’intégrité, la découverte de service, l’équilibrage de charge et la connaissance de l’emplacement, pour n’en nommer que quelques-unes des plus importantes.
Bien que Mesos et, dans une certaine mesure, Marathon soient des projets plutôt matures, leur portée est relativement limitée. Il semble être le plus populaire dans le domaine des mégadonnées, c’est-à-dire pour exécuter des services de crunching de données tels que Spark ou Hadoop.
Amazon ECS
Si vous recherchez un orchestrateur simple et que vous avez déjà beaucoup investi dans l’écosystème AWS, l’ECS d’Amazon pourrait être le bon choix pour vous. Il est important de souligner une limitation très importante d’ECS : si vous achetez dans cet orchestrateur de conteneurs, vous vous enfermez dans AWS. Vous ne pourrez pas facilement porter une application exécutée sur ECS vers une autre plateforme ou cloud.
Amazon fait la promotion de son service ECS en tant que service de gestion de conteneurs rapide et hautement évolutif qui facilite l’exécution, l’arrêt et la gestion des conteneurs Docker sur un cluster. En plus d’exécuter des conteneurs, ECS donne un accès direct à de nombreux autres services AWS à partir des services d’application exécutés à l’intérieur des conteneurs. Cette intégration étroite et transparente avec de nombreux services AWS populaires est ce qui rend ECS attrayant pour les utilisateurs qui recherchent un moyen facile de faire fonctionner leurs applications conteneurisées dans un environnement robuste et hautement évolutif. Amazon fournit également son propre registre d’images privé.
Avec AWS ECS, vous pouvez utiliser Fargate pour qu’il gère entièrement l’infrastructure sous-jacente afin que vous puissiez vous concentrer exclusivement sur le déploiement d’applications conteneurisées et ne pas avoir à vous soucier de la façon de créer et de gérer un cluster de nœuds. ECS prend en charge les conteneurs Linux et Windows.
En résumé, ECS est simple à utiliser, hautement évolutif et bien intégré avec d’autres services AWS populaires, mais il n’est pas aussi puissant que, par exemple, Kubernetes ou Docker SwarmKit et il n’est disponible que sur Amazon AWS.
Résumé
Ce chapitre a démontré pourquoi les orchestrateurs sont nécessaires en premier lieu et comment ils fonctionnent conceptuellement. Il a souligné les orchestrateurs les plus en vue au moment de la rédaction et a discuté des principaux points communs et différences entre les différents orchestrateurs.
Le chapitre suivant présentera l’orchestrateur de conteneurs actuellement le plus populaire, appelé Kubernetes. Il développera tous les concepts et objets que Kubernetes utilise pour déployer et exécuter une application distribuée, résiliente, robuste et hautement disponible dans un cluster sur site ou dans le cloud.
Questions
Répondez aux questions suivantes pour évaluer vos progrès d’apprentissage :
1. Pourquoi avons-nous besoin d’un orchestrateur ? Nommez deux ou trois raisons.
2. Nommez trois à quatre responsabilités typiques d’un orchestrateur.
3. Nommez au moins deux orchestrateurs de conteneurs, ainsi que le principal sponsor derrière eux.
Orchestrer des applications conteneurisées avec Kubernetes
Dans le dernier chapitre, nous avons présenté les orchestrateurs. Comme un chef d’orchestre dans un orchestre, un orchestrateur s’assure que tous nos services d’application conteneurisés fonctionnent bien ensemble et contribuent harmonieusement à un objectif commun. Ces orchestrateurs ont de nombreuses responsabilités, dont nous avons discuté en détail. Nous avons également fourni un bref aperçu des orchestrateurs de conteneurs les plus importants du marché.
Dans ce chapitre, nous allons présenter Kubernetes . Kubernetes est actuellement le leader incontesté de l’espace d’orchestration de conteneurs. Nous commençons par un aperçu de haut niveau de l’architecture d’un cluster Kubernetes, puis nous discuterons des principaux objets utilisés dans Kubernetes pour définir et exécuter des applications conteneurisées.
Les sujets abordés dans ce chapitre sont les suivants :
- Architecture
- Maîtres Kubernetes
- Noeuds de cluster
- Introduction à MiniKube
- Prise en charge de Kubernetes dans Docker pour Mac et Docker pour Windows
- Pods
- Kubernetes ReplicaSet
- Déploiement de Kubernetes
- Service Kubernetes
- Routage contextuel
Après avoir terminé ce chapitre, vous pourrez effectuer les opérations suivantes :
- Rédiger l’architecture de haut niveau d’un cluster Kubernetes sur une serviette
- Expliquer trois à quatre caractéristiques principales d’un pod Kubernetes
- Décrire le rôle de Kubernetes ReplicaSets en deux à trois phrases courtes
- Expliquer les deux à trois principales responsabilités d’un service Kubernetes
- Créer un pod dans Minikube
- Configurer Docker pour Mac ou Windows pour utiliser Kubernetes comme orchestrateur
- Créer un déploiement dans Docker pour Mac ou Windows
- Créer un service Kubernetes pour exposer un service d’application en interne (ou en externe) au cluster
Exigences techniques
Le lien vers les fichiers de code peut être trouvé ici à https://github.com/appswithdockerandkubernetes/labs/tree/master/ch10.
Architecture
Un cluster Kubernetes se compose d’un ensemble de serveurs. Ces serveurs peuvent être des machines virtuelles ou des serveurs physiques. Ces derniers sont également appelés métal nu . Chaque membre du cluster peut avoir l’un des deux rôles. Il s’agit soit d’un maître Kubernetes, soit d’un nœud (travailleur). Le premier est utilisé pour gérer le cluster, tandis que le second exécutera la charge de travail de l’application. J’ai mis l’ouvrier entre parenthèses, car dans le langage Kubernetes, vous ne parlez d’un nœud que lorsque vous parlez d’un serveur qui exécute la charge de travail d’une application. Mais dans le langage Docker et dans Swarm, l’équivalent est un nœud de travail. Je pense que la notion de nœud de travail décrit mieux le rôle du serveur qu’un simple nœud.
Dans un cluster, vous avez un petit nombre impair de maîtres et autant de nœuds de travail que nécessaire. Les petits clusters peuvent n’avoir que quelques nœuds de travail, tandis que les clusters plus réalistes peuvent avoir des dizaines voire des centaines de nœuds de travail. Techniquement, il n’y a pas de limite sur le nombre de nœuds de travail qu’un cluster peut avoir ; en réalité, vous pouvez cependant subir un ralentissement significatif de certaines opérations de gestion lorsque vous traitez avec des milliers de nœuds. Tous les membres du cluster doivent être connectés par un réseau physique, le soi-disant réseau sous – jacent.
Kubernetes définit un réseau plat pour l’ensemble du cluster. Kubernetes ne fournit aucune implémentation de réseau prête à l’emploi, mais s’appuie sur des plugins de tiers. Kubernetes ne définit que la Container Network Interface (CNI) et laisse l’implémentation à d’autres. Le CNI est assez simple. Il indique essentiellement que chaque pod s’exécutant dans le cluster doit pouvoir atteindre tout autre pod également exécuté dans le cluster sans qu’aucune traduction d’adresse réseau (NAT) ne se produise entre les deux. La même chose doit être vraie entre les nœuds de cluster et les pods; c’est-à-dire que les applications ou les démons s’exécutant directement sur un nœud de cluster doivent pouvoir atteindre chaque pod du cluster, et vice versa.
Dans le diagramme suivant, j’essaie d’illustrer l’architecture de haut niveau d’un cluster Kubernetes :
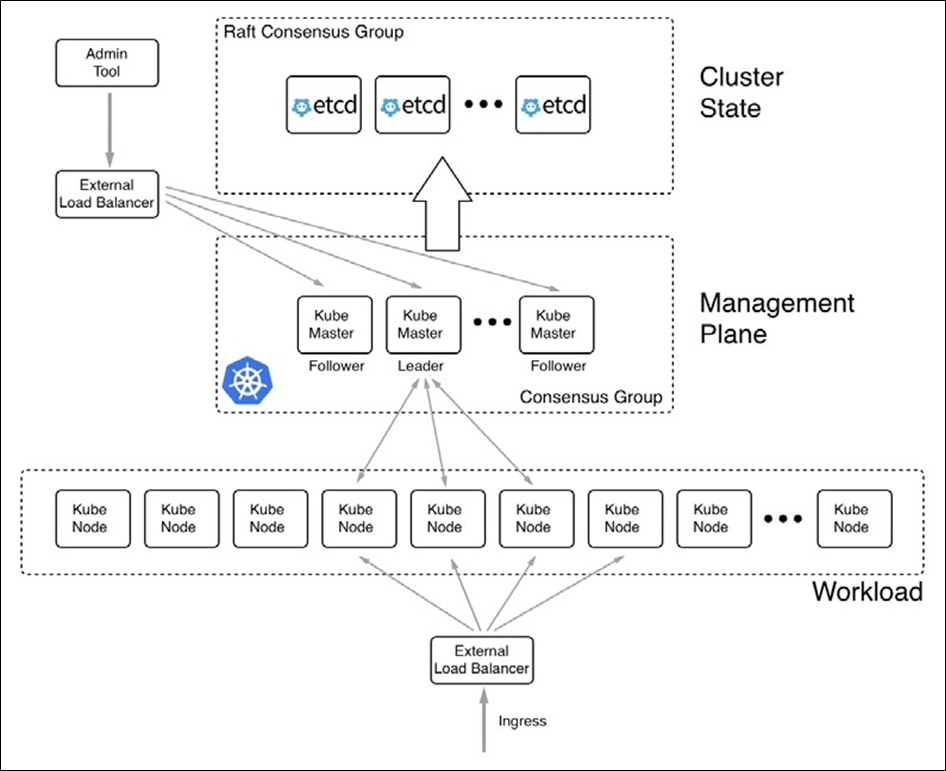
Diagramme d’architecture de haut niveau de Kubernetes
Le diagramme précédent est expliqué comme suit :
- En haut au centre, nous avons un cluster de nœuds etcd. etcd est un magasin de valeurs-clés distribué qui, dans un cluster Kubernetes, est utilisé pour stocker tous les états du cluster. Le nombre de nœuds etcd doit être impair, comme le prescrit le protocole de consensus Raft, qu’ils utilisent pour se coordonner entre eux. Lorsque nous parlons de l’état du cluster, nous n’incluons pas les données produites ou consommées par les applications s’exécutant dans le cluster, mais nous parlons plutôt de toutes les informations sur la topologie du cluster, quels services sont en cours d’exécution, paramètres réseau, secrets utilisés, et plus encore. Cela dit, ce cluster etcd est vraiment essentiel à la mission du cluster, et, par conséquent, nous ne devrions jamais exécuter qu’un seul serveur etcd dans un environnement de production ou tout environnement qui doit être hautement disponible.
- Nous avons alors un cluster de nœuds maîtres Kubernetes qui forment également un groupe de consensus entre eux, semblable aux nœuds etcd. Le nombre de nœuds maîtres doit également être un nombre impair. Nous pouvons exécuter le cluster avec un seul maître, mais nous ne devons jamais le faire dans un système de production ou critique. Là, nous devons toujours avoir au moins trois nœuds maîtres. Étant donné que les nœuds maîtres sont utilisés pour gérer l’ensemble du cluster, nous parlons également du plan de gestion. Les nœuds maîtres utilisent le cluster etcd comme magasin de sauvegarde. Il est recommandé de placer un équilibreur de charge (LB) devant les nœuds maîtres avec un nom de domaine complet (FQDN) bien connu, tel que https://admin.example.com. Tous les outils utilisés pour gérer le cluster Kubernetes doivent y accéder via ce LB, plutôt que d’utiliser l’adresse IP publique de l’un des nœuds maîtres. Ceci est illustré dans le coin supérieur gauche du diagramme précédent.
- Vers le bas du diagramme, nous avons un cluster de nœuds de travail.
Le nombre de nœuds peut être aussi faible que 1 et n’a pas de limite supérieure. Les nœuds maître et travailleur Kubernetes communiquent entre eux. Il s’agit d’une forme de communication bidirectionnelle, différente de celle que nous connaissons de Docker Swarm. Dans Docker Swarm, seuls les nœuds de gestionnaire communiquent avec les nœuds de travail et jamais l’inverse. Tout le trafic entrant accédant aux applications exécutées dans le cluster doit passer par un autre équilibreur de charge. Il s’agit de l’équilibreur de charge d’application ou du proxy inverse. Nous ne voulons jamais que le trafic externe accède directement à l’un des nœuds de travail.
Maintenant que nous avons une idée de l’architecture de haut niveau d’un cluster Kubernetes, approfondissons un peu et examinons d’abord les nœuds maître et travailleur Kubernetes.
Nœuds maîtres Kubernetes
Les nœuds maîtres Kubernetes sont utilisés pour gérer un cluster Kubernetes. Ce qui suit est un schéma de haut niveau d’un tel maître :
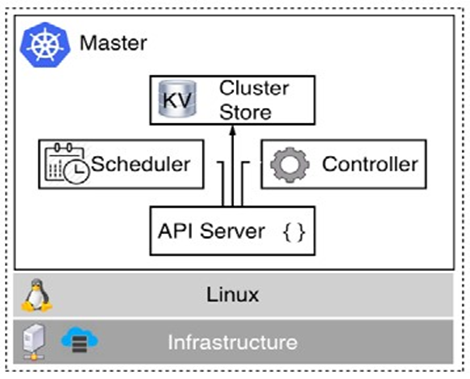
Kubernetes master
Au bas du diagramme précédent, nous avons l’infrastructure, qui peut être une machine virtuelle sur site, dans le cloud ou sur un serveur (souvent appelé bare metal ). Actuellement, les maîtres Kubernetes ne fonctionnent que sous Linux. Les distributions Linux les plus populaires, telles que RHEL, CentOS et Ubuntu, sont prises en charge. Sur cette machine Linux, nous avons ensuite au moins les quatre services Kubernetes suivants en cours d’exécution :
- Serveur API : il s’agit de la passerelle vers Kubernetes. Toutes les demandes pour répertorier, créer, modifier ou supprimer des ressources du cluster doivent passer par ce service. Il expose une interface REST que des outils tels que kubectl utilisent pour gérer le cluster et les applications du cluster.
- Contrôleur : le contrôleur, ou plus précisément le gestionnaire de contrôleurs, est une boucle de contrôle qui observe l’état du cluster via le serveur API et effectue des modifications, tentant de déplacer l’état actuel ou effectif vers l’état souhaité.
- Planificateur : le planificateur est un service qui fait de son mieux pour planifier des pods sur les nœuds de travail en tenant compte de diverses conditions aux limites, telles que les exigences en matière de ressources, les politiques, les exigences de qualité de service, etc.
- Magasin de cluster : il s’agit d’une instance de etcd qui est utilisée pour stocker toutes les informations sur l’état du cluster.
Pour être plus précis, etcd, qui est utilisé comme magasin de cluster, ne doit pas nécessairement être installé sur le même nœud que les autres services Kubernetes. Parfois, les clusters Kubernetes sont configurés qui utilisent des clusters autonomes de serveurs etcd, comme indiqué dans le diagramme d’architecture de la section précédente. Mais quelle variante utiliser est une décision de gestion avancée et sort du cadre de cet article.
Nous avons besoin d’au moins un maître, mais pour atteindre une haute disponibilité, nous avons besoin de trois nœuds maîtres ou plus. Ceci est très similaire à ce que nous avons appris sur les nœuds de gestionnaire d’un Docker Swarm. À cet égard, un maître Kubernetes équivaut à un nœud de gestionnaire Swarm.
Les maîtres Kubernetes n’exécutent jamais la charge de travail d’une application. Leur seul objectif est de gérer le cluster. Les maîtres de Kubernetes construisent un groupe de consensus Raft . Le protocole Raft est un protocole standard utilisé dans les situations où un groupe de membres doit prendre des décisions. Il est utilisé dans de nombreux logiciels bien connus tels que MongoDB, Docker SwarmKit et Kubernetes. Pour une discussion plus approfondie du protocole Raft, voir le lien dans la section Lectures complémentaires.
Comme nous l’avons mentionné dans la section précédente, l’état du cluster Kubernetes est stocké dans etcd. Si le cluster Kubernetes est supposé être hautement disponible, alors etcd doit également être configuré en mode haute disponibilité, ce qui signifie normalement que l’une a au moins trois instances etcd s’exécutant sur différents nœuds.
Disons encore une fois que tout l’état du cluster est stocké dans etcd. Cela inclut toutes les informations sur tous les nœuds de cluster, tous les jeux de réplicas, les déploiements, les secrets, les stratégies réseau, les informations de routage, etc. Il est donc crucial que nous ayons une stratégie de sauvegarde robuste en place pour ce magasin de valeurs-clés.
Examinons maintenant les nœuds qui exécuteront la charge de travail réelle du cluster.
Nœuds de cluster
Les nœuds de cluster sont les nœuds sur lesquels Kubernetes planifie la charge de travail d’une application. Ils sont les chevaux de bataille du cluster. Un cluster Kubernetes peut avoir quelques, des dizaines, des centaines, voire des milliers de nœuds de cluster. Kubernetes a été construit à partir de zéro pour une évolutivité élevée. N’oubliez pas que Kubernetes a été calqué sur Google Borg, qui gère des dizaines de milliers de conteneurs depuis des années :
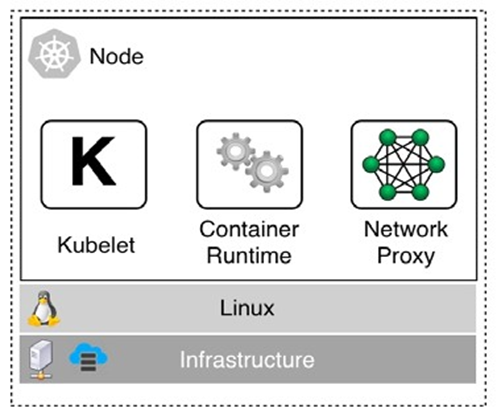
Noeud de travail Kubernetes
Un nœud de travail peut s’exécuter sur une machine virtuelle ou sur du métal nu, sur site ou dans le cloud. À l’origine, les nœuds de travail ne pouvaient être configurés que sur Linux. Mais depuis la version 1.10 de Kubernetes, les nœuds de travail peuvent également fonctionner sur Windows Server 2010. Il est parfaitement correct d’avoir un cluster mixte avec des nœuds de travail Linux et Windows.
Sur chaque nœud, nous avons trois services à exécuter, qui sont décrits comme suit :
- Kubelet : il s’agit du premier et principal service. Kubelet est ce qu’on appelle l’agent de nœud principal. Le service Kubelet utilise les spécifications des pods pour s’assurer que tous les conteneurs des pods correspondants fonctionnent et sont sains. Les spécifications des pods sont des fichiers écrits au format YAML ou JSON et décrivent de manière déclarative un pod. Nous apprendrons à connaître les modules dans la section suivante. Les PodSpecs sont fournis à Kubelet principalement via le serveur API.
- Container Runtime : le deuxième service qui doit être présent sur chaque nœud de travail est un runtime de conteneur. Kubernetes, par défaut, utilise containerd depuis la version 1.9 comme runtime de conteneur. Avant cela, il aurait utilisé le démon Docker. D’autres temps d’exécution de conteneurs, tels que rkt ou CRI-O, peuvent être utilisés. Le runtime du conteneur est responsable de la gestion et de l’exécution des conteneurs individuels d’un pod.
- kube-proxy : Enfin, il y a kube-proxy . Il s’exécute en tant que démon et est un simple proxy réseau et équilibreur de charge pour tous les services d’application exécutés sur ce nœud particulier.
Maintenant que nous avons appris l’architecture de Kubernetes et les nœuds maître et travailleur, il est temps d’introduire les outils que nous pouvons utiliser pour développer des applications ciblées sur Kubernetes.
Présentation de Minikube
Minikube est un outil qui crée un cluster Kubernetes à nœud unique dans VirtualBox ou Hyper-V (d’autres hyperviseurs sont pris en charge) prêt à être utilisé lors du développement d’une application conteneurisée. Nous avons montré au chapitre 2, Configuration d’un environnement de travail , comment Minikube, et avec lui, l’outil kubectl peut être installé sur votre ordinateur portable Mac ou Windows. Comme indiqué, Minikube est un cluster Kubernetes à nœud unique et, par conséquent, le nœud est à la fois un maître Kubernetes et un nœud de travail.
Assurons-nous que Minikube fonctionne avec la commande suivante :
$ minikube start
Une fois que Minikube est prêt, nous pouvons accéder à son cluster à nœud unique en utilisant kubectl. Et nous devrions voir quelque chose de similaire à la capture d’écran suivante :

Liste de tous les nœuds dans Minikube
Comme mentionné précédemment, nous avons un cluster à nœud unique avec un nœud appelé minikube. Ne soyez pas dérouté par la valeur <aucun> dans la colonne ROLES ; le nœud joue à la fois le rôle d’un travailleur et d’un nœud maître.
Maintenant, essayons de déployer un pod sur ce cluster. Ne vous inquiétez pas de ce qu’est exactement un pod en ce moment ; nous allons approfondir tous les détails à ce sujet plus loin dans ce chapitre. Pour l’instant, prenez-le tel quel.
Nous pouvons utiliser le fichier sample-pod.yaml dans le sous-dossier ch10 de notre dossier labs pour créer un tel pod. Il a le contenu suivant :
apiVersion: v1
kind: Pod metadata:
name: nginx spec:
containers:
– name: nginx
image: nginx:alpine
ports:
containerPort: 80
containerPort: 443
Utilisons la CLI Kubernetes appelée kubectl pour déployer ce pod :
$ kubectl create -f sample-pod.yaml pod “nginx” created
Si nous listons maintenant tous les pods, nous devrions voir ceci :
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 51s
Pour pouvoir accéder à ce pod, nous devons créer un service. Utilisons le fichier sample-service.yaml , qui a le contenu suivant:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: LoadBalancer
ports:
– port: 8080
targetPort: 80
protocol: TCP
name: http
– port: 443
protocol: TCP
name: https
selector:
app: nginx
Encore une fois, ne vous inquiétez pas de ce qu’est exactement un service en ce moment. Nous expliquerons tout cela en détail plus loin. Créons simplement ce service:
$ kubectl create -f sample-service.yaml
Maintenant, nous pouvons utiliser curl pour accéder au service :
$ curl -4 http://localhost
Nous devrions recevoir la page d’accueil de Nginx comme réponse. Avant de continuer, veuillez supprimer les deux objets que vous venez de créer :
$ kubectl delete po/nginx
$ kubectl delete svc/nginx-service
Prise en charge de Kubernetes dans Docker for Desktop
À partir de la version 18.01-ce, Docker pour Mac et Docker pour Windows ont commencé à prendre en charge Kubernetes prêt à l’emploi. Les développeurs qui souhaitent déployer leurs applications conteneurisées sur Kubernetes peuvent utiliser cet orchestrateur au lieu de SwarmKit. La prise en charge de Kubernetes par défaut est désactivée et doit être activée dans les paramètres. La première fois que Kubernetes est activé, Docker pour Mac ou Windows aura besoin d’un moment pour télécharger tous les composants nécessaires à la création d’un cluster Kubernetes à nœud unique. Contrairement à Minikube, qui est également un cluster à nœud unique, la version fournie par les outils Docker utilise des versions conteneurisées de tous les composants Kubernetes :
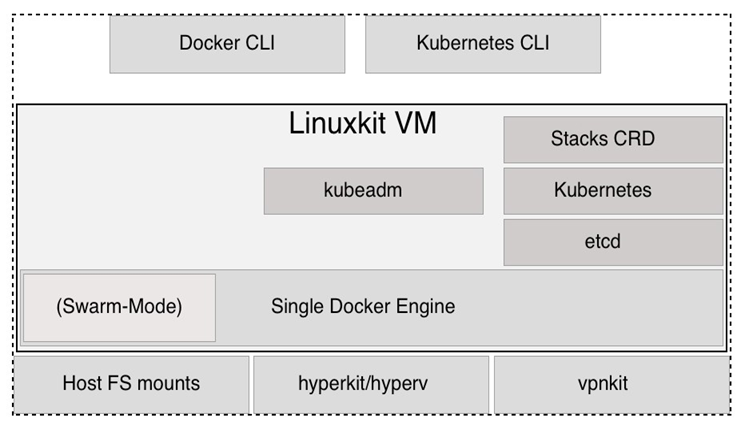
Prise en charge de Kubernetes dans Docker pour Mac et Windows
Le diagramme précédent donne un aperçu général de la façon dont la prise en charge de Kubernetes a été ajoutée à Docker pour Mac et Windows. Docker pour Mac utilise l’hyperkit pour exécuter une machine virtuelle basée sur LinuxKit. Docker pour Windows utilise Hyper-V pour obtenir le même résultat. À l’intérieur de la machine virtuelle, le moteur Docker est installé. Une partie du moteur est SwarmKit, qui active le mode Swarm. Docker pour Mac ou Windows utilise l’outil kubeadm pour installer et configurer Kubernetes dans cette machine virtuelle. Les trois faits suivants méritent d’être mentionnés :
- Kubernetes stocke son état de cluster dans etcd; ainsi, nous avons etcd en cours d’exécution sur cette machine virtuelle.
- Ensuite, nous avons tous les services qui composent Kubernetes.
- Enfin, certains services qui prennent en charge le déploiement de piles Docker de la Docker CLI dans Kubernetes. Ce service ne fait pas partie de la distribution officielle de Kubernetes, mais est spécifique à Docker.
Tous les composants de Kubernetes s’exécutent dans des conteneurs dans LinuxKit VM. Ces conteneurs peuvent être masqués via un paramètre dans Docker pour Mac ou Windows. Voir plus loin dans la section pour une liste complète des conteneurs système Kubernetes exécutés sur votre ordinateur portable, si la prise en charge de Kubernetes est activée. Pour éviter les répétitions, à partir de maintenant, je ne parlerai que de Docker pour Desktop, au lieu de Docker pour Mac et Docker pour Windows. Tout ce que je vais dire s’applique également aux deux éditions.
Un gros avantage de Docker for Desktop avec Kubernetes activé sur Minikube est que le premier permet aux développeurs d’utiliser un seul outil pour créer, tester et exécuter une application conteneurisée destinée à Kubernetes. Il est même possible de déployer une application multiservice dans Kubernetes, à l’aide d’un fichier Docker Compose.
Maintenant, salissons-nous les mains :
1. Tout d’abord, nous devons activer Kubernetes.
2. Sur le Mac, cliquez sur l’icône Docker dans la barre de menu et sélectionnez Préférences.
3. Dans la boîte de dialogue qui s’ouvre, sélectionnez l’option Kubernetes, comme indiqué dans la capture d’écran suivante :
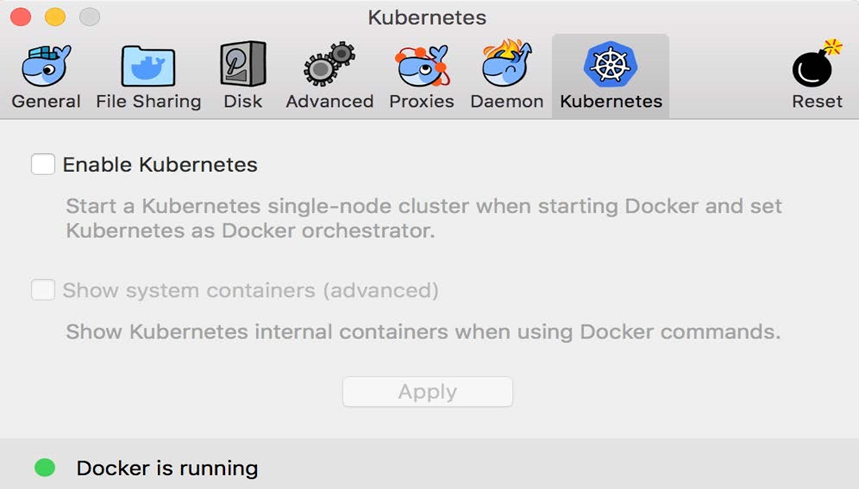
Activation de Kubernetes dans Docker pour Mac
4. Ensuite, sélectionnez l’option Activer Kubernetes case à cocher. Cochez également la case Afficher les conteneurs système (avancés).
5. Cliquez sur le bouton Appliquer. Vous serez averti que l’installation et la configuration de Kubernetes prend quelques minutes :
Avertissement que l’installation et la configuration de Kubernetes prennent un certain temps
6. Cliquez sur le bouton Installer pour démarrer l’installation. Il est maintenant temps de faire une pause et de déguster une bonne tasse de thé.
Une fois l’installation terminée (Docker nous en informe en affichant une icône d’état verte dans la boîte de dialogue des paramètres), nous pouvons la tester. Puisque nous avons maintenant deux clusters Kubernetes en cours d’exécution sur notre ordinateur portable, Minikube et Docker pour Mac, nous devons configurer kubectl pour accéder à ce dernier. D’abord, listons tous les contextes que nous avons :

Liste des contextes pour kubectl
Ici, nous pouvons voir que, sur mon ordinateur portable, j’ai les deux contextes mentionnés précédemment. Actuellement encore, le contexte Minikube est actif, visible par l’astérisque dans la colonne ACTUELLE. Nous pouvons basculer vers le contexte docker-for-desktop à l’aide de la commande suivante :

Modification du contexte pour la CLI Kubernetes
Nous pouvons maintenant utiliser Kubectl pour accéder au cluster que Docker pour Mac vient de créer. Nous devrions voir ceci :

Le cluster Kubernetes à nœud unique créé par Docker pour Mac
OK, cela semble très familier. C’est à peu près la même chose que ce que nous avons vu en travaillant avec Minikube. La version de Kubernetes que mon Docker pour Mac utilise est la 1.9.2. Nous pouvons également voir que le nœud est un nœud maître.
Si nous répertorions tous les conteneurs en cours d’exécution sur notre Docker pour Mac, nous obtenons cette liste (notez que j’utilise l’argument –format pour afficher uniquement l’ID de conteneur et les noms des conteneurs), comme indiqué dans la capture d’écran suivante :
Dans la liste, nous pouvons identifier tous les composants désormais familiers qui composent Kubernetes, tels que les suivants :
- Serveur API
- etcd
- Proxy Kube
- Service DNS
- Contrôleur Kube
- Planificateur Kube
Il existe également des conteneurs contenant le mot composer. Ce sont des services spécifiques à Dockers qui sont utilisés pour nous permettre de déployer des applications Docker Compose sur Kubernetes. Docker traduit la syntaxe Docker Compose et crée implicitement les objets Kubernetes nécessaires tels que les déploiements, les pods et les services.
Normalement, nous ne voudrions pas encombrer notre liste de conteneurs avec ces conteneurs système. Nous pouvons donc décocher la case Afficher les conteneurs système dans les paramètres de Kubernetes.
Essayons maintenant de déployer une application Docker Compose sur Kubernetes. Accédez au sous-dossier ch10 de notre dossier labs . Nous déployons l’application sous forme de pile à l’aide du fichier docker-compose.yml :
$ docker stack deploy -c docker-compose.yml app Voici ce que nous voyons:

Déployer la pile sur Kubernetes
Nous pouvons tester l’application, par exemple, en utilisant curl , et nous verrons qu’elle fonctionne comme prévu:
Application d’animaux domestiques exécutée dans Kubernetes sur Docker pour Mac
Maintenant, vous devriez être curieux et vous demander ce qu’a fait exactement Docker lorsque nous avons exécuté la commande de déploiement de la pile de dockers. Nous pouvons utiliser kubectl pour découvrir :
Une liste de tous les objets Kubernetes, créés par la commande docker stack deploy
Docker a créé un déploiement pour le service Web et un ensemble avec état pour le service db . Il a également créé automatiquement les services Kubernetes pour le Web et la base de données afin qu’ils soient accessibles à l’intérieur du cluster. Il a également créé le service Kubernetes svc / Web-published , qui est utilisé pour l’accès externe.
C’est assez cool pour le moins et diminue considérablement les frictions dans le processus de développement pour les équipes ciblant Kubernetes en tant qu’orchestrateur.
Avant de continuer, veuillez supprimer la pile du cluster :
$ docker stack rm app
Assurez-vous également de réinitialiser le contexte de kubectl sur Minikube, car nous utiliserons Minikube pour tous nos exemples dans ce chapitre :
$ kubectl config use-context minikube
Maintenant que nous avons eu une introduction aux outils que nous pouvons utiliser pour développer des applications qui s’exécuteront éventuellement dans un cluster Kubernetes, il est temps de se renseigner sur tous les objets Kubernetes importants qui sont utilisés pour définir et gérer une telle application. Nous commençons par le pod.
Pods
Contrairement à ce qui est possible dans un Docker Swarm, vous ne pouvez pas exécuter de conteneurs directement dans un cluster Kubernetes. Dans un cluster Kubernetes, vous ne pouvez exécuter que des pods. Les pods sont l’unité atomique de déploiement dans Kubernetes. Un pod est l’abstraction d’un ou de plusieurs conteneurs colocalisés qui partagent les mêmes espaces de noms du noyau, tels que l’espace de noms de réseau. Aucun équivalent n’existe dans le Docker SwarmKit. Le fait que plusieurs conteneurs puissent être colocalisés et partager le même espace de noms réseau est un concept très puissant. Le diagramme suivant illustre deux modules :
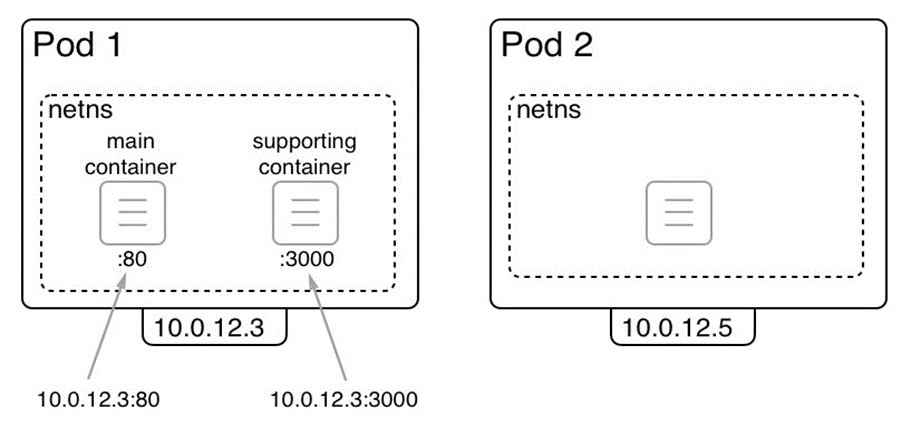
Dans le diagramme précédent, nous avons deux pods, Pod 1 et Pod 2. Le premier pod contient deux conteneurs, tandis que le second ne contient qu’un seul conteneur. Chaque pod obtient une adresse IP attribuée par Kubernetes qui est unique dans l’ensemble du cluster Kubernetes. Dans notre cas, ce sont les adresses IP 10.0.12.3 et 10.0.12.5. Les deux font partie d’un sous-réseau privé géré par le pilote de réseau Kubernetes.
Un pod peut contenir un ou plusieurs conteneurs. Tous ces conteneurs partagent les mêmes espaces de noms du noyau, et en particulier ils partagent l’espace de noms du réseau. Ceci est marqué par le rectangle en pointillés entourant les conteneurs. Étant donné que tous les conteneurs exécutés dans le même pod partagent l’espace de noms réseau, chaque conteneur doit s’assurer d’utiliser son propre port, car les ports en double ne sont pas autorisés dans un seul espace de noms réseau. Dans ce cas, dans le pod 1, le conteneur principal utilise le port 80, tandis que le conteneur de support utilise le port 3000.
Les demandes provenant d’autres pods ou nœuds peuvent utiliser l’adresse IP du pod combinée avec le numéro de port correspondant pour accéder aux conteneurs individuels. Par exemple, vous pouvez accéder à l’application s’exécutant dans le conteneur principal du pod 1 à 10.0.12.3:80.
Comparaison des réseaux Docker Container et Kubernetes pod
Comparons maintenant la mise en réseau de conteneurs de Docker et la mise en réseau d’un pod Kubernetes. Dans le diagramme ici, nous avons le premier sur le côté gauche et le dernier sur le côté droit :
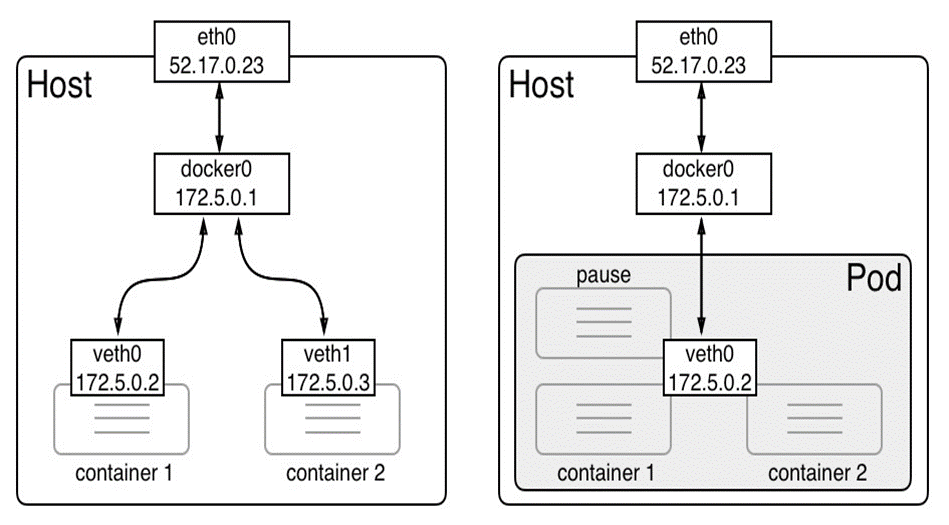
Conteneurs dans l’espace de noms du réseau de partage de pod
Lorsqu’un conteneur Docker est créé et qu’aucun réseau spécifique n’est spécifié, le moteur Docker crée un point de terminaison Ethernet virtuel (veth). Le premier conteneur obtient veth0, et le suivant obtient veth1 , et ainsi de suite. Ces points de terminaison Ethernet virtuels sont connectés au pont Linux docker0 que Docker crée automatiquement lors de l’installation. Le trafic est acheminé du pont docker0 vers chaque noeud final Veth connecté. Chaque conteneur a son propre espace de noms réseau. Deux conteneurs n’utilisent pas le même espace de noms. Ceci est délibéré, pour isoler les applications s’exécutant à l’intérieur des conteneurs les unes des autres.
Pour un pod Kubernetes, la situation est différente. Lors de la création d’un nouveau pod, Kubernetes crée d’abord un soi-disant conteneur de pause, dont le seul but est de créer et de gérer les espaces de noms que le pod partagera avec tous les conteneurs. En dehors de cela, cela ne fait rien d’utile, mais ne fait que dormir. Le conteneur de pause est connecté au pont docker0 via veth0. Tout conteneur ultérieur qui fera partie du module utilise une fonctionnalité spéciale du moteur Docker qui lui permet de réutiliser un espace de noms réseau existant. La syntaxe pour ce faire ressemble à ceci :
$ docker container create –net container: pause …
La partie importante est l’argument –net, qui utilise comme conteneur de valeur : container:<container name>. Si nous créons un nouveau conteneur de cette façon, Docker ne crée pas de nouveau nœud final veth, mais le conteneur utilise le même que le conteneur de pause.
Une autre conséquence importante du fait que plusieurs conteneurs partagent le même espace de noms de réseau est la façon dont ils communiquent entre eux. Considérons la situation suivante d’un pod contenant deux conteneurs, l’un écoutant au port 80 et l’autre au port 3000 :
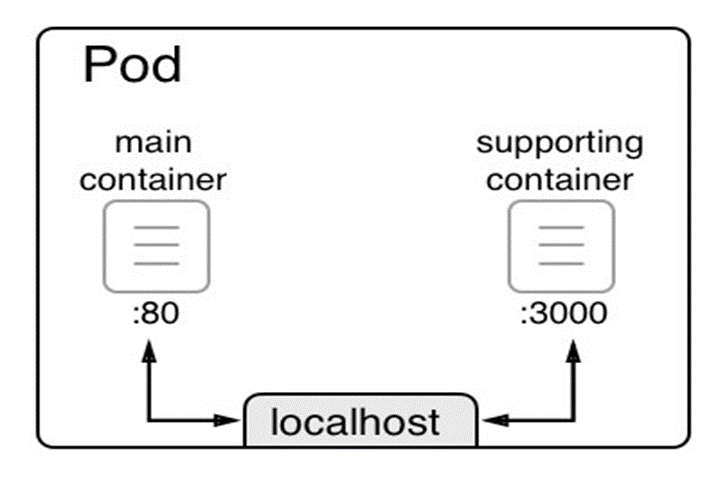
Les conteneurs dans les pods communiquent via localhost
Lorsque deux conteneurs utilisent le même espace de noms de réseau du noyau Linux, ils peuvent communiquer entre eux via localhost ; ceci est similaire à lorsque deux processus s’exécutent sur le même hôte, car ils peuvent également communiquer entre eux via localhost. Ceci est illustré dans le schéma précédent. Depuis le conteneur principal, l’application conteneurisée à l’intérieur peut atteindre le service s’exécutant à l’intérieur du conteneur de support via http://localhost:3000.
Partager l’espace de noms du réseau
Après toute cette théorie, vous vous demandez peut-être comment un pod est réellement créé par Kubernetes. Kubernetes utilise uniquement ce que Docker fournit. Alors, comment fonctionne ce partage d’espace de noms réseau ? Tout d’abord, Kubernetes crée le soi-disant conteneur de pause, comme mentionné précédemment. Ce conteneur n’a d’autre fonction que de réserver les espaces de noms du noyau pour ce pod et de les maintenir en vie, même si aucun autre conteneur à l’intérieur du pod n’est en cours d’exécution. Simulons alors la création d’un pod. Nous commençons par créer le conteneur de pause et prenons Nginx à cet effet :
$ docker container run -d –name pause nginx:alpine
Et maintenant, nous ajoutons un deuxième conteneur appelé main, en l’attachant au même espace de noms réseau que le conteneur de pause :
$ docker container run –name main -dit \
–net container:pause \ alpine:latest /bin/sh
Étant donné que la pause et l’exemple de conteneur font tous deux parties du même espace de noms réseau, ils peuvent se joindre via localhost. Pour montrer cela, nous devons d’abord exec dans le conteneur principal :
$ docker exec -it main /bin/sh
Nous pouvons maintenant tester la connexion à Nginx en cours d’exécution dans le conteneur de pause et en écoutant sur le port 80. Voici ce que nous obtenons si nous utilisons l’utilitaire wget pour ce faire :
Deux conteneurs partageant le même espace de noms réseau
La sortie montre que nous pouvons en effet accéder à Nginx sur localhost. C’est la preuve que les deux conteneurs partagent le même espace de noms. Si cela ne suffit pas, nous pouvons utiliser l’outil ip pour afficher eth0 à l’intérieur des deux conteneurs et nous obtiendrons exactement le même résultat, en particulier, la même adresse IP, qui est l’une des caractéristiques d’un pod, où tous ses conteneurs partagent la même adresse IP:

Affichage des propriétés de eth0 avec l’outil ip
Si nous inspectons le réseau de pont, nous pouvons voir que seul le conteneur de pause est répertorié. L’autre conteneur n’a pas obtenu d’entrée dans la liste des conteneurs, car il réutilise le point de terminaison du conteneur de pause :
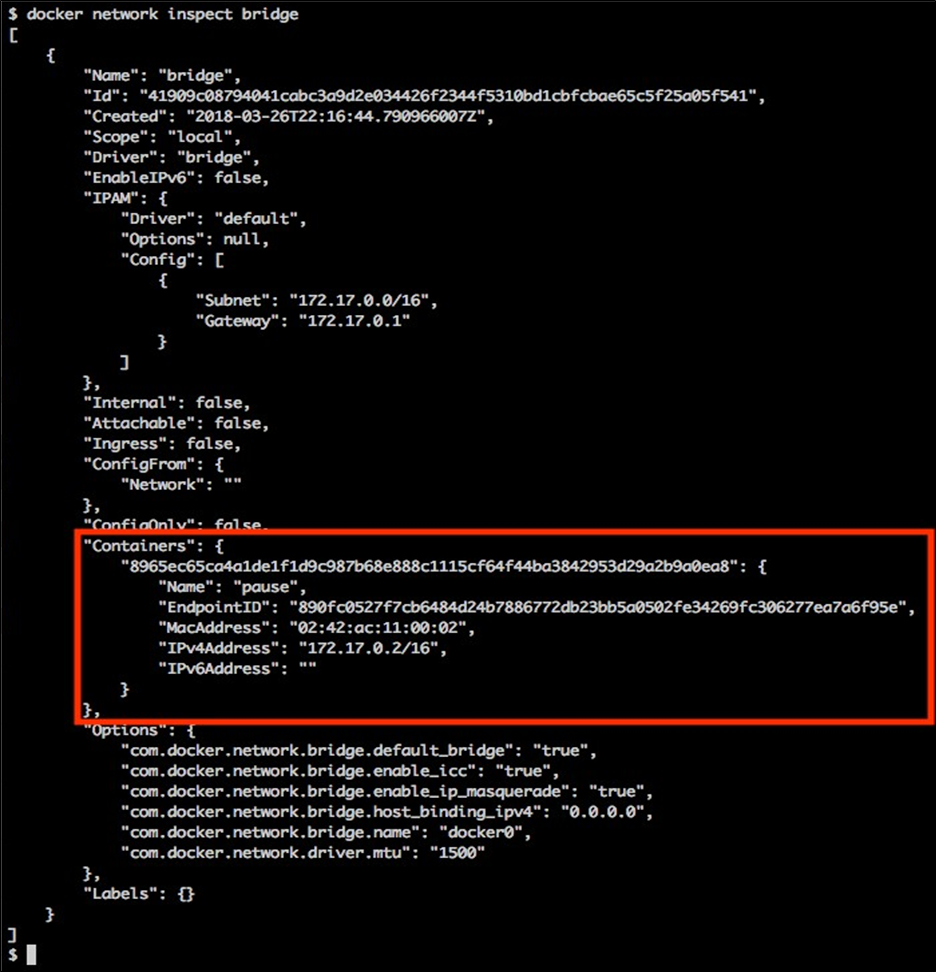
Inspection du réseau de ponts par défaut Docker
Cycle de vie des pods
Nous avons appris plus tôt dans cet article que les conteneurs ont un cycle de vie. Un conteneur est initialisé, exécuté et finalement quitté. Lorsqu’un conteneur se ferme, il peut le faire gracieusement avec un code de sortie zéro, ou il peut se terminer avec une erreur, ce qui équivaut à un code de sortie différent de zéro.
De même, un pod a un cycle de vie. En raison du fait qu’un pod peut contenir plusieurs conteneurs, ce cycle de vie est légèrement plus compliqué que celui d’un seul conteneur. Le cycle de vie d’un pod est illustré dans le diagramme suivant :
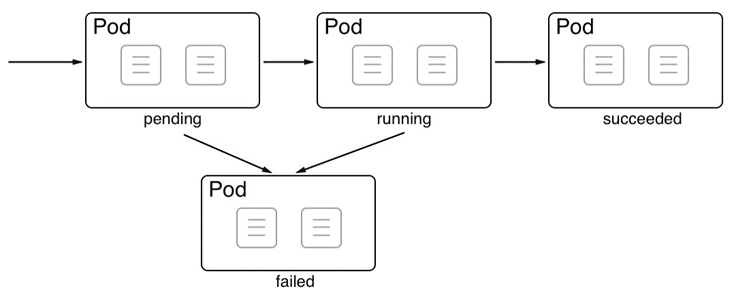
Cycle de vie des pods Kubernetes
Lorsqu’un pod est créé sur un nœud de cluster, il passe d’abord en état d’attente. Une fois que tous les conteneurs du pod sont opérationnels, le pod passe à l’état de fonctionnement. Le pod n’entre dans cet état que si tous ses conteneurs fonctionnent correctement. Si le pod est invité à se terminer, il demandera à tous ses conteneurs de se terminer. Si tous les conteneurs se terminent par un code de sortie de zéro, le pod entre en état de réussite. C’est le chemin heureux.
Examinons maintenant certains scénarios qui conduisent à l’échec du pod. Il existe trois scénarios possibles :
- Si, au démarrage du pod, au moins un conteneur ne peut pas s’exécuter et échoue (c’est-à-dire qu’il se ferme avec un code de sortie différent de zéro), le pod passe de l’état en attente à l’état en échec.
- Si la nacelle est en état de fonctionnement et l’un des conteneurs se bloque soudainement ou sort avec un code de sortie non nul, les transitions de pod de la course état dans l’état a échoué.
- Si le pod est invité à se terminer et pendant l’arrêt au moins un des conteneurs sort avec un code de sortie différent de zéro, le pod entre également dans l’état d’échec.
Spécification du pod
Lors de la création d’un pod dans un cluster Kubernetes, nous pouvons utiliser une approche impérative ou déclarative. Nous avons discuté de la différence entre les deux approches plus tôt dans cet article, mais pour reformuler l’aspect important, l’utilisation d’une approche déclarative signifie que nous écrivons un manifeste qui décrit l’état final que nous voulons atteindre. Nous laissons les détails du comment à l’orchestrateur. L’état final que nous voulons atteindre est également appelé l’état souhaité. En général, l’approche déclarative est fortement préférée dans tous les orchestrateurs établis, et Kubernetes ne fait pas exception.
Ainsi, dans ce chapitre, nous nous concentrerons exclusivement sur l’approche déclarative. Les manifestes ou les spécifications d’un pod peuvent être écrits au format YAML ou JSON. Dans ce chapitre, nous nous concentrerons sur YAML, car il est plus facile à lire pour nous les humains. Regardons un exemple de spécification. Voici le contenu dufichier pod.yaml qui se trouve dans le sous-dossier ch10 de notre dossier labs :
apiVersion: v1
kind: Pod
metadata:
name: web-pod
spec:
containers:
– name: web
image: nginx:alpine
ports:
– containerPort: 80
Chaque spécification dans Kubernetes commence par les informations de version. Les pods existent depuis un certain temps, et la version API est donc v1. La deuxième ligne spécifie le type d’objet ou de ressource Kubernetes que nous voulons définir. Évidemment, dans ce cas, nous voulons spécifier un pod. Vient ensuite un bloc avec des métadonnées. Au minimum, nous devons donner un nom au pod. Ici, nous l’appelons web-pod . Le bloc suivant qui suit est le bloc spec, qui contient la spécification du pod. La partie la plus importante (et la seule dans cet exemple simple) est la liste de tous les conteneurs qui font partie de ce module. Nous n’avons qu’un seul conteneur ici, mais plusieurs conteneurs sont possibles. Le nom que nous choisissons pour notre conteneur est web, et l’image du conteneur est nginx: alpine . Enfin, nous définissons la liste des ports que le conteneur expose.
Une fois que nous avons créé une telle spécification, nous pouvons l’appliquer au cluster à l’aide du kubectl CLI Kubernetes. Dans le terminal, accédez au sous-dossier ch10 et exécutez la commande suivante :
$ kubectl create -f pod.yaml
Cela répondra avec le pod “web-pod” créé. Nous pouvons alors lister tous les pods du cluster avec kubectl get pods :
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
web-pod 1/1 Running 0 2m
Comme prévu, nous avons l’un des pods en état de fonctionnement. Le pod est appelé web-pod , tel que défini. Nous pouvons obtenir des informations plus détaillées sur le pod en cours d’exécution à l’aide de la commande describe :
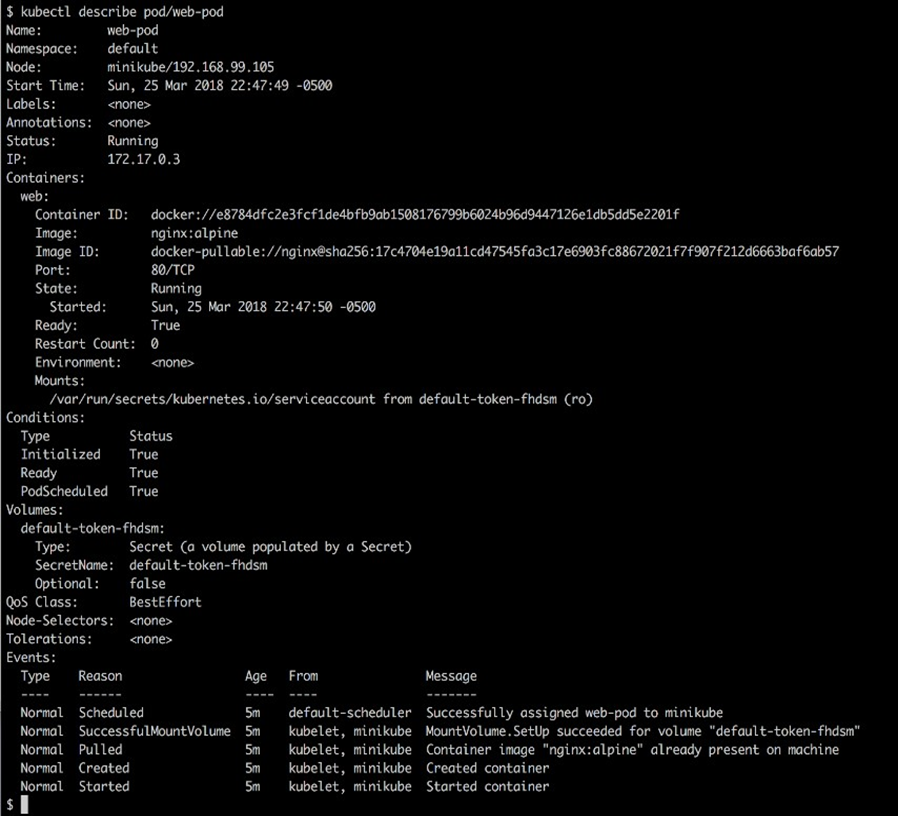
Décrire un pod en cours d’exécution dans le cluster
Veuillez noter la notation pod / web-pod dans la commande de description précédente. D’autres variantes sont possibles, par exemple pods / web-pod ou po / web-pod . pod et po sont des alias de pods . L’outil kubectl définit de nombreux alias, pour nous faciliter un peu la vie.
La commande de description nous donne une pléthore d’informations précieuses sur le pod, notamment la liste des événements qui se sont produits avec ce pod affecté. La liste est affichée à la fin de la sortie.
Les informations contenues dans la section conteneurs est très similaire à ce que nous trouvons dans un docker conteneur inspecter la sortie.
Nous pouvons également voir une section Volumes avec une entrée de type Secret. Nous discuterons des secrets de Kubernetes dans le prochain chapitre. Les volumes, d’autre part, sont discutés ci-dessous.
Pods et volumes
Dans le chapitre sur les conteneurs, nous avons découvert les volumes et leur objectif pour accéder et stocker des données persistantes. Comme les conteneurs peuvent monter des volumes, les pods peuvent également le faire. En réalité, ce sont vraiment les conteneurs à l’intérieur du pod qui montent les volumes, mais ce n’est qu’un détail sémantique. Voyons d’abord comment définir un volume dans Kubernetes. Kubernetes prend en charge une pléthore de types de volumes, et nous ne plongons pas trop dans les détails à ce sujet. Créons simplement un volume local implicitement en définissant un PersistentVolumeClaim appelé my-data-claim :
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-data-claim
spec:
accessModes:
– ReadWriteOnce
resources:
requests:
storage: 2Gi
Nous avons défini une revendication qui demande 2 Go de données. Créons cette revendication :
$ kubectl create -f volume-claim.yaml
Nous pouvons lister la revendication en utilisant kubectl (pvc est le raccourci pour PersistentVolumeClaim) :

Liste des objets PersistentStorageClaim dans le cluster
Dans la sortie, nous pouvons voir que la revendication a implicitement créé un volume appelé pvc- <ID> . Nous sommes maintenant prêts à utiliser le volume créé par la revendication dans un module. Utilisons une version modifiée de la spécification du pod que nous avons utilisée précédemment. Nous pouvons trouver cette spécification mise à jour dans le fichier pod-with-vol.yaml dans le dossier ch10 . Regardons cette spécification en détail :
apiVersion: v1
kind: Pod
metadata:
name: web-pod
spec:
containers:
– name: web
image: nginx:alpine
ports:
– containerPort: 80
volumeMounts:
– name: my-data
mountPath: /data
volumes:
– name: my-data
persistentVolumeClaim:
claimName: my-data-claim
Dans les quatre dernières lignes, dans les volumes de bloc, nous définissons la liste des volumes que nous voulons utiliser pour ce pod. Les volumes que nous listons ici peuvent être utilisés par n’importe lequel des conteneurs de la nacelle. Dans notre cas particulier, nous n’avons qu’un seul volume. Nous définissons que nous avons un volume mes-données qui est une revendication de volume persistante dont le nom de revendication est celui que nous venons de créer auparavant. Ensuite, dans la spécification du conteneur, nous avons le bloc volumeMounts, où nous définissons le volume que nous voulons utiliser et le chemin (absolu) à l’intérieur du conteneur où le volume sera monté. Dans notre cas, nous montons le volume dans le dossier / data du système de fichiers conteneur. Créons ce pod :
$ kubectl create -f pod-with-vol.yaml
Ensuite, nous pouvons exécuter dans le conteneur pour vérifier que le volume a monté en accédant au dossier /data, créer un fichier là-bas et quitter le conteneur :
$ kubectl exec -it web-pod — /bin/sh
/ # cd /data
/data # echo “Hello world!” > sample.txt
/data # exit
Si nous avons raison, les données de ce conteneur doivent persister au-delà du cycle de vie du pod. Ainsi, supprimons le pod, puis recréez-le et exécutez-le pour vous assurer que les données sont toujours là. Voici le résultat :
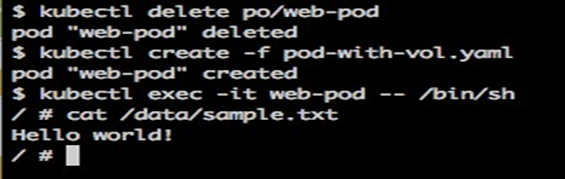
Les données stockées dans le volume survivent à la récréation du pod
Kubernetes ReplicaSet
Un seul pod dans un environnement avec des exigences de haute disponibilité est insuffisant. Et si le pod se bloque ? Que se passe-t-il si nous devons mettre à jour l’application s’exécutant à l’intérieur du pod mais que nous ne pouvons-nous permettre aucune interruption de service ? Ces questions et plus ne peuvent qu’indiquer que les pods seuls ne suffisent pas et que nous avons besoin d’un concept de niveau supérieur qui peut gérer plusieurs instances du même pod. Dans Kubernetes, le ReplicaSet est utilisé pour définir et gérer une telle collection de pods identiques qui s’exécutent sur différents nœuds de cluster. Entre autres, un ReplicaSet définit les images de conteneur utilisées par les conteneurs exécutés à l’intérieur d’un pod et le nombre d’instances du pod qui s’exécuteront dans le cluster. Ces propriétés et les nombreuses autres sont appelées l’état souhaité.
Le ReplicaSet est responsable de la réconciliation de l’état souhaité à tout moment, si l’état réel s’en écarte. Voici un ReplicaSet Kubernetes:
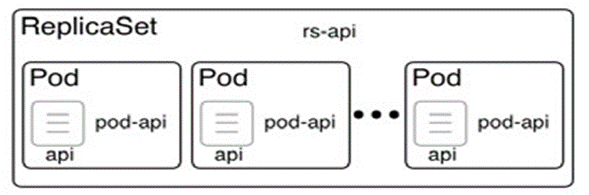
Kubernetes ReplicaSet
Dans le diagramme précédent, nous voyons un tel ReplicaSet appelé rs-api , qui régit un certain nombre de pods. Les gousses sont appelées pod-api . Le ReplicaSet est chargé de s’assurer qu’à tout moment il y a toujours le nombre souhaité de pods en cours d’exécution. Si l’un des pods se bloque pour une raison quelconque, le ReplicaSet planifie un nouveau pod sur un nœud avec des ressources gratuites à la place. S’il y a plus de pods que le nombre souhaité, le ReplicaSet tue les pods superflus. On peut donc dire que le ReplicaSet garantit un ensemble de pods auto-cicatrisant et évolutif. Il n’y a pas de limite sur le nombre de pods qu’un ReplicaSet peut comprendre.
Spécification ReplicaSet
Semblable à ce que nous avons appris sur les pods, Kubernetes nous permet également de définir et de créer impérativement ou déclarativement un ReplicaSet . Étant donné que l’approche déclarative est de loin la plus recommandée dans la plupart des cas, nous allons nous concentrer sur cette approche. Voici un exemple de spécification pour un ReplicaSet Kubernetes :
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: rs-web
spec:
selector:
matchLabels:
app: web
replicas: 3
template:
metadata:
labels:
app: web
spec:
containers:
– name: nginx
image: nginx:alpine
ports:
– containerPort: 80
Cela ressemble énormément à la spécification du pod que nous avons présentée plus tôt. Concentrons-nous donc sur les différences. Tout d’abord, sur la ligne 2, nous avons le type qui était Pod et qui est maintenant ReplicaSet. Ensuite, sur les lignes 6 à 8, nous avons un sélecteur qui détermine les pods qui feront partie du ReplicaSet. Dans ce cas, ce sont tous les pods qui ont une application d’étiquette avec la valeur web. Ensuite, à la ligne 9, nous définissons le nombre de répliques du pod que nous voulons exécuter, trois, dans ce cas. Enfin, nous avons la section modèle, qui définit d’abord les métadonnées, puis la spécification, qui définit les conteneurs qui s’exécutent à l’intérieur du pod. Dans notre cas, nous avons un seul conteneur utilisant l’image nginx: alpine et le port d’exportation 80.
Les éléments vraiment importants sont le nombre de répliques et le sélecteur qui spécifie l’ensemble de pods régis par le ReplicaSet .
Dans notre dossier ch10 , nous avons un fichier appelé replicaset.yaml qui contient exactement la spécification précédente. Utilisons ce fichier pour créer le ReplicaSet :
$ kubectl create -f replicaset.yaml replicaset “rs-web” created
Si nous répertorions tous les ReplicaSets dans le cluster, nous obtenons ceci ( rs est un raccourci pour replicaset ):
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
rs-web 3 3 3 51s
Dans la sortie précédente, nous pouvons voir que nous avons un seul ReplicaSet appelé rs-web dont l’état souhaité est trois (pods). L’état actuel montre également trois pods et les trois pods sont prêts. Nous pouvons également répertorier tous les pods du système, et nous obtenons ceci:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
rs-web-6qzld 1/1 Running 0 4m
rs-web-frj2m 1/1 Running 0 4m
rs-web-zd2kt 1/1 Running 0 4m
Ici, nous voyons nos trois pods attendus. Les noms des modules utilisent le nom du ReplicaSet avec un ID unique ajouté à chaque module. Dans la colonne PRET, nous voyons combien de conteneurs sont définis dans le pod et combien sont prêts. Dans notre cas, nous n’avons qu’un seul conteneur par capsule, et dans chaque cas, il est prêt. Ainsi, l’état général du module est en cours d’exécution. Nous voyons également combien de fois chaque pod a dû être redémarré. Dans notre cas, nous n’avons pas encore redémarré.
Auto-guérison
Maintenant, testons les pouvoirs magiques de l’auto-guérison du ReplicaSet en tuant au hasard l’un de ses pods et en observant ce qui va se passer. Supprimons le premier pod de la liste précédente :
$ kubectl delete po/rs-web-6qzld pod “rs-web-6qzld” deleted
Ensuite, listons à nouveau tous les pods. Nous nous attendons à ne voir que deux pods, non ? Faux :
Liste des pods après avoir tué un pod du ReplicaSet
OK, évidemment, le deuxième pod de la liste a été recréé comme nous pouvons le voir dans la colonne AGE. C’est l’auto-guérison en action. Voyons ce que nous découvrons si nous décrivons le ReplicaSet:
Décrire le ReplicaSet
Et, en effet, nous trouvons une entrée sous Événements qui nous indique que le ReplicaSet a créé le nouveau pod rs-web-q6cr7.
Déploiement de Kubernetes
Kubernetes prend très au sérieux le principe de la responsabilité unique. Tous les objets Kubernetes sont conçus pour faire une chose et une seule chose. Et ils sont conçus pour faire très bien cette seule chose. À cet égard, nous devons comprendre les ReplicaSets et les déploiements Kubernetes. Le ReplicaSet, comme nous l’avons appris, est responsable de la réalisation et de la réconciliation de l’état souhaité d’un service d’application. Cela signifie que le ReplicaSet gère un ensemble de modules.
Le déploiement augmente un ReplicaSet en fournissant des fonctionnalités de mise à jour et de restauration continues. Dans Docker Swarm, le service swarm incorporerait les fonctionnalités du ReplicaSet et du déploiement. À cet égard, SwarmKit est beaucoup plus monolithique que Kubernetes. Le diagramme suivant montre la relation entre un déploiement et un ReplicaSet:
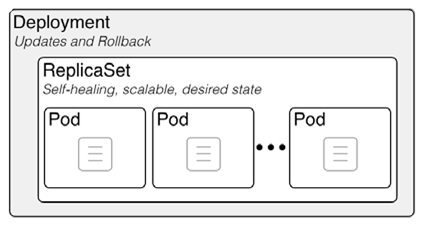
Déploiement de Kubernetes
Dans le diagramme précédent, le ReplicaSet définit et régit un ensemble de pods identiques. Les principales caractéristiques du ReplicaSet sont qu’il est auto-réparateur, évolutif et fait toujours de son mieux pour concilier l’état souhaité. Le déploiement de Kubernetes ajoute à son tour des fonctionnalités de mise à jour et de restauration continues à la plaque. À cet égard, un déploiement est vraiment un objet wrapper pour un ReplicaSet.
Nous en apprendrons davantage sur les mises à jour et les retours en arrière dans le prochain chapitre de cet article.
Service Kubernetes
Dès que nous commençons à travailler avec des applications composées de plusieurs services d’application, nous avons besoin de découvrir des services. Dans le diagramme suivant, nous illustrons ce problème :
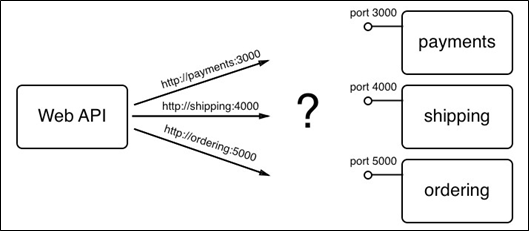
Découverte de service
Dans ce diagramme, nous avons un service d’API Web qui a besoin d’accéder à trois autres services : payments, shipping et ordering. L’API Web ne devrait à aucun moment se soucier de savoir comment et où trouver ces trois services. Dans le code API, nous voulons simplement utiliser le nom du service que nous voulons atteindre et son numéro de port. Un exemple serait l’URL http://paiements: 3000 qui est utilisé pour accéder à une instance du service de paiement.
Dans Kubernetes, le service d’application de paiement est représenté par un ReplicaSet de pods. En raison de la nature des systèmes hautement distribués, nous ne pouvons pas supposer que les pods ont des points de terminaison stables. Une cosse peut aller et venir en un clin d’œil. Mais c’est un problème si nous devons accéder au service d’application correspondant à partir d’un client interne ou externe. Si nous ne pouvons pas compter sur la stabilité des points d’extrémité des modules, que pouvons-nous faire d’autre ?
C’est là que les services Kubernetes entrent en jeu. Ils sont destinés à fournir des points de terminaison stables aux ReplicaSets ou aux déploiements, comme indiqué ici :
Service Kubernetes fournissant des points de terminaison stables aux clients
Dans le diagramme précédent, au centre, nous voyons un tel service Kubernetes. Il fournit une adresse IP fiable à l’échelle du cluster, également appelée IP virtuelle (VIP), ainsi qu’un port fiable unique dans l’ensemble du cluster. Les pods que le service Kubernetes assure par proxy sont déterminés par le sélecteur défini dans la spécification de service. Les sélecteurs sont toujours basés sur des étiquettes. Chaque objet Kubernetes peut avoir de zéro à plusieurs étiquettes attribuées. Dans notre cas, le sélecteur est app = web ; c’est-à-dire que tous les pods qui ont une étiquette appelée app avec une valeur de web sont mandatés.
Routage contextuel
Souvent, nous voulons configurer le routage contextuel pour notre cluster Kubernetes. Kubernetes nous propose différentes manières de le faire. La méthode préférée et la plus évolutive à ce stade consiste à utiliser un IngressController pour ce travail. Le diagramme suivant tente d’illustrer le fonctionnement de ce contrôleur d’entrée :
Routage basé sur le contexte à l’aide d’un contrôleur d’entrée Kubernetes
Dans ce diagramme, nous pouvons voir comment le routage basé sur le contexte (ou couche 7) fonctionne lors de l’utilisation d’un contrôleur d’entrée, tel que Nginx. Ici, nous avons un déploiement d’un service d’application appelé web. Tous les pods de ce service d’application ont une étiquette app = web. Nous avons ensuite un service Kubernetes appelé web qui fournit un point de terminaison stable à ces pods. Le service a une IP (virtuelle) de 52.14.0.13 et expose le port 30044. Autrement dit, si une demande parvient à un nœud du cluster Kubernetes pour le nom Web et le port 30044, elle est transmise à ce service. Le service équilibre ensuite la demande sur l’un des pods.
Jusqu’à présent, tout va bien, mais comment une demande d’entrée d’un client vers l’URL http [s]://example.com/web est-elle acheminée vers notre service Web ? Tout d’abord, nous devons définir le routage d’une demande basée sur le contexte vers une demande <service name> / <port> correspondante. Cela se fait via un objet Ingress:
1. Dans l’objet Ingress, nous définissons l’hôte et le chemin comme source et le nom (service), et le port comme cible. Lorsque cet objet Ingress est créé par le serveur API Kubernetes, un processus qui s’exécute en tant que side-car dans IngressController récupère cette modification.
2. Modifie le fichier de configuration du proxy inverse Nginx.
3. En ajoutant la nouvelle route, Nginx est alors invité à recharger sa configuration et pourra ainsi acheminer correctement toutes les demandes entrantes vers http [s]://example.com/web.
Résumé
Dans ce chapitre, nous avons appris les bases de Kubernetes. Nous avons eu un aperçu de son architecture et une introduction aux principales ressources utilisées pour définir et exécuter des applications dans un cluster Kubernetes. Nous avons également introduit la prise en charge de Minikube et Kubernetes pour Docker pour Mac et Windows.
Dans le chapitre suivant, nous allons déployer une application dans un cluster Kubernetes. Ensuite, nous allons mettre à jour l’un des services de cette application en utilisant une stratégie zéro temps d’arrêt. Enfin, nous allons instrumenter les services d’application fonctionnant dans Kubernetes avec des données sensibles, en utilisant des secrets. Restez à l’écoute.
Questions
Veuillez répondre aux questions suivantes pour évaluer ce que vous avez appris de ce chapitre:
1. Expliquez en quelques phrases courtes quel est le rôle d’un maître Kubernetes.
2. Énumérez les éléments qui doivent être présents sur chaque nœud Kubernetes (travailleur).
3. Vrai ou faux : nous ne pouvons pas exécuter des conteneurs individuels dans un cluster Kubernetes.
4. Expliquez la raison pour laquelle les conteneurs d’un pod peuvent utiliser localhost pour communiquer entre eux.
5. À quoi sert le soi-disant conteneur de pause dans un pod ?
6. Bob vous dit : Notre application se compose de trois images Docker : web, inventaire et db. Comme nous pouvons exécuter plusieurs conteneurs dans un pod Kubernetes, nous allons déployer tous les services de notre application dans un seul pod. Énumérez trois à quatre raisons pour lesquelles il s’agit d’une mauvaise idée.
7. Expliquez en vos propres mots pourquoi nous avons besoin de Kubernetes ReplicaSets.
8. Dans quelles circonstances avons-nous besoin de déploiements Kubernetes ?
9. Énumérez au moins trois types de services Kubernetes et expliquez leurs objectifs et leurs différences.
Déployer, mettre à jour et sécuriser une application avec Kubernetes
Dans le dernier chapitre, nous avons appris les bases de l’orchestrateur de conteneurs, Kubernetes. Nous avons eu un aperçu de haut niveau de l’architecture de Kubernetes et avons beaucoup appris sur les objets importants utilisés par Kubernetes pour définir et gérer une application conteneurisée.
Dans ce chapitre, nous apprendrons comment déployer, mettre à jour et faire évoluer des applications dans un cluster Kubernetes. Nous expliquerons également comment les déploiements sans temps d’arrêt sont atteints pour permettre des mises à jour et des annulations sans interruption des applications critiques. Enfin, dans ce chapitre, nous présentons les secrets de Kubernetes comme moyen de configurer les services avec et de protéger les données sensibles.
Le chapitre couvre les sujets suivants :
- Déployer une première application
- Déploiements sans interruption de service
Les secrets de Kubernetes :
- Après avoir parcouru ce chapitre, vous pourrez :
- Déployer une application multiservice dans un cluster Kubernetes
- Mettre à jour un service d’application fonctionnant dans Kubernetes sans provoquer de temps d’arrêt
- Définir des secrets dans un cluster Kubernetes
- Configurer un service d’application pour utiliser les secrets de Kubernetes
Exigences techniques
Dans ce chapitre, nous allons utiliser Minikube sur notre ordinateur local. Veuillez-vous référer au Chapitre 2, Configuration d’un environnement de travail, pour plus d’informations sur l’installation et l’utilisation de Minikube.
Le code de ce chapitre se trouve dans le sous-dossier ch11 du dossier jont.
Dans votre terminal, accédez au dossier labs/ch11.
Déployer une première application
Nous allons prendre notre application Pets , que nous avons introduite pour la première fois au chapitre 8 , Docker Compose , et la déployer dans un cluster Kubernetes. Notre cluster sera Minikube, qui, comme vous le savez, est un cluster à nœud unique. Mais, du point de vue d’un déploiement, peu importe la taille du cluster et son emplacement, dans le cloud, dans le centre de données de votre entreprise ou sur votre poste de travail personnel.
Déploiement du composant Web
Pour rappel, notre application se compose de deux services d’application, le Node composant Web basé sur js et la base de données PostgreSQL. Dans le chapitre précédent, nous avons appris que nous devons définir un objet Kubernetes Deployment pour chaque service d’application que nous voulons déployer. Faisons-le d’abord pour le composant Web. Comme toujours dans cet article, nous choisirons la manière déclarative de définir nos objets. Voici le YAML définissant un objet de déploiement pour le composant Web :
Définition du déploiement de Kubernetes pour le composant Web
La définition de déploiement précédente se trouve dans le fichier web-deployment.yaml du dossier labs ch11 . Les lignes de code sont les suivantes :
- Sur la ligne 4 : nous définissons le nom de notre objet Déploiement comme web
- À la ligne 6 : Nous déclarons que nous voulons avoir une instance du composant Web en cours d’exécution
- De la ligne 8 à 10 : Nous définissons les gousses qui feront partie de notre déploiement, à savoir ceux qui ont l’étiquette application et le service avec les valeurs, les animaux et web respectivement
- Sur la ligne 11 : Dans le modèle pour les dosettes à partir de la ligne 11, on définit que chaque module aura les deux étiquettes application et un service appliqué
- À partir de la ligne 17 : nous définissons le conteneur unique qui sera exécuté dans le pod. L’image du conteneur est notre application bien connue avec une image deockerandkubernetes / ch08-web : 1.0 et le nom du conteneur sera web
- Ports : Enfin, nous déclarons que le conteneur expose le port 3000 pour le trafic de type TCP
Assurez-vous que vous avez défini le contexte de kubectl sur Minikube. Voir le chapitre 2, Configuration d’un environnement de travail, pour plus de détails sur la façon de procéder.
Nous pouvons déployer cet objet Déploiement à l’aide de kubectl :
$ kubectl create -f web-deployment.yaml
Nous pouvons vérifier à nouveau que le déploiement a été créé à nouveau à l’aide de notre CLI Kubernetes, et nous devrions voir la sortie suivante :
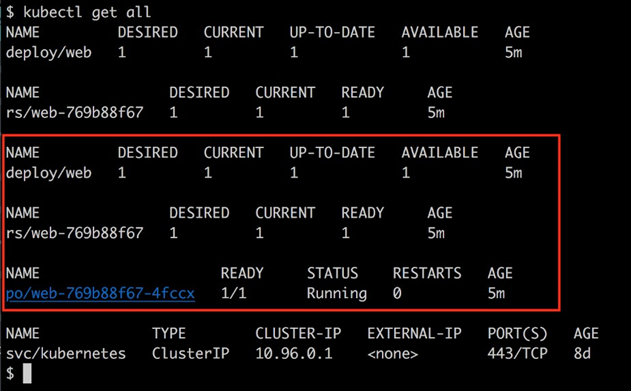
Liste de toutes les ressources en cours d’exécution dans Minikube
Au moment de l’écriture, il semble y avoir un bogue dans Minikube ou kubectl qui affiche certaines ressources deux fois lors de l’utilisation de la commande kubectl get all. Vous pouvez simplement ignorer la sortie en double.
Dans la sortie précédente, nous voyons que Kubernetes a créé trois objets : le déploiement, un ReplicaSet correspondant et un seul pod (rappelez-vous que nous avons spécifié que nous voulons une seule réplique). L’état actuel correspond à l’état souhaité pour les trois objets, donc nous allons bien jusqu’à présent.
Désormais, le service Web doit être exposé au public. Pour cela, nous devons définir un objet Service Kubernetes de type NodePort. Voici la définition, qui se trouve dans le -service.yaml Web fichier dans les laboratoires dossier CH11 :
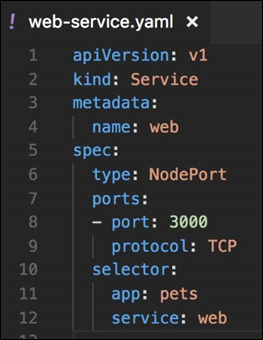
Définition de l’objet Service pour notre composant Web Les lignes de codes précédentes sont les suivantes :
- Sur la ligne 4 : nous définissons le nom de cet objet Service sur Web.
- À la ligne 6 : nous définissons le type d’objet de service que nous utilisons. Étant donné que le composant Web doit être accessible depuis l’extérieur du cluster, il ne peut pas s’agir d’un objet Service de type ClusterIP mais doit être de type NodePort ou LoadBalancer. Nous avons discuté des différents types de services Kubernetes dans le chapitre précédent et n’entrerons donc pas dans les détails à ce sujet. Dans notre exemple, nous utilisons un type de service NodePort.
- Sur les lignes 8 et 9 : nous précisons que nous voulons exposer le port 3000 pour l’accès via le protocole TCP. Kubernetes mappera automatiquement le port de conteneur 3000 à un port d’hôte gratuit compris entre 30 000 et 32 768. Le port que Kubernetes choisit efficacement peut être déterminé à l’aide de la commande kubectl get service ou kubectl describe pour le service après sa création.
- De la ligne 10 à 12 : Nous définissons les critères de filtrage pour les pods pour lesquels ce service sera un endpoint stable. Dans ce cas, ce sont tous les pods qui ont les étiquettes app et service avec respectivement des valeurs pets et web.
Ayant cette spécification pour un objet Service, nous pouvons le créer en utilisant kubectl :
$ kubectl create -f web-service.yaml
Nous pouvons lister tous les services pour voir le résultat de la commande précédente :

The Service object created for the web component
Dans la sortie, nous voyons qu’un service appelé web a été créé. Un clusterIP 10.103.113.40 unique a été attribué à ce service et le port de conteneur 3000 a été publié sur le port 30125 sur tous les nœuds de cluster.
Si nous voulons tester ce déploiement, nous devons d’abord savoir quelle adresse IP possède Minikube, puis utiliser cette adresse IP pour accéder à notre service Web. Voici la commande que nous pouvons utiliser pour ce faire :
$ IP=$(minikube ip)
$ curl -4 $IP:30125/
Pets Demo Application
OK, la réponse est Pets Demo Application, ce à quoi nous nous attendions. Le service Web est opérationnel dans le cluster Kubernetes. Ensuite, nous voulons déployer la base de données.
Déploiement de la base de données
Une base de données est un composant avec état et doit être traitée différemment des composants sans état, comme notre composant Web. Nous avons examiné en détail la différence entre les composants avec état et sans état dans une architecture d’application distribuée au chapitre 6, Architecture d’application distribuée et au chapitre 9, Orchestrateurs.
Kubernetes a défini un type spécial d’objet ReplicaSet pour les composants avec état. L’objet est appelé StatefulSet . Utilisons ce type d’objet pour déployer notre base de données. La définition se trouve dans le fichier labs / ch11 / db-statefulset.yaml . Les détails sont les suivants :
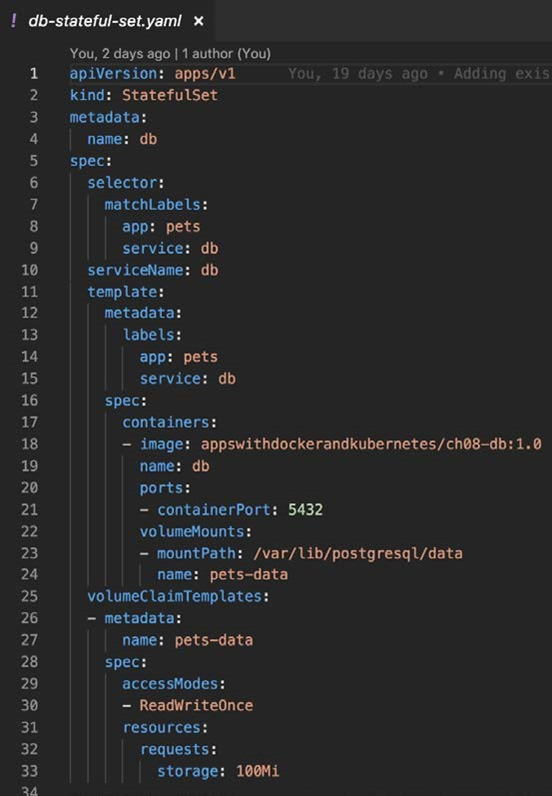
Un StatefulSet pour le composant DB
OK, cela semble un peu effrayant, mais ce n’est pas le cas. Elle est un peu plus longue que la définition du déploiement pour le composant Web car nous devons également définir un volume où la base de données PostgreSQL peut stocker les données. La définition de la revendication de volume se trouve aux lignes 25 à 33. Nous voulons créer un volume avec le nom petsdata et d’une taille maximale égale à 100 Mo. Aux lignes 22 à 24, nous utilisons ce volume et le montons dans le conteneur à / var / lib / postgresql / data où PostgreSQL l’attend. Sur la ligne 21, nous déclarons également que PostgreSQL écoute sur le port 5432.
Comme toujours, nous utilisons kubectl pour déployer le StatefulSet :
$ kubectl create -f db-stateful-set.yaml
Si nous listons maintenant toutes les ressources du cluster, nous pouvons voir les objets supplémentaires créés :
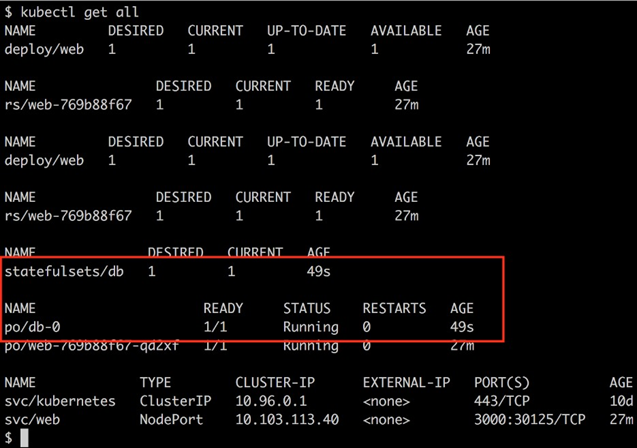
Le StatefulSet et son pod
Nous voyons qu’un StatefulSet et un pod ont été créés. Pour les deux, l’état actuel correspond à l’état souhaité et donc le système est sain. Mais cela ne signifie pas que le composant Web peut accéder à la base de données pour le moment. La découverte de service ne fonctionnerait pas jusqu’à présent. N’oubliez pas que le composant Web souhaite accéder au service db sous le nom db.
Pour que la découverte de service fonctionne à l’intérieur du cluster, nous devons également définir un objet Service Kubernetes pour le composant de base de données. Étant donné que la base de données ne doit être accessible qu’à partir du cluster, le type d’objet Service dont nous avons besoin est ClusterIP. Voici la spécification, qui se trouve dans le fichier labs / ch11 / dbservice.yaml :
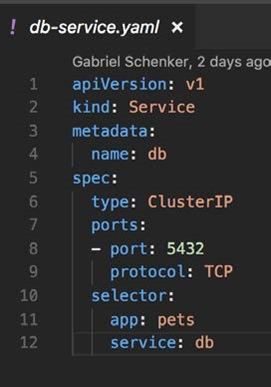
Définition de l’objet Service Kubernetes pour la base de données
Le composant de base de données sera représenté par cet objet Service et il sera accessible par le nom db, qui est le nom du service, tel que défini à la ligne 4. Le composant de base de données ne doit pas être accessible au public, nous avons donc décidé d’utiliser un objet Service de type ClusterIP. Le sélecteur des lignes 10 à 12 définit que ce service représente un point de terminaison stable pour tous les pods qui ont les étiquettes correspondantes définies, c’est-à-dire app: pets et service: db.
Déployons ce service avec la commande suivante :
$ kubectl create -f db-service.yaml
Et nous devrions maintenant être prêts à tester l’application. Nous pouvons utiliser le navigateur cette fois pour profiter des images drôles de chats :

Test de l’application pour animaux de compagnie en cours d’exécution dans Kubernetes
192.168.99.100 est l’adresse IP de mon Minikube. Vérifiez votre adresse à l’aide de la commande minikube ip . Le numéro de port 30125 est le numéro que Kubernetes a automatiquement sélectionné pour mon objet Service Web. Remplacez ce numéro par le port que Kubernetes a attribué à votre service. Obtenez le numéro en utilisant la commande kubectl get services.
Nous avons maintenant déployé avec succès l’application Pets sur Minikube, qui est un cluster Kubernetes à nœud unique. Pour ce faire, nous avons dû définir quatre artefacts :
- Un objet Déploiement et Service pour le composant Web
- Un StatefulSet et un objet Service pour le composant de base de données
Pour supprimer l’application du cluster, nous pouvons utiliser le petit script suivant :
kubectl delete svc/web kubectl delete deploy/web kubectl delete svc/db kubectl delete statefulset/db
Rationalisation du déploiement
Jusqu’à présent, nous avons créé quatre artefacts qui devaient être déployés sur le cluster. Et ce n’est qu’une application très simple, composée de deux composants. Imaginez avoir une application beaucoup plus complexe. Cela deviendrait rapidement un cauchemar de maintenance.
Heureusement, nous avons plusieurs options pour simplifier le déploiement. La méthode dont nous allons discuter ici est la possibilité de définir tous les composants qui composent une application dans Kubernetes dans un seul fichier.
D’autres solutions qui sortent du cadre de cet article comprennent l’utilisation d’un gestionnaire de packages, tel que Helm .
Si nous avons une application composée de nombreux objets Kubernetes tels que les objets Déploiement et Service, nous pouvons les conserver tous dans un seul fichier et séparer les définitions d’objet individuelles par trois tirets. Par exemple, si nous voulions avoir le déploiement et la définition de service pour le composant Web dans un seul fichier, cela ressemblerait à ceci :
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: web
spec:
replicas: 1
selector:
matchLabels:
app: pets
service: web
template:
metadata:
labels:
app: pets
service: web
spec:
containers:
– image: appswithdockerandkubernetes/ch08-web:1.0
name: web
ports:
– containerPort: 3000
protocol: TCP
—
— apiVersion: v1
kind: Service
metadata:
name: web
spec:
type: NodePort
ports:
– port: 3000
protocol: TCP
selector:
app: pets
service: web
Nous avons collecté les quatre définitions d’objet pour l’application pets dans le fichier labs/ch11/pets.yaml, et nous pouvons déployer l’application en une seule fois :
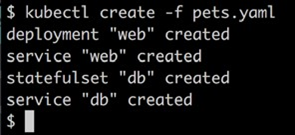
Utilisation d’un seul script pour déployer l’application Pets
De même, nous avons créé un script, labs/ch11/remove-pets.sh, pour supprimer tous les artefacts de l’application Pets du cluster Kubernetes:
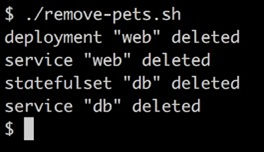
Suppression d’animaux domestiques du cluster Kubernetes
Nous avons pris notre application pour animaux de compagnie que nous avons présentée au chapitre 8, Docker Compose, et défini tous les objets Kubernetes qui sont nécessaires pour déployer cette application dans un cluster Kubernetes. À chaque étape, nous nous sommes assurés d’obtenir le résultat attendu et, une fois que tous les artefacts existaient dans le cluster, nous avons montré l’application en cours d’exécution.
Déploiements sans interruption de service
Dans un environnement critique, il est important que l’application soit toujours opérationnelle. De nos jours, nous ne pouvons plus nous permettre de temps d’arrêt. Kubernetes nous donne divers moyens d’y parvenir. Une mise à jour d’une application dans le cluster qui n’entraîne aucun temps d’arrêt est appelée un déploiement sans temps d’arrêt. Dans ce chapitre, nous présenterons deux façons d’y parvenir. Ce sont les suivants :
- Mises à jour continues
- Déploiements bleu-vert
Commençons par discuter des mises à jour continues.
Mises à jour continues
Dans le chapitre précédent, nous avons appris que l’objet Kubernetes Deployment se distingue de l’ objet ReplicaSet en ce qu’il ajoute des mises à jour et des annulations continues en plus des fonctionnalités de ce dernier. Utilisons notre composant Web pour le démontrer. Évidemment, nous devrons modifier le manifeste ou la description du déploiement du composant Web.
Nous utiliserons la même définition de déploiement que dans la section précédente, avec une différence importante : nous aurons cinq répliques du composant Web en cours d’exécution. La définition suivante peut également être trouvée dans les labs/ch11/web-deploy-rolling-v1. Fichier yaml :
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: web
spec:
replicas: 5
selector:
matchLabels:
app: pets
service: web
template:
metadata:
labels:
app: pets
service: web
spec:
containers:
– image: appswithdockerandkubernetes/ch08-web:1.0
name: web
ports:
– containerPort: 3000
protocol: TCP
Nous pouvons maintenant créer ce déploiement comme d’habitude et aussi, en même temps, le service qui rend notre composant accessible :
$ kubectl create -f web-deploy-rolling-v1.yaml
$ kubectl create -f web-service.yaml
Une fois que nous avons déployé les pods et le service, nous pouvons tester notre composant Web avec la commande suivante :
$ PORT=$(kubectl get svc/web -o yaml | grep nodePort | cut -d’ ‘ -f5)
$ IP=$(minikube ip)
$ curl -4 ${IP}:${PORT}/
Pets Demo Application
Comme nous pouvons le voir, l’application est opérationnelle et nous renvoie le message attendu, Pets Demo Application.
Les développeurs ont maintenant créé une nouvelle version, 2.0, du composant Web. Le code de la nouvelle version du composant Web se trouve dans le dossier labs/ch11/web/src, et la seule modification se trouve à la ligne 12 du fichier server.js :
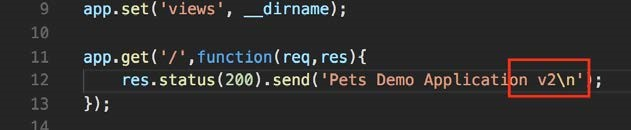
Changement de code pour la version 2.0 du composant Web
Les développeurs ont construit la nouvelle image comme suit :
$ docker image build -t appswithdockerandkubernetes/ch11-web:2.0 web
Et, par la suite, ils ont poussé l’image vers Docker Hub :
$ docker image push appswithdockerandkubernetes/ch11-web:2.0
Nous voulons maintenant mettre à jour l’image utilisée par nos pods qui font partie de l’objet de déploiement Web. Nous pouvons le faire en utilisant la commande set image de kubectl :
$ kubectl set image deployment/web \ web=appswithdockerandkubernetes/ch11-web:2.0
Si nous testons à nouveau l’application, nous obtenons la confirmation que la mise à jour a bien eu lieu :
curl -4 ${IP}:${PORT}/ Pets Demo Application v2
Maintenant, comment savons-nous qu’il n’y a pas eu de temps d’arrêt pendant cette mise à jour ? La mise à jour s’est-elle vraiment déroulée de manière continue ? Que signifie la mise à jour continue ? Cherchons. Tout d’abord, nous pouvons obtenir une confirmation de Kubernetes que le déploiement a effectivement eu lieu et a réussi en utilisant la commande d’état de déploiement :
$ kubectl rollout status deploy/web deployment “web” successfully rolled out
Si nous décrivons le site Web de déploiement avec kubectl décrivent deploy/web, nous obtenons la liste d’événements suivante à la fin de la sortie:
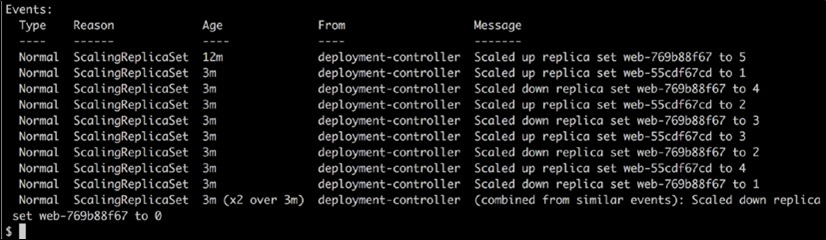
Liste des événements trouvés dans la sortie de la description de déploiement du composant Web
Le premier événement nous indique que lorsque nous avons créé le déploiement, un ReplicaSet web769b88f67 avec cinq répliques a été créé. Ensuite, nous avons exécuté la commande de mise à jour et le deuxième événement de la liste nous indique que cela signifiait la création d’un nouveau ReplicaSet appelé web-55cdf67cd avec, initialement, une seule réplique. Ainsi, à ce moment particulier, il existait six pods sur le système, les cinq pods initiaux et un pod avec la nouvelle version. Mais comme l’état souhaité de l’objet Déploiement indique que nous voulons seulement cinq réplicas, Kubernetes réduit maintenant l’ancien ReplicaSet à quatre instances, ce que nous voyons dans le troisième événement. Ensuite, à nouveau, le nouveau ReplicaSet est mis à l’échelle jusqu’à deux instances et, par la suite, l’ancien ReplicaSet a été réduit à trois instances, et ainsi de suite, jusqu’à ce que nous ayons cinq nouvelles instances et que toutes les anciennes instances aient été mises hors service. Bien que nous ne puissions voir aucune heure précise (autre que trois minutes) à laquelle cela s’est produit, l’ordre des événements nous indique que toute la mise à jour s’est déroulée de manière continue.
Pendant une courte période, certains des appels au service Web auraient reçu une réponse de l’ancienne version du composant et certains appels auraient reçu une réponse de la nouvelle version du composant. Mais à aucun moment le service n’aurait été en panne.
Nous pouvons également répertorier les objets Recordset dans le cluster et obtiendrons la confirmation de ce que j’ai dit dans la section précédente :
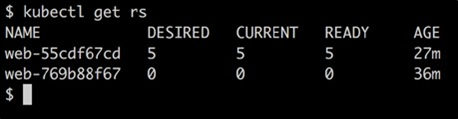
Liste tous les objets Recordset du cluster
Nous voyons que le nouveau jeu d’enregistrements a cinq instances en cours d’exécution et l’ancien a été réduit à zéro instances. La raison pour laquelle l’ancien objet Recordset persiste toujours est que Kubernetes nous offre la possibilité d’annuler la mise à jour et, dans ce cas, de réutiliser le Recordset.
Pour annuler la mise à jour de l’image au cas où un bogue non détecté se faufiler dans le nouveau code, nous pouvons utiliser la commande rollout undo :
$ kubectl rollout undo deploy/web
deployment “web”
$ curl -4 ${IP}:${PORT}/
Pets Demo Application
J’ai également répertorié la commande de test utilisant curl dans l’extrait de code précédent pour vérifier que la restauration s’est bien produite. Si nous répertorions les jeux d’enregistrements, nous voyons la sortie suivante :
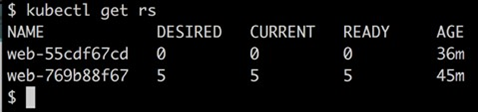
Liste des objets RecordSet après la restauration
Cela confirme que l’ancien objet RecordSet (web-769b88f67) a été réutilisé et que le nouvel a été réduit à zéro instance.
Parfois, même si nous ne pouvons pas, ou ne voulons pas, tolérer l’état mixte d’une ancienne version coexistant avec une nouvelle version. Nous voulons une stratégie tout ou rien. C’est là que les déploiements bleu-vert entrent en jeu, dont nous discuterons ensuite.
Déploiement bleu-vert
Si nous voulons faire un déploiement de style bleu-vert pour notre composant Web de l’application Pets, nous pouvons le faire en utilisant des étiquettes de manière créative. Rappelons-nous d’abord comment fonctionnent les déploiements bleu-vert. Voici une instruction étape par étape approximative :
1. Déployez une première version du site Web des composants en bleu. Nous allons étiqueter les dosettes avec une couleur d’étiquette : bleu pour le faire.
2. déployer le service Kubernetes pour ces gousses avec l’étiquette, la couleur : bleu dans la section de sélection.
3. Nous pouvons maintenant déployer la version 2 du composant Web, mais cette fois les pods ont une étiquette, couleur : vert.
4. Nous pouvons tester la version verte du service qui fonctionne comme prévu.
5. Maintenant, nous inversons le trafic du bleu au vert en mettant à jour le service Kubernetes pour le composant Web. Nous modifions le sélecteur pour utiliser la couleur de l’étiquette : vert.
Définissons un objet Deployment pour la version 1, bleu :
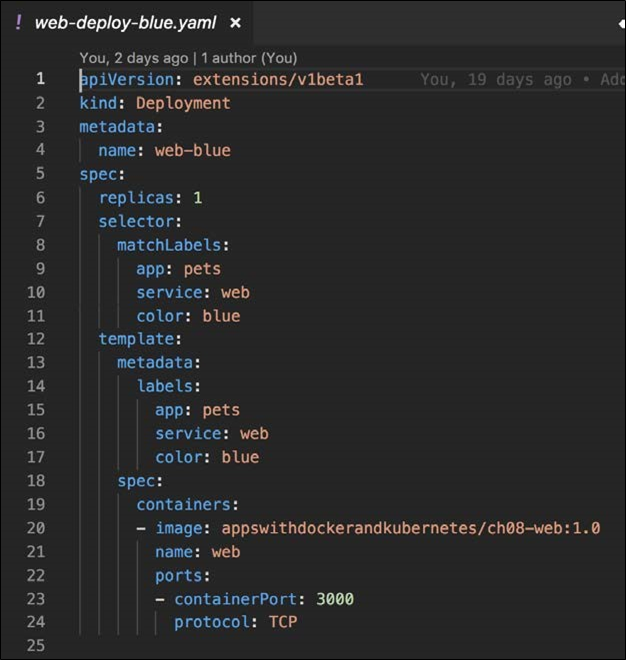
Spécification du bleu de déploiement pour le composant Web
La définition précédente se trouve dans le fichier labs / ch11 / web-deploy-blue.yaml . Veuillez noter la ligne 4 où nous définissons le nom du déploiement comme web-blue pour le distinguer du prochain déploiement web-green. Notez également que nous avons ajouté la couleur de l’étiquette : bleu sur les lignes 11 et 17. Tout le reste reste le même qu’avant.
Nous définissons maintenant l’objet Service pour le composant Web. Ce sera le même que nous avons utilisé auparavant avec un changement mineur, comme vous le verrez dans la capture d’écran suivante :
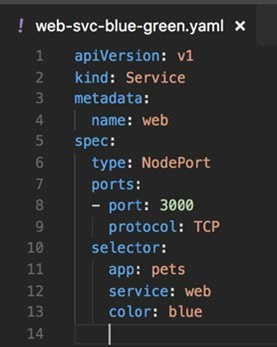
Service Kubernetes pour le composant Web prenant en charge les déploiements bleu-vert
La seule différence avec la définition du service que nous avons utilisée plus tôt dans ce chapitre est la ligne 13, qui ajoute la couleur de l’étiquette : bleu au sélecteur. Nous pouvons trouver la définition précédente dans le fichier labs/ch11/web-svc-blue-green.yaml .
Nous pouvons ensuite déployer la version bleue du composant Web avec la commande suivante:
$ kubectl create -f web-deploy-blue.yaml
$ kubectl create -f web-svc-blue-green.yaml
Une fois le service opérationnel, nous pouvons déterminer son adresse IP et son numéro de port et le tester :
$ PORT=$(kubectl get svc/web -o yaml | grep nodePort | cut -d’ ‘ -f5)
$ IP=$(minikube ip)
$ curl -4 ${IP}:${PORT}/
Pets Demo Application
Comme prévu, nous recevons la réponse Demo Pets Demo.
Nous pouvons maintenant déployer la version verte du composant Web. La définition de son objet Deployment se trouve dans le fichier labs / ch11 / web-deploy-green.yaml et se présente comme suit:

Spécification du vert de déploiement pour le composant web Les lignes intéressantes sont les suivantes :
- Ligne 4 : avec le nom web-green pour faire la distinction avec web-blue et permettre une installation parallèle
- Lignes 11 et 17 : ayant la couleur verte
- Ligne 20 : utilise maintenant la version 2.0 de l’image
Nous sommes maintenant prêts à déployer cette version verte du service, et elle devrait s’exécuter séparément du service bleu :
$ kubectl create -f web-deploy-green.yaml
Nous pouvons nous assurer que les deux déploiements coexistent :

Affichage de la liste des objets de déploiement en cours d’exécution dans le cluster
Comme prévu, nous avons à la fois du bleu et du vert. Nous pouvons vérifier que le bleu est toujours le service actif :
$ curl -4 ${IP}:${PORT}/
Pets Demo Application
Vient maintenant la partie intéressante. Nous pouvons inverser le trafic du bleu au vert en modifiant le service existant pour le composant Web. Exécutez donc la commande suivante :
$ kubectl edit svc/web
Modifiez la valeur de la couleur de l’étiquette du bleu au vert. Enregistrez puis quittez l’éditeur. La CLI Kubernetes mettra automatiquement à jour le service. Lorsque nous interrogeons à nouveau le service Web, nous obtenons ceci :
$ curl -4 ${IP}:${PORT}/
Pets Demo Application v2
Cela confirme que le trafic est en effet passé à la version verte du composant web (notez la v2 à la fin de la réponse à la commande curl).
Si nous nous rendons compte que quelque chose s’est mal passé avec notre déploiement vert et que la nouvelle version a un défaut, nous pouvons facilement revenir à la version bleue en modifiant à nouveau le site Web du service et en remplaçant la valeur de la couleur de l’étiquette du vert au bleu. Cette restauration est instantanée et devrait toujours fonctionner. Nous pouvons ensuite supprimer le déploiement buggy green et corriger le composant. Une fois le problème corrigé, nous pouvons déployer à nouveau la version verte.
Une fois que la version verte du composant fonctionne comme prévu et fonctionne bien, nous pouvons mettre la version bleue hors service :
$ kubectl delete deploy/web-blue
Lorsque nous sommes prêts à déployer une nouvelle version, 3.0, celle-ci devient la version bleue.
Nous mettons à jour le fichier labs/ch11/web-deploy-blue.yaml en conséquence et le déployons. Ensuite, nous basculons le site Web du service du vert au bleu, etc.
Nous avons démontré avec succès, avec notre composant Web de l’application pour animaux de compagnie, comment le déploiement bleu-vert peut être réalisé dans un cluster Kubernetes.
Les secrets de Kubernetes
Parfois, les services que nous voulons exécuter dans le cluster Kubernetes doivent utiliser des données confidentielles telles que des mots de passe, des clés d’API secrètes ou des certificats, pour n’en nommer que quelques-uns. Nous voulons nous assurer que ces informations sensibles ne peuvent être vues que par le service autorisé ou dédié. Tous les autres services exécutés dans le cluster ne doivent pas avoir accès à ces données.
Pour cette raison, les secrets de Kubernetes ont été introduits. Un secret est une paire clé-valeur où la clé est le nom unique du secret et la valeur est les données sensibles réelles. Les secrets sont stockés dans etcd. Kubernetes peut être configuré de telle sorte que les secrets soient chiffrés au repos, c’est-à-dire dans etcd, et en transit, c’est-à-dire lorsque les secrets passent par le fil d’un nœud maître aux nœuds de travail sur lesquels les pods du service utilisant ce secret sont en cours d’exécution.
Définition manuelle des secrets
Nous pouvons créer un secret de manière déclarative de la même manière que nous avons créé tout autre objet dans Kubernetes. Voici le YAML pour un tel secret :
apiVersion: v1 kind: Secret metadata: name: pets-secret type: Opaque data: username: am9obi5kb2UK password: c0VjcmV0LXBhc1N3MHJECg==
La définition précédente se trouve dans le fichier labs/ch11/pets-secret.yaml. Maintenant, vous vous demandez peut-être quelles sont les valeurs. S’agit-il des vraies valeurs (non chiffrées) ? Non ils ne sont pas. Et ce ne sont pas non plus des valeurs vraiment chiffrées mais juste des valeurs encodées en base64. Ainsi, ils ne sont pas vraiment sécurisés, car les valeurs codées en base64 peuvent facilement être converties en valeurs de texte clair. Comment ai-je obtenu ces valeurs ? C’est facile :
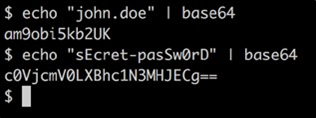
Création de valeurs codées en base64 pour le secret
Nous pouvons alors créer le secret et le décrire :

Créer et décrire le secret de Kubernetes
Dans la description du secret, les valeurs sont cachées et seule leur longueur est donnée. Alors peut-être que les secrets sont en sécurité maintenant ? Non, pas vraiment. Nous pouvons facilement décoder ce secret en utilisant la commande kubectl get :

Le secret de Kubernetes décodé
Comme nous pouvons le voir dans la capture d’écran précédente, nous avons retrouvé nos valeurs secrètes d’origine. Et nous pouvons les décoder :
$ echo “c0VjcmV0LXBhc1N3MHJECg==” | base64 –decode sEcret-pasSw0rD
Ainsi, les conséquences sont que cette méthode de création d’un Kubernetes ne doit pas être utilisée dans un autre environnement que le développement, où nous traitons des données non sensibles. Dans tous les autres environnements, nous avons besoin d’une meilleure façon de traiter les secrets.
Créer des secrets avec kubectl
Une manière beaucoup plus sûre de définir des secrets consiste à utiliser kubectl. Tout d’abord, nous créons des fichiers contenant les valeurs secrètes codées en base64 similaires à ce que nous avons fait dans la section précédente, mais cette fois nous stockons les valeurs dans des fichiers temporaires :
$ echo “sue-hunter” | base64 > username.txt
$ echo “123abc456def” | base64 > password.txt
Maintenant, nous pouvons utiliser kubectl pour créer un secret à partir de ces fichiers comme suit :
$ kubectl create secret generic pets-secret-prod \
–from-file=./username.txt \
–from-file=./password.txt secret “pets-secret-prod” created
Le secret peut alors être utilisé de la même manière que le secret créé manuellement.
Pourquoi cette méthode est-elle plus sécurisée que l’autre que vous pourriez demander ? Eh bien, tout d’abord, il n’y a pas de YAML qui définit un secret et est stocké dans un système de contrôle de version de code source, tel que GitHub, auquel de nombreuses personnes ont accès et peuvent donc voir et décoder les secrets. Seul l’administrateur qui est autorisé à connaître les secrets voit leurs valeurs et les utilise pour créer directement les secrets dans le cluster (de production). Le cluster lui-même est protégé par un contrôle d’accès basé sur les rôles afin qu’aucune personne non autorisée n’y ait accès et ne puisse décoder les secrets définis dans le cluster.
Mais maintenant, voyons comment nous pouvons réellement utiliser les secrets que nous avons définis.
Utilisation de secrets dans un pod
Disons que nous voulons créer un objet de déploiement où le composant Web utilise notre secret appelé pets-secret que nous avons présenté dans la section précédente. Nous utilisons la commande suivante pour créer le secret dans le cluster :
$ kubectl create -f pets-secret.yaml
Dans le fichier labs / ch11 / web-deploy-secret.yaml , nous pouvons trouver la définition de l’objet Deployment . Nous avons dû ajouter la partie à partir de la ligne 23 à la définition d’origine de l’objet Déploiement :

Objet de déploiement pour composant Web avec un secret
Aux lignes 27 à 30, nous définissons un volume appelé secrets de notre secret animal de compagnie . Nous utilisons ensuite ce volume dans le conteneur, comme décrit aux lignes 23 à 26. Nous montons les secrets dans le système de fichiers du conteneur à / etc / secrets et nous montons le volume en mode lecture seule. Ainsi, les valeurs secrètes seront disponibles pour le conteneur sous forme de fichiers dans ledit dossier. Les noms des fichiers correspondront aux noms des clés et le contenu des fichiers correspondra aux valeurs des clés correspondantes. Les valeurs seront fournies sous forme non chiffrée à l’application exécutée à l’intérieur du conteneur.
Dans notre cas, ayant le nom d’utilisateur et le mot de passe des clés dans le secret, nous trouverons deux fichiers, nommés nom d’utilisateur et mot de passe, dans le dossier / etc / secrets du système de fichiers du conteneur. Le nom d’utilisateur du fichier doit contenir la valeur john.doe et le mot de passe du fichier la valeur sEcret-pasSw0rD. Voici la confirmation :
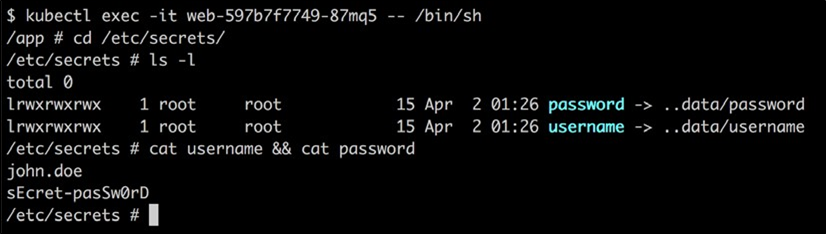
Confirmer que les secrets sont disponibles à l’intérieur du conteneur
Sur la ligne 1 de la sortie précédente, nous exécutons dans le conteneur où le composant Web s’exécute. Ensuite, aux lignes 2 à 5, nous listons les fichiers dans le dossier /etc/secrets, et enfin, aux lignes 6 à 8, nous montrons le contenu des deux fichiers qui, sans surprise, affichent les valeurs secrètes en texte clair.
Étant donné que toute application écrite dans n’importe quelle langue peut lire des fichiers simples, ce mécanisme d’utilisation des secrets est très rétro compatible. Même une ancienne application COBOL peut lire des fichiers texte en clair à partir du système de fichiers.
Parfois, cependant, les applications s’attendent à ce que les secrets soient disponibles dans les variables d’environnement. Voyons ce que Kubernetes nous propose dans ce cas.
Valeurs secrètes dans les variables d’environnement
Supposons que notre composant Web attend le nom d’utilisateur dans la variable d’environnement, PETS_USERNAME et le mot de passe dans PETS_PASSWORD, alors nous pouvons modifier notre déploiement YAML pour qu’il se présente comme suit :
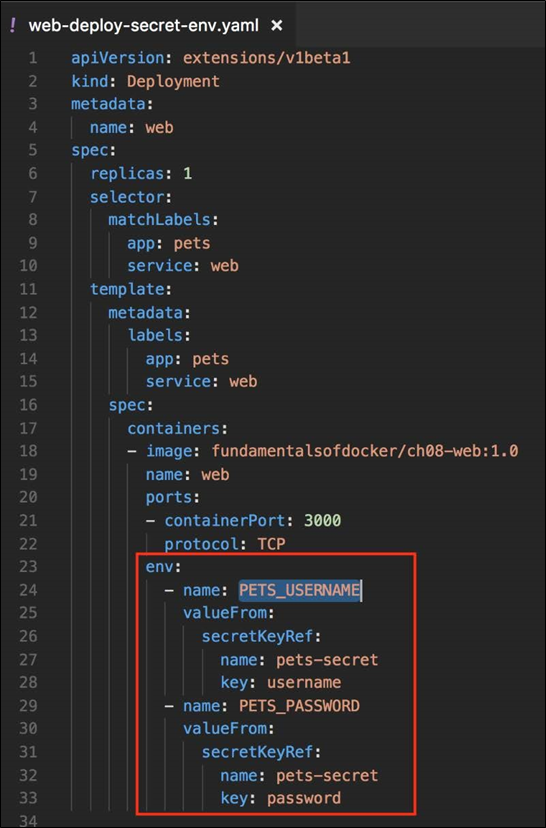
Déploiement mappant des valeurs secrètes sur des variables d’environnement
Aux lignes 23 à 33, nous définissons les deux variables d’environnement, PETS_USERNAME et PETS_PASSWORD, et nous leur mappons la paire clé-valeur correspondante du Pets -Secret.
Remarque, nous n’avons plus besoin d’un volume mais nous mappons directement les clés individuelles de nos animaux de compagnie-secret dans les variables d’environnement correspondantes valides à l’intérieur du conteneur. La séquence de commandes suivante montre que les valeurs secrètes sont en effet disponibles à l’intérieur du conteneur dans les variables d’environnement respectives :

Les valeurs secrètes sont mappées aux variables d’environnement
Dans cette section, nous avons montré comment définir des secrets dans un cluster Kubernetes et comment utiliser ces secrets dans des conteneurs exécutés dans le cadre des pods d’un déploiement. Nous avons montré deux variantes sur la façon dont les secrets peuvent être mappés à l’intérieur d’un conteneur, la première utilisant des fichiers et la seconde utilisant des variables d’environnement.
Résumé
Dans ce chapitre, nous avons appris comment déployer une application dans un cluster Kubernetes et comment configurer le routage au niveau de l’application pour cette application. En outre, nous avons appris des moyens de mettre à jour les services d’application s’exécutant dans un cluster Kubernetes sans provoquer de temps d’arrêt. Enfin, nous avons utilisé des secrets pour fournir des informations sensibles aux services d’application exécutés dans le cluster.
Dans le chapitre suivant et final, nous allons apprendre à déployer, exécuter, surveiller et déboguer un exemple d’application conteneurisée dans le cloud à l’aide de l’offre Azure Kubernetes Service (AKS) de Microsoft. Restez à l’écoute.
Questions
Pour évaluer vos progrès d’apprentissage, veuillez répondre aux questions suivantes :
1. Vous disposez d’une application composée de deux services, le premier étant une API Web et le second une base de données, tel que Mongo. Vous souhaitez déployer cette application dans un cluster Kubernetes. En quelques courtes phrases, expliquez comment vous procédez.
2. Décrivez dans vos propres mots en quelques phrases les composants dont vous avez besoin pour établir un routage de couche 7 (ou de niveau application) pour votre application.
3. Énumérez les principales étapes nécessaires pour implémenter le déploiement bleu-vert pour un service d’application simple. Évitez d’entrer dans trop de détails.
4. Nommez trois ou quatre types d’informations que vous fourniriez à un service d’application via les secrets Kubernetes.
5. Nommez les sources que Kubernetes accepte lors de la création d’un secret.
Exécution d’une application conteneurisée dans le cloud
Dans le chapitre précédent, nous avons appris à déployer une application multiservice dans un cluster Kubernetes. Nous avons configuré le routage au niveau de l’application pour cette application et mis à jour ses services à l’aide d’une stratégie sans interruption de service. Enfin, nous avons fourni des données confidentielles aux services en cours d’exécution en utilisant les secrets de Kubernetes.
Dans ce chapitre, nous montrerons comment déployer une application conteneurisée complexe dans un cluster Kubernetes hébergé sur Microsoft Azure. Là, nous utiliserons l’offre dite Azure Kubernetes Service (AKS). AKS gère entièrement le cluster Kubernetes pour nous afin que nous puissions nous concentrer sur le déploiement, l’exécution et, si nécessaire, la mise à niveau de notre application.
Voici les sujets dont nous discuterons dans ce chapitre :
- Création d’un cluster Kubernetes entièrement géré dans Azure
- Pousser des images Docker vers le registre de conteneurs Azure
- Déploiement de l’application dans le cluster Kubernetes
- Mise à l’échelle de l’application Animaux
- Surveillance du cluster et de l’application
- Mise à niveau de l’application avec aucun temps d’arrêt
- Mise à niveau de Kubernetes
- Débogage d’une application en cours d’exécution dans AKS
- Nettoyage
Après avoir lu ce chapitre, vous pourrez :
- Provisionner un cluster Kubernetes entièrement géré dans AKS
- Déployer une application basée sur plusieurs conteneurs dans votre cluster
- Surveillez l’intégrité de votre cluster Kubernetes et de l’application qui s’exécute dessus
- Exécutez une mise à jour continue de votre application dans AKS
- Débogage interactif d’une application Node.js exécutée sur un cluster Kubernetes dans AKS
Exigences techniques
Nous allons utiliser l’AKS hébergé sur Microsoft Azure. Ainsi, il est nécessaire d’avoir un compte sur Azure. Si vous n’avez pas de compte existant, vous pouvez demander un compte d’essai gratuit à https://azure.microsoft.com/services/kubernetes-service/.
Pour accéder à Azure, nous utiliserons également la CLI Azure. Ainsi, assurez-vous d’en avoir la dernière version disponible sur votre ordinateur. Puisqu’il s’agit d’un article sur les conteneurs, nous n’installerons pas nativement la CLI mais en utiliserons une version conteneurisée.
Nous utilisons également les dossiers ch12 et ch12-dev-espaces de notre référentiel de laboratoires.
Création d’un cluster Kubernetes entièrement géré dans Azure
Jusqu’à présent, nous avons utilisé un cluster Kubernetes node-1 local pour déployer nos applications. Ceci est bien adapté pour le développement, les tests et le débogage sur une application conteneurisée destinée à s’exécuter sur Kubernetes. Finalement, cependant, nous voudrons déployer l’application terminée dans un environnement de production. Il existe différentes manières d’y parvenir. Nous pourrions, par exemple, auto-héberger un cluster Kubernetes hautement disponible et évolutif, mais ce n’est pas une mince affaire. Dans ce chapitre, nous allons déléguer le travail acharné de provisionnement et d’hébergement d’un cluster Kubernetes hautement disponible et massivement évolutif à Microsoft et utiliserons leur AKS exécuté sur Azure.
Nous déploierons ensuite notre application Pets sur ce cluster. Une fois déployé, nous voudrons surveiller le comportement du cluster et de notre application sur celui-ci. Plus tard, nous mettrons à l’échelle le composant WebPart de l’application, puis mettrons à jour le composant WebPart et déclencherons une mise à jour continue qui ne devrait entraîner aucun temps d’arrêt.
Enfin, nous montrerons comment on peut utiliser les espaces de développement dans AKS pour déboguer à distance une application, telle que notre interface Node.js, alors qu’elle s’exécute dans le cloud.
AKS peut être utilisé et exploité de trois manières différentes. Tout d’abord, nous pouvons utiliser une interface graphique Web fournie par le portail Azure. Les deux suivants sont bien adaptés à l’automatisation :
- Nous pouvons utiliser la CLI Azure pour provisionner et gérer le cluster Kubernetes combiné avec kubectl pour déployer, mettre à l’échelle ou mettre à jour l’application dans le cluster, et plus encore
- Nous pouvons utiliser des outils tels que les modèles de ressources Terraform et Azure pour faire de même
Dans ce chapitre, nous nous concentrerons sur Azure CLI et kubectl .
Exécution de la CLI Azure
Comme mentionné précédemment, nous aurons besoin de l’Azure CLI pour accéder à Microsoft Azure. Il est important d’utiliser une nouvelle ou la plus récente version de la CLI pour pouvoir accéder à toutes les ressources liées à AKS. Cette fois, nous n’exécuterons pas l’interface CLI sur notre ordinateur, mais nous en utiliserons plutôt une version conteneurisée. Microsoft a créé un conteneur avec la CLI installée dessus. Dans notre cas, nous voulons également utiliser le Docker (docker) et la CLI Kubernetes (kubectl) à partir du conteneur, mais ces outils ne sont pas installés par défaut. Ainsi, j’ai créé un Dockerfile qui peut être utilisé pour créer de nouvelles images Docker basées sur celle de Microsofts sur laquelle les outils seront installés. Suis les étapes :
1. Ouvrez une nouvelle fenêtre Terminal et accédez au sous-dossier ch12 de votre dossier labs : cd ~ / labs / ch12
2. Exécutez la commande suivante pour créer notre conteneur Azure CLI personnalisé :
docker image build -t custom-azure-cli:v1 azure-cli
3. Une fois cette image créée, nous pouvons exécuter la commande suivante pour exécuter de manière interactive un conteneur avec la dernière version d’Azure, Docker et Kubernetes CLI :
docker container run –rm -it \
-v /var/run/docker.sock:/var/run/docker.sock \
-v $(pwd):/src \ custom-azure-cli:v1
Veuillez noter comment nous montons le socket Docker dans le conteneur afin que nous puissions exécuter n’importe quelle commande Docker à partir du conteneur. Nous montons également le dossier actuel dans le dossier / src à l’intérieur du conteneur pour avoir accès au code source de ce chapitre.
Une fois l’instance de conteneur démarrée, l’invite suivante s’affiche : bash-4.4 #
Nous pouvons tester le conteneur à l’aide des commandes suivantes :
bash-4.4# docker version
Client:
Version: 18.06.0-ce
API version: 1.38
Go version: go1.10.3
Git commit: 0ffa825
Built: Wed Jul 18 19:04:39 2018
OS/Arch: linux/amd64
Experimental: false Server:
Engine:
Version: 18.06.0-ce
API version: 1.38 (minimum version 1.12)
Go version: go1.10.3
Git commit: 0ffa825
Built: Wed Jul 18 19:13:46 2018
OS/Arch: linux/amd64
Experimental: true
Le résultat de l’exécution de la commande kubectl est le suivant :
bash-4.4# kubectl version
Client Version: version.Info{Major:”1”, Minor:”11”,
GitVersion:”v1.11.2”, GitCommit:”bb9ffb1654d4a729bb4cec18ff088eac c153c239”, GitTreeState:”clean”, BuildDate:”2018-08-07T23:17:28Z”,
GoVersion:”go1.10.3”, Compiler:”gc”, Platform:”linux/amd64”}
Server Version: version.Info{Major:”1”, Minor:”9”,
GitVersion:”v1.9.9”, GitCommit:”57729ea3d9a1b75f3fc7bbbadc597ba707d47c8a”, GitTreeState:”clean”, BuildDate:”2018-06-29T01:07:01Z”,
GoVersion:”go1.9.3”, Compiler:”gc”, Platform:”linux/amd64”}
La sortie nous montre que nous exécutons Docker 18.06.0-ce et Kubernetes v1.11.2 sur le client et v1.9.9 sur le serveur.
Pour pouvoir utiliser la CLI Azure pour travailler avec notre compte sur Microsoft Azure, nous devons d’abord nous connecter au compte. Pour ce faire, entrez les informations suivantes à l’invite de commande bash-4.4 # :
az login
Vous serez invité avec un message similaire à celui-ci:
To sign in, use a web browser to open the page https://microsoft.com/ devicelogin and enter the code CMNB2TSND to authenticate.
Une fois que vous vous êtes authentifié avec succès, vous devriez voir une réponse similaire à la suivante dans la fenêtre Terminal :
[
{
“cloudName”: “AzureCloud”,
“id”: “186760ad-9152-4499-b317-xxxxxxxxxxxx”,
“isDefault”: true,
“name”: “xxxxxxxxx”,
“state”: “Enabled”,
“tenantId”: “f5e90e29-00df-4ea6-b8a4-xxxxxxxxxxxx”,
“user”: {
“name”: “gnschenker@xxxxx.xxx”,
“type”: “user”
}
}
]
Nous sommes maintenant prêts à commencer à travailler avec Azure en général et AKS en particulier.
Groupes de ressources Azure
Dans Azure, un concept important est celui des groupes de ressources. Un groupe de ressources est un conteneur pour toutes sortes de ressources cloud logiquement liées. Dans notre cas, tous les éléments composant le cluster Kubernetes que nous allons mettre à disposition dans AKS appartiennent au même groupe de ressources. Commençons donc par créer un tel groupe. Nous utiliserons la CLI Azure pour ce faire. Nous nommerons le groupe pets-group et il sera situé dans la région westeurope. Utilisez la commande suivante pour créer le groupe de ressources :
az group create –name pets-group –location westeurope
La réponse de cette commande ressemble à ceci :
{
“id”: “/subscriptions/186760ad-9152-4499-b317-xxxxxxxxxxxx/
resourceGroups/pets-group”, “location”: “westeurope”,
“managedBy”: null,
“name”: “pets-group”,
“properties”: {
“provisioningState”: “Succeeded”
},
Une fois que nous avons créé un groupe de services, nous devons créer un principal de service afin que notre cluster AKS puisse interagir avec d’autres ressources Azure. Pour ce faire, utilisez la commande suivante :
az ad sp create-for-rbac \
–name pets-principal \
–password adminadmin \
–skip-assignment
Il en résulte une sortie similaire à celle-ci :
{
“appId”: “a1a2bdbc-ba07-49bd-ae77-fb8b6948869d”,
“displayName”: “azure-cli-2018-08-27-19-26-20”,
“name”: “http://pets-principal”,
“password”: “adminadmin”,
“tenant”: “f5e90e29-00df-4ea6-b8a4-ce8553f10be7”
}
Dans la sortie précédente, appId et mot de passe sont importants, et vous devez les noter quelque part afin de pouvoir y accéder dans les commandes des sections suivantes.
Provisioning du cluster Kubernetes
Enfin, nous sommes prêts à approvisionner notre cluster Kubernetes en AKS. Nous pouvons utiliser la commande suivante pour ce faire :
az aks create \
–resource-group pets-group \
–name pets-cluster \
–node-count 1 \
–generate-ssh-keys \
–service-principal <appId> \
–client-secret <password>
Remarque, vous devez remplacer les espaces réservés <appId> et <password> par les valeurs que vous avez notées après la création du principal de service. Notez également que nous avons pour le moment créé un cluster Kubernetes avec un seul nœud de travail. Plus tard, nous pouvons augmenter (et diminuer) ce cluster à l’aide de la CLI Azure.
La réponse à la commande précédente ressemble à ceci :
SSH key files ‘/root/.ssh/id_rsa’ and ‘/root/.ssh/id_rsa.pub’ have been generated under ~/.ssh to allow SSH access to the VM. If using machines without permanent storage like Azure Cloud Shell without an attached file share, back up your keys to a safe location – Running ..
L’ensemble du provisionnement prend quelques minutes (comme indiqué par le statut – En cours d’exécution .. ).
En attendant la fin de la commande, nous pouvons ouvrir une nouvelle fenêtre de navigateur et accéder au portail Azure à https://portal.azure.com et nous connecter à notre compte. Une fois authentifié avec succès, nous pouvons alors accéder à l’option Groupes de ressources et voir le groupe de ressources pets- group dans la liste des groupes de ressources. Si nous cliquons sur ce groupe, nous devrions voir Pets-cluster répertorié comme une ressource dans le groupe :
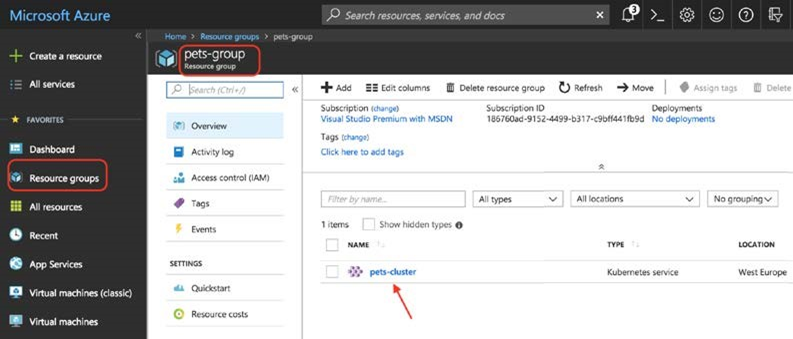
Cluster Kubernetes dans AKS
Une fois le cluster créé, nous voyons la sortie finale dans la fenêtre Terminal comme suit:
{ “aadProfile”: null,
“addonProfiles”: null,
“agentPoolProfiles”: [
{
“count”: 1,
“maxPods”: 110,
“name”: “nodepool1”,
“osDiskSizeGb”: null,
“osType”: “Linux”,
“storageProfile”: “ManagedDisks”,
“vmSize”: “Standard_DS1_v2”,
“vnetSubnetId”: null
}
],
“dnsPrefix”: “pets-clust-pets-group-186760”,
“enableRbac”: true,
“fqdn”: “pets-clust-pets-group-186760-d706beb4.hcp.westeurope. azmk8s.io”, “id”: “/subscriptions/186760ad-9152-4499-b317- c9bff441fb9d/resourcegroups/pets-group/providers/Microsoft.
ContainerService/managedClusters/pets-cluster”,
“kubernetesVersion”: “1.9.9”,
“linuxProfile”: {
“adminUsername”: “azureuser”,
“ssh”: {
“publicKeys”: [
{
“keyData”: “ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDMp
2BFCRUo7v1ktVQa57ep7zLg7HEjsRQAkb7UnovDXrLg1nBuzMslHZY3mJ5ulxU00
YWeUuxObeHjRh+ZJHc4+xKaDV8M6GmuHjD8HJnw5tsCbV8w/A+5oUOECaeJn5sQMCkmS
DovmDQZchAjLjVHQLSTiEqjLYmjjqYmhqYpO2vRsnZXpelRrlmfNWoSV5J3L7/ hayI2fg35X/H4xnx1sm403O9pwyEKYYBFfNzCXigNnqyBvxOqwURZUW/caIpTqAhS6
K+D1xPa2w7y1A5qcZS++SnJOHCHyRKZ3UQ4BVZTSejBhxYTr5/dgJE+LEvLk2i
YUo4kUmbxDSVssnWJ”
}
]
}
},
“location”: “westeurope”,
“name”: “pets-cluster”,
“networkProfile”: {
“dnsServiceIp”: “10.0.0.10”,
“dockerBridgeCidr”: “172.17.0.1/16”,
“networkPlugin”: “kubenet”,
“networkPolicy”: null,
“podCidr”: “10.244.0.0/16”,
“serviceCidr”: “10.0.0.0/16”
},
“nodeResourceGroup”: “MC_pets-group_pets-cluster_westeurope”,
“provisioningState”: “Succeeded”,
“resourceGroup”: “pets-group”,
“servicePrincipalProfile”: {
“clientId”: “a1a2bdbc-ba07-49bd-ae77-fb8b6948869d”,
“secret”: null
},
“tags”: null,
“type”: “Microsoft.ContainerService/ManagedClusters”
}
Pour accéder au cluster, nous devons configurer kubectl à l’aide de la commande suivante :
az aks get-credentials –resource-group pets-group –name pets-cluster
En cas de succès, cela générera la réponse suivante dans le terminal :
Merged “pets-cluster” as current context in /root/.kube/config
Maintenant, nous pouvons essayer d’utiliser kubectl en obtenant tous les nœuds du cluster :
kubectl get nodes
Cela se traduit par quelque chose de similaire à ceci :
NAME STATUS ROLES AGE VERSION
aks-nodepool1-54489083-0 Ready agent 13m v1.9.9
Nous voyons que notre cluster se compose d’un nœud de travail dont la version Kubernetes est 1.9.9 et qui est en fonction depuis 13 minutes. Le lecteur attentif a peut-être remarqué que la version de Kubernetes est un peu dépassée. La version la plus récente disponible sur AKS au moment de la rédaction est 1.11.2. C’est parfaitement bien et nous donne la possibilité de montrer comment nous pouvons mettre à niveau le cluster vers une version plus récente de Kubernetes.
Pousser des images Docker vers le registre de conteneurs Azure (ACR)
Lors du déploiement d’une application conteneurisée sur un cluster Kubernetes hébergé sur Azure, il est avantageux de stocker les images Docker sous-jacentes dans le même contexte de sécurité et à proximité du cluster. Ainsi, l’ACR est un bon choix. Avant de déployer notre application sur le cluster, nous allons donc pousser les images Docker nécessaires vers l’ACR.
Création d’un ACR
Une fois de plus, nous utiliserons Azure CLI pour créer un registre pour nos images Docker sur Azure. Le registre appartiendra également au groupe de ressources de groupe d’animaux de compagnie que nous avons créé dans la section Groupes de ressources Azure de ce chapitre. Nous pouvons utiliser la commande suivante pour créer un registre nommé <registry-name> :
az acr create –resource-group pets-group –name <registry-name> –sku Basic
Veuillez noter que le nom du registre est <registry-name>, qui doit être unique sur Azure. Ainsi, vous devez trouver votre propre nom unique et ne pouvez pas utiliser le même que l’auteur de cet article. C’est la raison pour laquelle nous utilisons un espace réservé <registry-name> au lieu d’un vrai nom ici. Dans mon cas, j’ai nommé le registre gnsPetsRegistry.
Notez que la commande précédente prend un certain temps. La réponse de la commande ressemble alors à la suivante :
{
“adminUserEnabled”: false,
“creationDate”: “2018-08-27T19:57:01.434521+00:00”,
“id”: “/subscriptions/186760ad-9152-4499-b317-xxxxxxxxxxxx/ resourceGroups/pets-group/providers/Microsoft.ContainerRegistry/
registries/gnsPetsRegistry”, “location”: “westeurope”,
“loginServer”: “gnspetsregistry.azurecr.io”,
“name”: “gnsPetsRegistry”,
“provisioningState”: “Succeeded”,
“resourceGroup”: “pets-group”,
“sku”: {
“name”: “Basic”,
“tier”: “Basic”
},
“status”: null,
“storageAccount”: null,
“tags”: {},
“type”: “Microsoft.ContainerRegistry/registries”
}
Notez l’entrée loginServer dans la sortie précédente. La valeur de cette clé correspond à l’URL que nous devons utiliser pour préfixer les images Docker lorsque nous les marquons afin qu’elles puissent ensuite être poussées vers l’ACR.
Après avoir créé le registre, nous pouvons nous y connecter en utilisant cette commande :
az acr login –name <registry-name>
La réponse devrait être :
Connexion réussie
Dans le portail Azure, nous devrions maintenant voir notre registre répertorié comme une ressource supplémentaire du groupe pets :
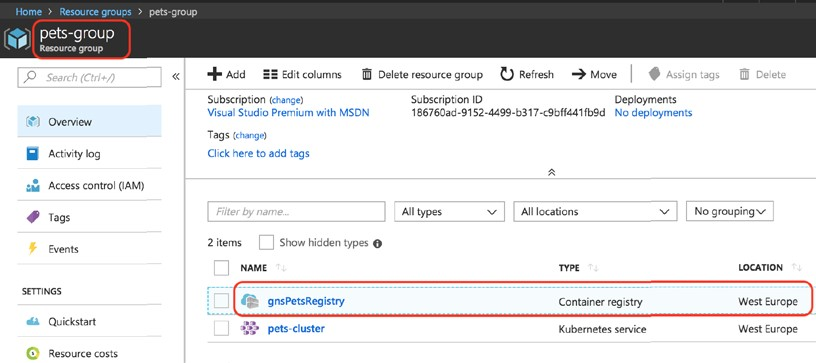
Nous sommes maintenant prêts à envoyer des images à notre ACR.
Marquage et transmission d’images Docker
Dans les chapitres précédents, nous avons construit les images Docker que nous allons utiliser dans ce chapitre. Mais pour pouvoir transmettre ces images à l’ACR, nous devons d’abord ré-étiqueter les images avec le préfixe d’URL correct pour l’ACR. Pour obtenir ce préfixe (ou serveur de connexion ACR, comme on l’appelle également ; nous l’avons déjà vu dans la sortie de la commande qui a été utilisée pour créer le registre), nous pouvons utiliser la commande suivante :
az acr list –resource-group pets-group –query “[]. {acrLoginServer:loginServer}” –output table
La commande précédente devrait entraîner une sortie similaire à celle-ci:
AcrLoginServer
————————–
gnspetsregistry.azurecr.io
OK, maintenant que nous avons un registre dans l’ACR, nous pouvons enfin marquer nos images Docker en conséquence. Dans mon cas, en utilisant l’URL gnspetsregistry.azurecr.io, la commande de l’image Docker pets-web : v1 ressemble à ceci :
docker image tag pets-web:v1 gnspetsregistry.azurecr.io/pets-web:v1
Une fois cela fait, nous pouvons pousser l’image avec la commande suivante :
docker image push gnspetsregistry.azurecr.io/pets-web:v1
Si tout fonctionne bien, vous devriez voir quelque chose de similaire à ceci :
The push refers to repository [gnspetsregistry.azurecr.io/pets-web]
9d5c9e1e5f97: Pushed
39f3a72e04a3: Pushed
3177c088200b: Pushed
5f896b8130b3: Pushed 287ef32bfa90: Pushed ce291010afac: Pushed
73046094a9b8: Mounted from alpine v1: digest: sha256:9a32931874f4fdf5… size: 1783
Faites maintenant la même chose pour l’image Docker pets-db: v1 :
docker image tag pets-db:v1 gnspetsregistry.azurecr.io/pets-db:v1 docker image push gnspetsregistry.azurecr.io/pets-db:v1
Configuration du principal de service
Comme dernière étape, nous devons donner au principal du service AKS que nous avons créé plus tôt dans ce chapitre les droits nécessaires pour accéder aux images et les extraire de notre registre de conteneurs. Tout d’abord, nous obtenons l’ID de ressource ACR (<acrId>) à l’aide de la commande suivante :
az acr show –resource-group pets-group \
–query “id” \
–output tsv \
–name <registry-name>
Cela devrait entraîner une sortie similaire à celle-ci :
/subscriptions/186760ad-9152-4499-b317-xxxxxxxxxxxx/resourceGroups/ pets-group/providers/Microsoft.ContainerRegistry/registries/ gnsPetsRegistry
Ayant ces informations, nous pouvons attribuer au principal du service identifié par <appId> l’accès en lecture nécessaire au registre de conteneurs identifié par <acrId> :
az role assignment create –assignee <appId> –scope <acrId>
–role Reader
Ici, <appId> est l’ID d’application du principal que nous avons stocké précédemment et <acrId> est l’ID de ressource ACR. La sortie ressemble à ceci :
{
“canDelegate”: null,
“id”: “/subscriptions/…/roleAssignments/1b7c2a63-c4d3-41a9-a1bc-
bd9d65966f43”,
“name”: “1b7c2a63-c4d3-41a9-a1bc-bd9d65966f43”,
“principalId”: “ab5fe519-3982-4aac-95e0-761c242aa61b”,
“resourceGroup”: “pets-group”,
“roleDefinitionId”: “/subscriptions/…/roleDefinitions/acdd72a7-
3385-48ef-bd42-f606fba81ae7”,
“scope”: “/subscriptions/…/registries/gnspetsregistry”,
“type”: “Microsoft.Authorization/roleAssignments”
}
Déployer une application dans le cluster Kubernetes
Après avoir réussi à pousser nos images Docker dans l’ACR, nous sommes prêts à déployer l’application dans le cluster Kubernetes dans AKS. Pour cela, nous pouvons utiliser le fichier manifeste, pets.yaml , qui fait partie du code source dans le dossier ch12 .
Veuillez ouvrir ce fichier avec votre éditeur et modifier le fichier en fonction de votre environnement. Remplacez l’URL du référentiel en préfixant les images Docker par votre URL spécifique.
Dans l’extrait de code suivant, nous voyons la valeur par défaut, gnsPetsRegistry, que vous devez remplacer par votre propre valeur <nom de registre> :
containers: – name: web image: gnsPetsRegistry.azurecr.io/pets-web:v1
Enregistrez les modifications. Utilisez ensuite kubectl pour appliquer le manifeste : kubectl apply -f /src/pets.yaml
La sortie de la commande précédente doit être similaire à ceci :
deployment.apps/db created service/db created deployment.apps/web created service/web created
Nous créons un service de type LoadBalancer pour le frontend de l’application Pets qui aura reçu une adresse IP publique par AKS. Cela prend un moment et nous pouvons observer l’état avec la commande suivante :
kubectl get service web –watch
Initialement, la sortie sera similaire à celle-ci (voir la sortie en attente dans la colonne EXTERNAL-IP) :
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
web LoadBalancer 10.0.49.36 <pending> 80:31035/TCP 41s
Une fois le déploiement terminé, <pending> sera remplacé par l’adresse IP publique et sera prêt à être utilisé pour accéder à notre application Pets :
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
web LoadBalancer 10.0.49.36 40.114.197.39 80:31035/TCP 2m
Ouvrez une fenêtre de navigateur sur http://<adresseIP>/pet et vous devriez voir une belle image de chat:
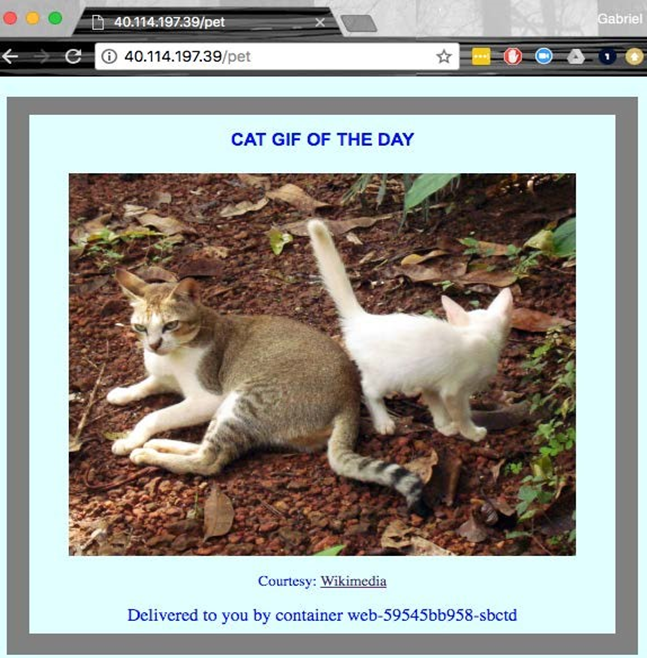
Application pour animaux de compagnie en cours d’exécution dans Kubernetes sur AKS
Avec cela, nous avons réussi à déployer une application complexe dans notre cluster Kubernetes sur AKS.
Mise à l’échelle de l’application Pets
Il existe deux façons de faire évoluer notre application Pets, à savoir :
- La première consiste à mettre à l’échelle le nombre d’instances d’application
- Le second consiste à mettre à l’échelle le nombre de nœuds de travail dans le cluster
La deuxième approche, bien sûr, n’a de sens que si nous adaptons le nombre d’instances d’application en même temps, afin que ces instances supplémentaires exploitent les ressources des nœuds de cluster nouvellement ajoutés.
Mise à l’échelle du nombre d’instances d’application
La mise à l’échelle du nombre d’instances exécutées par un service d’application donné est facile et nous pouvons utiliser kubectl pour ce faire. Supposons que notre application Pets réussisse si bien que nous devons augmenter le nombre d’instances Web à trois tandis que la base de données peut toujours gérer le trafic entrant avec une seule instance. Voyons d’abord quels pods fonctionnent actuellement dans notre cluster :
bash-4.4# kubectl get pods
NAME READY STATUS RESTARTS AGE
db-6746668f6c-wdscl 1/1 Running 0 2h
web-798745b679-8kh2j 1/1 Running 0 2h
Et nous pouvons voir que nous avons un pod pour chacun des deux services, web et db , opérationnel. Aucun des pods n’a été redémarré jusqu’à présent. Modifions notre déploiement Web à trois instances :
bash-4.4# kubectl scale –replicas=3 deployment/web deployment.extensions/web scaled
Et ceci est le résultat de l’opération de mise à l’échelle :
bash-4.4# kubectl get pods
NAME READY STATUS RESTARTS AGE
db-6746668f6c-wdscl 1/1 Running 0 2h
web-74dbc994bc-6f7qh 1/1 Running 0 14s
web-74dbc994bc-l99bh 1/1 Running 0 1m
web-74dbc994bc-rz8vs 1/1 Running 0 14s
Dans le navigateur exécutant l’application Pets, actualisez la vue plusieurs fois et notez que l’ID de l’instance de conteneur change de temps en temps. Il s’agit de l’équilibreur de charge Kubernetes en action, qui distribue les appels aux différentes instances Web.
La meilleure façon d’obtenir différentes instances du service Web consiste à ouvrir plusieurs fenêtres de navigation privée.
Mise à l’échelle du nombre de nœuds de cluster
Jusqu’à présent, nous n’avons travaillé qu’avec un seul nœud de cluster (travailleur). Nous pouvons utiliser l’Azure CLI pour augmenter le nombre de nœuds et ainsi fournir plus de puissance de calcul à notre application. Modifions notre cluster à trois nœuds :
az aks scale –resource-group=pets-group –name=pets-cluster –node-count 3
Cela prendra quelques minutes et, une fois terminé, vous devriez voir une réponse dans le terminal similaire à ceci:
{
“aadProfile”: null,
“addonProfiles”: null,
“agentPoolProfiles”: [
{
“count”: 3,
“maxPods”: 110,
“name”: “nodepool1”,
“osDiskSizeGb”: null,
“osType”: “Linux”,
“storageProfile”: “ManagedDisks”,
“vmSize”: “Standard_DS1_v2”,
“vnetSubnetId”: null
}
],
“dnsPrefix”: “pets-clust-pets-group-186760”,
“enableRbac”: true,
“fqdn”: “pets-clust-pets-group-186760-d706beb4.hcp.westeurope.azmk8s.
io”,
“id”: “/subscriptions/186760ad-9152-4499-b317-xxxxxxxxxxxx/ resourcegroups/pets-group/providers/Microsoft.ContainerService/
managedClusters/pets-cluster”, “kubernetesVersion”: “1.9.9”,
“linuxProfile”: {
“adminUsername”: “azureuser”,
“ssh”: {
“publicKeys”: [
{
“keyData”: “ssh-rsa AAAAB3NzaC…”
}
]
}
},
“location”: “westeurope”,
“name”: “pets-cluster”,
“networkProfile”: {
“dnsServiceIp”: “10.0.0.10”,
“dockerBridgeCidr”: “172.17.0.1/16”,
“networkPlugin”: “kubenet”,
“networkPolicy”: null,
“podCidr”: “10.244.0.0/16”,
“serviceCidr”: “10.0.0.0/16”
},
“nodeResourceGroup”: “MC_pets-group_pets-cluster_westeurope”,
“provisioningState”: “Succeeded”,
“resourceGroup”: “pets-group”,
“servicePrincipalProfile”: {
“clientId”: “a1a2bdbc-ba07-49bd-ae77-xxxxxxxxxxxx”,
“secret”: null
},
“tags”: null,
“type”: “Microsoft.ContainerService/ManagedClusters”
}
Nous pouvons vérifier la progression du provisionnement des nœuds de travail à l’aide de la commande suivante :
bash-4.4# kubectl get nodes –watch
aks-nodepool1-54489083-0 Ready agent 1d v1.9.9
aks-nodepool1-54489083-2 NotReady agent 0s v1.9.9
…
aks-nodepool1-54489083-0 Ready agent 1d v1.9.9
aks-nodepool1-54489083-2 Ready agent 2m v1.9.9
aks-nodepool1-54489083-1 Ready agent 20s v1.9.9
Bien sûr, l’ajout de nœuds de travail supplémentaires ne redistribue pas automatiquement les instances de service de notre application. Pour y parvenir, nous devons, par exemple, redimensionner à nouveau le service Web :
bash-4.4# kubectl scale –replicas=5 deployment/web deployment.extensions/web scaled
Nous pouvons maintenant utiliser la sortie large pour voir sur quels nœuds les pods ont atterri :
bash-4.4# kubectl get pods –output=’wide’
NAME READY STATUS RESTARTS AGE IP
NODE …
db-6746668f6c-wdscl 1/1 Running 0 3h 10.244.0.24
aks-nodepool1-54489083-0 …
web-59545bb958-2v4zp 1/1 Running 0 2m 10.244.1.3
aks-nodepool1-54489083-2 …
web-59545bb958-7mpfx 1/1 Running 0 31m 10.244.0.31
aks-nodepool1-54489083-0 …
web-59545bb958-9mc6m 1/1 Running 0 2m 10.244.1.2
aks-nodepool1-54489083-2 …
web-59545bb958-sbctd 1/1 Running 0 35m 10.244.0.29
aks-nodepool1-54489083-0 …
web-59545bb958-tvthv 1/1 Running 0 31m 10.244.0.30
aks-nodepool1-54489083-0 …
Nous pouvons voir que trois pods sont sur le premier et deux (les supplémentaires) ont été déployés sur le troisième nœud.
Surveillance du cluster et de l’application
Dans cette section, nous allons montrer trois éléments différents de notre cluster Kubernetes. Nous ferons ce qui suit :
- Surveiller la santé des conteneurs
- Afficher les journaux des maîtres Kubernetes
- Afficher les journaux des kublets installés sur chaque nœud de travail
Création d’un espace de travail d’analyse des journaux
Pour stocker les données de surveillance et de journalisation produites par notre cluster, nous avons besoin d’un espace de travail d’analyse des journaux. Nous utiliserons l’interface graphique du portail Azure pour en créer un dans notre groupe de ressources Pets-Group, en procédant comme suit :
1. Dans le portail, cliquez sur l’option + Créer une ressource.
2. Sélectionnez l’option Log Analytics, puis Créer. Saisissez les données requises, similaires à celles présentées dans la capture d’écran suivante :

Créer un espace de travail d’analyse des journaux
Une fois l’espace de travail créé, nous devrions le voir dans l’aperçu de notre groupe de ressources Pets- Group :
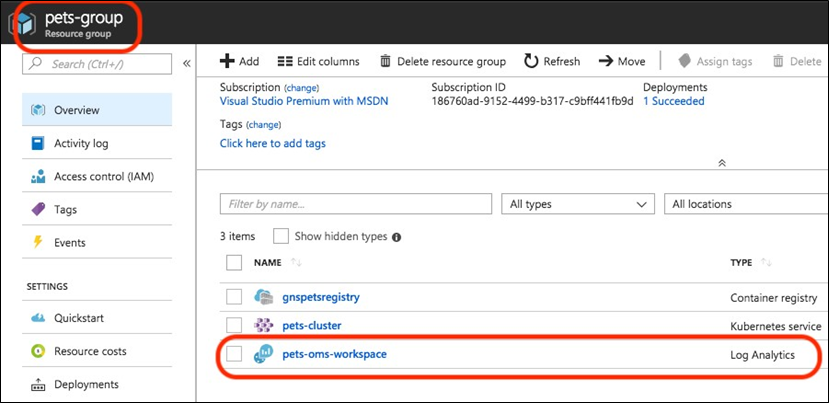
Espace de travail d’analyse des journaux dans le groupe de ressources Pets-Group
3. Cliquez sur l’entrée pets-oms-workspace pour voir les détails de l’espace de travail :
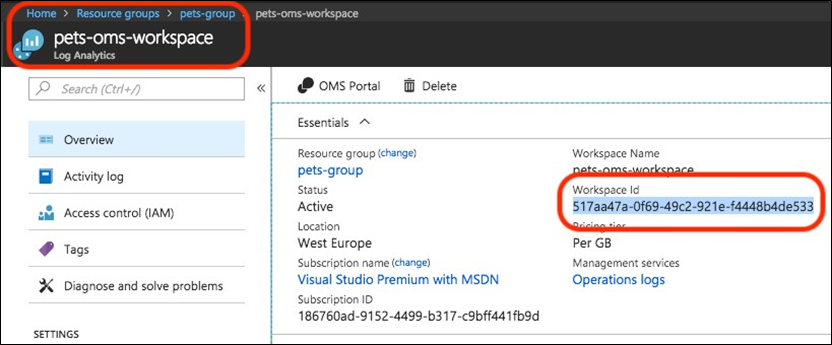
Vue détaillée de l’espace de travail d’analyse des journaux pets-oms-workspace
Notez <ID d’espace de travail> de l’espace de travail que vous venez de créer, car nous en avons besoin dans la section suivante.
Surveillance de la santé des conteneurs
Utilisons l’Azure CLI pour activer la surveillance du cluster d’animaux de compagnie. Nous aurions pu le faire lorsque nous avons créé le cluster, mais il est également possible de le faire ultérieurement.
Nous utilisons à nouveau l’Azure CLI pour activer la surveillance de notre cluster. Utilisez la commande suivante pour ce faire et assurez-vous de remplacer <ID d’espace de travail> par l’ID de votre espace de travail que vous venez de créer :
az aks enable-addons \
-a monitoring \
-g pets-group \
-n pets-cluster \
–workspace-resource-id <workspace ID>
Veuillez patienter car cette commande prend un certain temps. Il devrait finalement répondre avec ce qui suit (raccourci pour plus de lisibilité) :
…
“properties”: {
“provisioningState”: “Succeeded”
},
…
Notez que nous aurions également pu utiliser l’interface graphique du portail Azure ou un modèle Azure Resource Manager pour activer la surveillance.
La surveillance est basée sur un agent Log Analytics, qui s’exécute sur chaque nœud du cluster Kubernetes et collectera les mesures de mémoire et de processeur de tous les contrôleurs, nœuds et conteneurs fournis par l’API native de Kubernetes Metrics. Les métriques résultantes sont collectées par les agents et transmises et stockées dans l’espace de travail Log Analytics.
Une fois que nous avons activé la surveillance de notre cluster, nous pouvons vérifier que l’agent Log Analytics a été déployé dans l’espace de noms kube-system une fois pour chaque nœud de travail (3) :
bash-4.4# kubectl get ds omsagent –namespace=kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
omsagent 3 3 3 3 3 beta.kubernetes.io/os=linux 1d
Nous pouvons maintenant ouvrir le portail Azure pour afficher les métriques de notre cluster. Accédez aux groupes de ressources | groupe d’animaux | pets-cluster puis cliquez sur l’option Health (preview) pour voir un affichage similaire à la capture d’écran suivante :

Microsoft Azure AKS Health view
Dans cette vue, nous pouvons voir les métriques agrégées pour l’utilisation du processeur et de la mémoire ainsi que le nombre de nœuds et le nombre de pods actifs par cluster, nœud, contrôleur et conteneur.
Affichage des journaux des maîtres Kubernetes
Par défaut, les journaux de diagnostic sont désactivés et nous devons d’abord les activer. Nous pouvons utiliser notre espace de travail Log Analytics pets-oms- workspace comme cible pour les journaux. Pour activer les journaux de diagnostic, nous utiliserons cette fois le portail Azure. Suis les étapes :
1. Accédez au groupe de ressources groupe d’animaux domestiques et sélectionnez l’option Paramètres de diagnostic sur le côté gauche. Vous devriez voir quelque chose comme ceci :
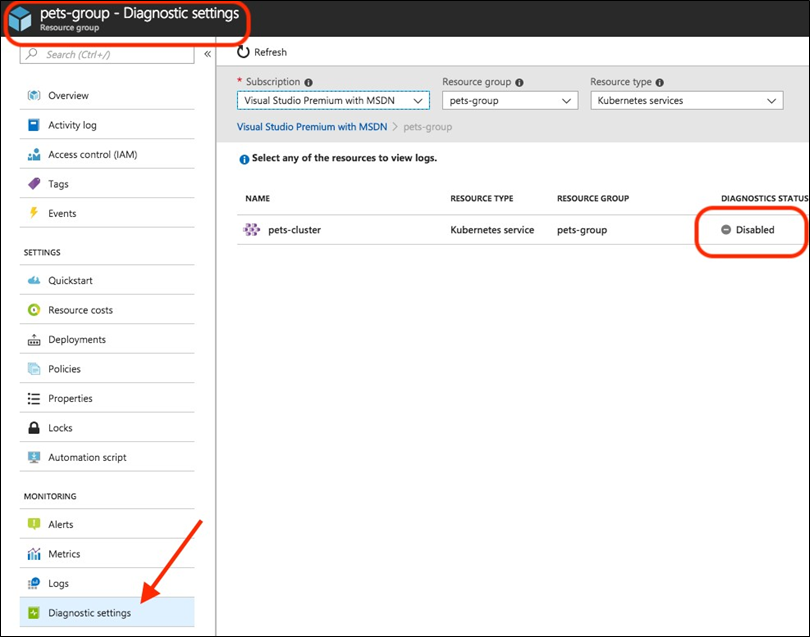
Paramètres du journal de diagnostic pour le groupe de ressources groupe d’animaux de compagnie
2. Sélectionnez l’entrée du groupe d’animaux de compagnie, puis cliquez sur le lien Activer les diagnostics. Remplissez le formulaire avec des valeurs similaires à celle illustrée dans la capture d’écran suivante :

Configuration des journaux de diagnostic du cluster Kubernetes
3. Assurez-vous que vous cochez la case Envoyer à Log Analytics et sélectionnez Petsoms-workspace comme cible pour les journaux.
4. Cliquez sur le bouton Enregistrer pour mettre à jour les paramètres.
Donnez au système quelques minutes ou quelques heures pour collecter des informations pertinentes avant de continuer.
Pour analyser les journaux, accédez au groupe de ressources pets- group et sélectionnez l’entrée de cluster pets . Sélectionnez ensuite l’option Journaux sur le côté gauche et vous verrez une vue similaire à celle montrée dans la capture d’écran suivante :
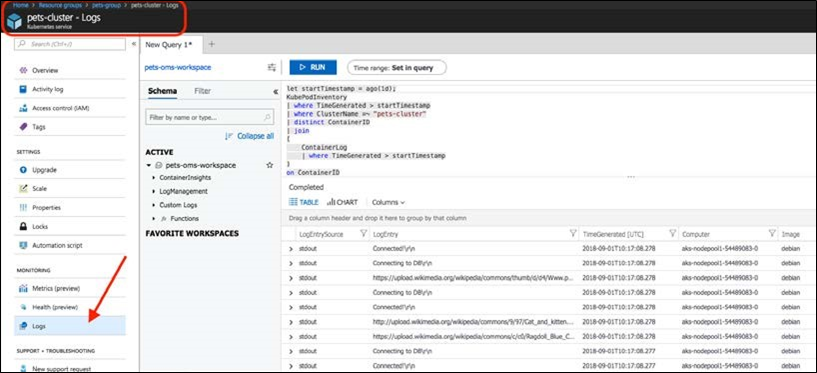
Analyser les journaux générés par le cluster Kubernetes et les conteneurs qui y sont exécutés
Dans la capture d’écran précédente, nous pouvons voir la requête par défaut qui a généré des entrées de journal produites par le conteneur ssh-helper exécutant Kubernetes sur le noeud aksnodepool1-54489083-0 . Ce conteneur sera présenté dans la section suivante.
Nous pouvons désormais utiliser le langage de requête riche qui nous est fourni par Azures Log Analytics pour obtenir plus d’informations sur la grande quantité de données de journalisation.
Affichage des journaux de kublet et de conteneur
Il est parfois nécessaire d’étudier les journaux d’un kubelet sur un nœud particulier du cluster Kubernetes. Pour ce faire, nous devons établir une connexion SSH à ce nœud particulier et pouvons ensuite utiliser l’outil Linux, journalctl , pour accéder à ces journaux.
Nous devons d’abord trouver le nœud (ou VM) dont nous voulons étudier les journaux du kublet. Énumérons toutes les machines virtuelles qui font partie de notre cluster de cluster d’animaux de compagnie dans le groupe de ressources, pets-group, dans la région de westeurope . Azure a implicitement créé un groupe de ressources appelé MC_ <nom de groupe> _ <nom de cluster> _ <nom de région> où il a placé toutes les ressources (y compris les machines virtuelles) de notre cluster Kubernetes. Ainsi, dans mon cas, le nom du groupe est MC_pets-group_pets-cluster_westeurope . Voici la commande qui me donne la liste des VMs:
bash-4.4# az vm list –resource-group MC_pets-group_pets-cluster_westeurope -o table
Name ResourceGroup Location Zones
———————— ————————————- ———- ——-
aks-nodepool1-54489083-0 MC_pets-group_pets-cluster_westeurope westeurope
Nous pouvons maintenant ajouter les clés SSH publiques que nous utilisons pour se connecter au cluster via la CLI Azure à cette machine virtuelle (avec le nom aks-nodepool1-54489083-0) avec la commande suivante :
bash-4.4# az vm user update \
–resource-group MC_pets-group_pets-cluster_westeurope \
–name aks-nodepool1-54489083-0 \
–username azureuser \
–ssh-key-value ~/.ssh/id_rsa.pub
Maintenant, nous devons obtenir l’adresse de cette machine virtuelle et pouvons le faire avec cette commande :
bash-4.4# az vm list-ip-addresses –resource-group MC_pets-group_pets-cluster_westeurope -o table
VirtualMachine PrivateIPAddresses
aks-nodepool1-54489083-0 10.240.0.4
Ayant toutes ces informations, nous avons besoin d’un moyen de SSH dans cette machine virtuelle. Nous ne pouvons pas simplement le faire directement à partir de notre poste de travail local sans tracas supplémentaires, mais un moyen simple consiste à exécuter un conteneur d’assistance (appelé ssh-helper) dans le cluster Kubernetes de manière interactive à partir duquel nous pouvons ensuite SSH dans la machine virtuelle. Commençons un tel conteneur d’aide à l’aide de la commande kubectl :
bash-4.4# kubectl run -it –rm ssh-helper –image=debian
root@ssh-helper-86966767d-v2xqg:/#
Ce conteneur n’a pas de client SSH installé. Faisons-le maintenant. Dans ce conteneur d’assistance, exécutez la commande suivante :
root@ssh-helper-86966767d-v2xqg:/# apt-get update && apt-get install openssh-client -y
Dans un autre terminal, nous pouvons nous attacher à notre conteneur Azure CLI comme suit :
$ docker container exec azure-cli /bin/bash
Ensuite, à l’intérieur du conteneur, exécutez la commande suivante pour voir tous les pods en cours d’exécution dans notre cluster:
bash-4.4# kubectl get pods
Voici le résultat de l’exécution de la commande précédente :
Module d’assistance SSH exécuté dans notre cluster Kubernetes
L’étape suivante consiste à copier notre clé SSH privée dans le pod à l’emplacement attendu. Nous pouvons utiliser cette commande pour le faire :
bash-4.4# kubectl cp ~/.ssh/id_rsa ssh-helper-86966767d-v2xqg:/id_rsa
Depuis le conteneur d’assistance, nous devons maintenant modifier les droits d’accès à cette clé SSH à l’aide de cette commande :
root@ssh-helper-86966767d-v2xqg:/# chmod 0600 id_rsa
Enfin, nous sommes prêts à SSH dans la machine virtuelle cible :
root@ssh-helper-86966767d-v2xqg:/# ssh -i id_rsa azureuser@10.240.0.4
Nous devrions alors voir quelque chose de similaire à ceci :
The authenticity of host ‘10.240.0.4 (10.240.0.4)’ can’t be established.
ECDSA key fingerprint is SHA256:pl03ZLFd0pkkPTtzDphSXCuNl0npBJO1JmU iLI5aSzY.Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added ‘10.240.0.4’ (ECDSA) to the list of known hosts.Welcome to Ubuntu 16.04.5 LTS (GNU/Linux 4.15.0-1021-azure x86_64)
Documentation: https://help.ubuntu.com * Management: https://
landscape.canonical.com
Support: https://ubuntu.com/advantage
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud 3 packages can be updated.
0 updates are security updates.
*** System restart required ***
The programs included with the Ubuntu system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. To run a command as administrator (user “root”), use “sudo <command>”.
See “man sudo_root” for details.
azureuser@aks-nodepool1-54489083-0:~$
Et nous y sommes ! Nous pouvons maintenant accéder à distance au nœud souhaité de notre cluster Kubernetes.
Ce que nous venons de montrer, pour accéder au cluster via un conteneur ou un pod d’assistance, est un moyen bien établi de déboguer un cluster Kubernetes distant et sécurisé.
Maintenant que nous sommes enfin sur la VM, en utilisant SSH, nous pouvons accéder aux journaux du kubelet local. Faites-le avec la commande suivante :
azureuser@aks-nodepool1-54489083-0:~$ sudo journalctl -u kubelet -o cat
Et nous devrions voir quelque chose dans le sens de cela (raccourci) :
Stopped Kubelet.
Starting Kubelet… net.ipv4.tcp_retries2 = 8
Bridge table: nat
Bridge chain: PREROUTING, entries: 0, policy: ACCEPT
Bridge chain: OUTPUT, entries: 0, policy: ACCEPT
Bridge chain: POSTROUTING, entries: 0, policy: ACCEPT
Chain PREROUTING (policy ACCEPT) …
I0831 08:30:52.872882 8787 server.go:182] Version: v1.9.9
I0831 08:30:52.873306 8787 feature_gate.go:226] feature gates: &{{} map[]}
I0831 08:30:54.082665 8787 mount_linux.go:210] Detected OS with systemd
W0831 08:30:54.083717 8787 cni.go:171] Unable to update cni config: No networks found in /etc/cni/net.d
I0831 08:30:54.091357 8787 azure.go:249] azure: using client_id+client_secret to retrieve access token
I0831 08:30:54.091777 8787 azure.go:382] Azure cloudprovider using rate limit config: QPS=3, bucket=10 …
De la même manière, nous pouvons désormais accéder aux journaux de n’importe quel conteneur exécuté sur ce nœud. Pour répertorier tous les conteneurs exécutés sur notre interface Web, exécutez la commande suivante :
azureuser@aks-nodepool1-54489083-0:~$ docker container ls | grep pets-web
614b6d27dc13 gnspetsregistry.azurecr.io/pets-web@ sha256:43d3f3b3…
493341aff54a gnspetsregistry.azurecr.io/pets-web@ sha256:43d3f3b3…
f5b730aa1449 gnspetsregistry.azurecr.io/pets-web@ sha256:43d3f3b3…
Apparemment, j’ai trois instances en cours d’exécution sur ce nœud. Analysons les journaux du premier :
azureuser@aks-nodepool1-54489083-0:~$ docker container logs 614b6d27dc13
Listening at 0.0.0.0:80
Connecting to DB
Connected!
http://upload.wikimedia.org/wikipedia/commons/d/dc/Cats_Petunia_and_
Mimosa_2004.jpg
Connecting to DB
Connected!
https://upload.wikimedia.org/wikipedia/commons/9/9e/Green_eyes_kitten.
Jpg
…
Gardez à l’esprit que la technique présentée ici peut être potentiellement dangereuse car nous venons d’obtenir un accès root au nœud de cluster. Utilisez cette technique uniquement sur des systèmes hors production, ou en cas d’urgence s’il n’y a pas de meilleur moyen d’accéder aux informations pertinentes.
Mise à niveau de l’application sans temps d’arrêt
Maintenant que l’application Pets fonctionne correctement dans le cloud, nous recevons des demandes de changement. Les utilisateurs ne semblent pas particulièrement apprécier la couleur de fond de notre application. Modifions cela, puis déployons les modifications d’une manière qui n’entraîne aucun temps d’arrêt pour l’application.
Dans les étapes suivantes, nous allons d’abord effectuer le changement de code dans notre projet, puis créer une nouvelle version de l’image de conteneur correspondante, la pousser vers l’ACR et la déployer à partir de là :
1. Dans le dossier ch12 / web / src du dossier labs, localisez le fichier main.css et ouvrez-le dans votre éditeur
2. Modifiez la couleur d’arrière – plan de l’élément de corps en une couleur de votre choix, comme le vert clair
3. Enregistrez les modifications
4. À partir de la construction du conteneur Azure CLI, balisez et envoyez la nouvelle version v2 du conteneur pets-web :
docker image build -t pets-web:v2 /src/web
docker image tag pets-web:v2 gnspetsregistry.azurecr.io/pets-web:v2
docker push gnspetsregistry.azurecr.io/pets-web:v2
5. Une fois que la nouvelle version de l’image Docker du service Web est dans l’ACR, nous pouvons émettre la commande de mise à jour pour le service Web :
kubectl set image deployment web web=gnspetsregistry.azurecr. io/pets-web:v2
6. Pendant la mise à jour (continue), nous pouvons surveiller les pods:
kubectl get pods –output=’wide’ –watch
Dans le manifeste pets.yaml , nous avons défini que les valeurs maxSurge et maxUnavailable sont chacune de 1. Cela signifie qu’un pod à la fois est mis à jour afin que toujours au moins quatre (5-1 = 4) pods soient disponibles à tout moment et donc l’application est toujours pleinement fonctionnelle.
7. Actualisez la fenêtre du navigateur avec l’application Animaux en cours d’exécution et vérifiez que la couleur d’arrière-plan a effectivement changé pour la nouvelle valeur.
Les nouveaux pods sont maintenant bien répartis entre les trois nœuds de travail du cluster Kubernetes.
Mettre à niveau Kubernetes
Nous avons noté précédemment que la version de Kubernetes (v1.9.9) installée sur nos nœuds de cluster est assez obsolète. Il est maintenant temps de montrer comment nous pouvons mettre à niveau Kubernetes sans causer de temps d’arrêt à l’application Pets. Notez que nous ne pouvons mettre à niveau Kubernetes que par étapes ; c’est-à-dire, une version mineure à la fois. Nous pouvons découvrir les versions disponibles pour nous mettre à niveau avec cette commande :
az aks get-upgrades –resource-group pets-group –name pets-cluster –output table
La sortie générée par la commande devrait ressembler à ceci :
Name ResourceGroup MasterVersion NodePoolVersion Upgrades
——- ————— ————— —————– ——————————————- —————————— —
Default pets-group 1.9.9 1.9.9 1.9.10, 1.10.3, 1.10.5, 1.10.6
Puisque nous sommes actuellement sur la version v1.9.9, nous ne pouvons augmenter dans la même version mineure 9 ou à l’une des versions v1.10.x . Une fois que nous sommes sur la version v1.10.x, nous pouvons passer à v1.11.x.
Mettons à niveau notre cluster vers la version v1.10.6 :
az aks upgrade –resource-group pets-group –name pets-cluster –kubernetes-version 1.10.6
La mise à niveau se fera nœud par nœud, garantissant que les applications s’exécutant sur le cluster sont toujours opérationnelles. La mise à niveau complète prend quelques minutes. Nous pouvons observer la progression en utilisant la commande suivante :
kubectl get nodes –watch
Nous devons voir comment un nœud à la fois est drainé puis désactivé avant d’être mis à niveau et remis en état.
Une fois terminé, une sortie similaire à celle-ci sera générée :
{
“aadProfile”: null,
“addonProfiles”: null,
“agentPoolProfiles”: [
{
“count”: 3,
“maxPods”: 110,
“name”: “nodepool1”,
“osDiskSizeGb”: null,
“osType”: “Linux”,
“storageProfile”: “ManagedDisks”,
“vmSize”: “Standard_DS1_v2”,
“vnetSubnetId”: null
}
],
“dnsPrefix”: “pets-clust-pets-group-186760”,
“enableRbac”: true,
“fqdn”: “pets-clust-pets-group-186760-d706beb4.hcp.westeurope. azmk8s.io”,
“id”: “/subscriptions/186760ad-9152-4499-b317-xxxxxxxxxxxx/ resourcegroups/pets-group/providers/Microsoft.ContainerService/
managedClusters/pets-cluster”, “kubernetesVersion”: “1.10.6”,
“linuxProfile”: {
“adminUsername”: “azureuser”,
“ssh”: {
“publicKeys”: [
{
“keyData”: “ssh-rsa …”
}
]
}
},
“location”: “westeurope”,
“name”: “pets-cluster”,
“networkProfile”: {
“dnsServiceIp”: “10.0.0.10”,
“dockerBridgeCidr”: “172.17.0.1/16”,
“networkPlugin”: “kubenet”,
“networkPolicy”: null,
“podCidr”: “10.244.0.0/16”,
“serviceCidr”: “10.0.0.0/16”
},
“nodeResourceGroup”: “MC_pets-group_pets-cluster_westeurope”,
“provisioningState”: “Succeeded”,
“resourceGroup”: “pets-group”,
“servicePrincipalProfile”: {
“clientId”: “a1a2bdbc-ba07-49bd-ae77-xxxxxxxxxxxx”,
“secret”: null
},
“tags”: null,
“type”: “Microsoft.ContainerService/ManagedClusters”
}
Pour vérifier la mise à niveau, nous pouvons utiliser cette commande :
az aks show –resource-group pets-group –name pets-cluster –output table
Il en résulte la sortie suivante :
Name Location ResourceGroup KubernetesVersion ProvisioningState Fqdn
———— ———- ————— ——————- ——————- ——————– ————- ————
pets-cluster westeurope pets-group 1.10.6 Succeeded pets-clust…
Nous avons réussi à mettre à niveau notre cluster à trois nœuds de Kubernetes v1.9.9 à v1.10.6. Cette mise à niveau inclut les nœuds maîtres. Pendant tout le processus, l’application déployée sur le cluster était pleinement opérationnelle.
Débogage de l’application en cours d’exécution dans AKS
Jusqu’à présent, nous avons vu comment déployer et exécuter des applications dans Kubernetes sur AKS. Ceci est intéressant pour les ingénieurs d’exploitation qui travaillent avec des applications finies. Cependant, les développeurs aimeraient parfois développer et déboguer de manière interactive des applications directement dans le cloud, en particulier si ces applications se composent de nombreux services ou composants individuels exécutés dans des conteneurs sur Kubernetes. Au moment d’écrire ces lignes, Microsoft propose un aperçu des soi-disant Azure Dev Spaces sur AKS, qui permettent aux développeurs de faire exactement ce type de développement interactif et de débogage.
Création d’un cluster Kubernetes pour le développement
Dans cette section, nous allons créer un cluster Kubernetes dans AKS d’Azure qui peut être utilisé à des fins de développement. Nous utiliserons ce cluster pour montrer comment déboguer à distance une application qui s’exécute dessus. Nous utiliserons le portail Azure pour provisionner le cluster :
1. Ouvrez le portail Azure sur https://portal.azure.com/ et connectez-vous à votre compte
2. Sélectionnez l’option + Créer une ressource et sélectionnez Service Kubernetes
3. Remplissez les détails nécessaires pour créer un cluster Kubernetes à des fins de développement
Dans la capture d’écran suivante, nous pouvons voir un exemple de configuration que l’auteur a utilisé lors de la rédaction de cette section :
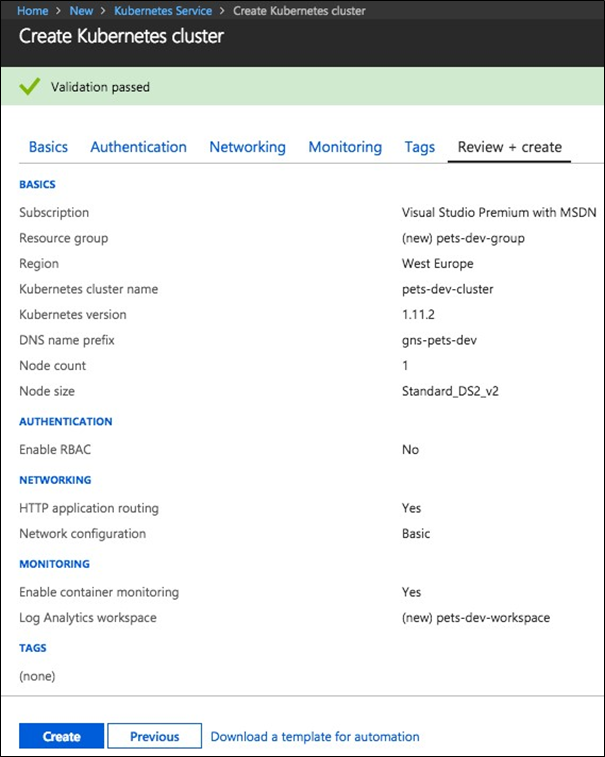
Configuration d’un cluster de développement Kubernetes dans AKS
Plus précisément, notez que j’ai créé un nouveau groupe de ressources, pets-dev-group, sélectionné la valeur pets-dev-cluster pour le nom du cluster et créé un nouvel espace de travail Log Analytics, pets-dev-workspace, pour capturer tous les journaux et la surveillance les données produites par le cluster et les applications qui y sont exécutées. Il est également important d’activer le routage d’application HTTP.
Après avoir cliqué sur le bouton Créer, l’approvisionnement complet prend quelques minutes. Vous pouvez continuer l’installation de l’Azure CLI sur votre poste de travail en attendant, comme décrit dans la section suivante.
Configuration de l’environnement
Dans cette section, nous allons configurer notre environnement de travail (c’est-à-dire notre ordinateur), pour pouvoir travailler avec Azure à partir de la ligne de commande. Suis les étapes:
1. Pour travailler avec Azure Dev Spaces, installez Azure CLI en mode natif sur votre poste de travail. Voici comment procéder sur un Mac :
$ brew install azure-cli
2. Assurez-vous que vous disposez de la dernière version de l’interface CLI. La version retournée doit être 2.0.44 ou plus récente :
$ az –version azure-cli (2.0.45) …
3. Connectez-vous à Azure :
$ az login
Ne continuez pas tant que l’approvisionnement de votre cluster de développement Kubernetes n’est pas terminé.
4. Pour configurer Azure Dev Space dans notre cluster de développement Kubernetes, utilisez la commande suivante :
$ az aks use-dev-spaces -g pets-dev-group -n pets-dev-cluster
The installed extension ‘dev-spaces-preview’ is in preview.
Installing Dev Spaces (Preview) commands…
Installing Azure Dev Spaces (Preview) client components…
By continuing, you agree to the Microsoft Software License Terms
(https://aka.ms/azds-LicenseTerms) and Microsoft Privacy Statement (https://aka.ms/privacystatement). Do you want to continue? (Y/n):
You may be prompted for your administrator password to authorize the installation process.
Password:
[INFO] Downloading Azure Dev Spaces (Preview) Package…
[INFO] Downloading Bash completion script…
Successfully installed Azure Dev Spaces (Preview) to /usr/local/ bin/azds.
An Azure Dev Spaces Controller will be created that targets resource ‘pets-dev-cluster’ in resource group ‘pets-dev-group’.
Continue? (y/N): Y
Creating and selecting Azure Dev Spaces Controller ‘pets-devcluster’ in resource group ‘pets-dev-group’ that targets resource
‘pets-dev-cluster’ in resource group ‘pets-dev-group’…
Select a dev space or Kubernetes namespace to use as a dev space.
[1] default
Type a number or a new name: pets
Dev space ‘pets’ does not exist and will be created.
Select a parent dev space or Kubernetes namespace to use as a parent dev space.
<none>
default
Type a number: 0
Creating and selecting dev space ‘pets’…2s
Managed Kubernetes cluster ‘pets-dev-cluster’ in resource group ‘pets-dev-group’ is ready for development in dev space ‘pets’.
Type `azds prep` to prepare a source directory for use with Azure Dev Spaces and `azds up` to run.
Déployer et exécuter un service
Nous sommes maintenant prêts à créer, déployer et exécuter notre premier service dans le cluster Kubernetes sur AKS.
Accédez au sous-dossier ch12-dev-espaces / web de votre dossier labs :
$ cd ~/labs/ch12-dev-spaces/web
Et exécutez la commande azds prep, comme indiqué dans la sortie précédente. Cela créera les graphiques Helm pour ce composant :
$ azds prep –public
Preparing ‘web’ of type ‘node.js’ with files:
/.dockerignore
/azds.yaml
/charts/web/.helmignore
/charts/web/Chart.yaml
/charts/web/templates/_helpers.tpl
/charts/web/templates/deployment.yaml
/charts/web/templates/ingress.yaml
/charts/web/templates/NOTES.txt
/charts/web/templates/secrets.yaml
/charts/web/templates/service.yaml
/charts/web/values.yaml Type ‘azds up’ to run.
Pour construire les artefacts et les exécuter dans AKS, nous pouvons maintenant simplement utiliser la commande suivante :
$ azds up
Using dev space ‘pets’ with target ‘pets-dev-cluster’
Synchronizing files…1s
Installing Helm chart…10s
Waiting for container image build…7s Building container image…
Step 1/8 : FROM node:10.9-alpine
Step 2/8 : RUN mkdir /app
Step 3/8 : WORKDIR /app
Step 4/8 : COPY package.json /app/
Step 5/8 : RUN npm install
Step 6/8 : COPY ./src /app/src
Step 7/8 : EXPOSE 80
Step 8/8 : CMD node src/server.js
Built container image in 51s
Waiting for container…8s
(pending registration) Service ‘web’ port ‘http’ will be available at
http://web.2785a289211f45f6a8fa.westeurope.aksapp.io/
Service ‘web’ port 80 (TCP) is available at http://localhost:52353
press Ctrl+C to detach web-6488b5585b-c9cg5: Listening at 0.0.0.0:80
Nous pouvons immédiatement ouvrir une fenêtre de navigateur à http://localhost: 52353, comme indiqué dans la sortie précédente, pour accéder à notre service qui s’exécute maintenant dans AKS. Quelques minutes plus tard, nous devrions également pouvoir utiliser le DNS public (http://web.2785a289211f45f6a8fa.westeurope.aksapp.io) fourni dans la sortie précédente pour accéder au service. Ce que nous devrions voir est la capture d’écran suivante :
Application d’animaux domestiques exécutée dans Azure Dev Spaces
À tout moment, nous pouvons arrêter (ou détacher) le service en appuyant sur Ctrl + C dans le terminal, puis nous pouvons mettre à jour le code. Une fois terminé, redémarrez simplement la nouvelle version avec $ azds up. Pour ce faire, maintenant et appuyez sur Ctrl + C. Modifiez ensuite le message dans le fichier server.js pour qu’il devienne My Pets Application. Enregistrez les modifications, puis exécutez la commande suivante :
$ azds up
Une fois l’application prête, actualisez le navigateur et vous devriez voir le message modifié.
Pour préparer l’exercice suivant, appuyez sur Ctrl + C, puis exécutez la commande suivante pour arrêter et supprimer le composant de notre cluster Kubernetes:
$ azds down
‘web’ identifies Helm release ‘pets-web-9c1bf6d2’ which includes these services: web
Are you sure you want to delete this release? (y/N): Y
Deleting Helm release ‘pets-web-9c1bf6d2’…19s
Débogage à distance d’un service à l’aide de Visual Studio Code
Bien sûr, cela est un peu lent et nous pouvons faire mieux en utilisant le débogage à distance dans Visual Studio Code (VS Code) :
1. Ouvrez VS Code et téléchargez et installez l’extension Azure Dev Spaces pour celui-ci. Redémarrez ensuite VS Code.
2. Ouvrez VS Code à partir du dossier ch12-dev-espaces / web. Il vous sera demandé si l’extension Azure Dev Spaces doit créer les actifs nécessaires pour créer et déboguer le composant Web. Sélectionnez l’option Oui :

Visual Studio Code, création d’actifs de génération et de débogage
Vous remarquerez qu’un dossier, .vscode , sera créé dans votre projet qui contient les deux fichiers, launch.json et tasks.json . Ils sont utilisés lors du débogage à distance du service Web .
3. Dans VS Code, appuyez sur F5 et observez comment le service est créé et exécuté en AKS en mode débogage. Cela utilisera la tâche de lancement appelée Launch Server (AZDS) , comme nous pouvons le voir dans le volet de débogage de VS Code:
Lancement du service Web en mode débogage sur AKS
4. Définissez un point d’arrêt sur la ligne 13 du fichier server.json :
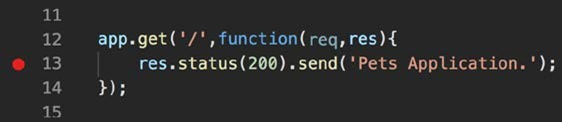
Définition d’un point d’arrêt dans le code du service Web
Si vous actualisez maintenant le navigateur à http://localhost:52353, l’exécution du code doit s’arrêter au point d’arrêt.
Vous pouvez utiliser la barre d’outils de débogage dans VS Code pour parcourir le code ligne par ligne ou poursuivre l’exécution :
Débogage étape par étape
Activation du développement de style de modification et de poursuite dans le cloud
Pour permettre une expérience de modification et de poursuite, nous pouvons faire encore mieux. Pour cela, nous avons une deuxième tâche de lancement appelée Attach (AZDS) , qui est basée sur nodemon . Chaque fois que nous mettons à jour le code localement, cela se reflète dans le conteneur qui s’exécute à distance dans AKS, et nodemon lors de la détection des modifications redémarrera automatiquement l’application dans le conteneur. Par conséquent, nous pouvons changer et mettre à jour le code dans VS Code, enregistrer les modifications et quelques secondes plus tard, utiliser et déboguer le nouveau code dans AKS.
Si votre application est toujours en cours d’exécution depuis l’exercice précédent, arrêtez le débogage maintenant, appuyez sur Ctrl + C dans la console, puis exécutez la commande $ azds down pour arrêter et supprimer le service.
Dans la vue de débogage de VS Code, sélectionnez la tâche de lancement Attacher au serveur (AZDS) , puis appuyez sur F5 . Une fois le service déployé, vous pouvez définir des points d’arrêt comme précédemment et parcourir le code, mais, en plus de cela, vous pouvez désormais également modifier le code dans server.js.
Une fois que vous avez enregistré les modifications, les fichiers modifiés seront synchronisés avec AKS et nodemon redémarre l’application en cours d’exécution à l’intérieur du conteneur sur Kubernetes. Essayez cela en ajoutant l’extrait de code suivant au fichier server.js :
Ajout de code à un composant en cours d’exécution dans AKS
Après avoir enregistré le fichier et attendu quelques secondes, accédez à l’URL http://localhost:52353/pet. Vous devriez voir une belle photo de chat.
Nettoyage
Pour éviter des coûts inutiles, nous devons nettoyer (c’est-à-dire supprimer) toutes les ressources que nous avons créées sur Microsoft Azure. C’est assez simple car nous avons regroupé toutes nos ressources dans les groupes de ressources pets-group et pets-dev-group, et nous avons seulement besoin de supprimer les groupes pour se débarrasser de toutes les ressources contenues. Nous pouvons le faire avec notre CLI Azure :
bash-4.4# az group delete –name pets-group
Are you sure you want to perform this operation? (y/n): y
bash-4.4# az group delete –name pets-dev-group Are you sure you want to perform this operation? (y/n): y
L’ensemble du processus prendra quelques minutes pour se terminer.
Vous pouvez également vouloir vérifier dans le portail Azure que toutes les ressources ont bien été supprimées.
Résumé
Dans ce chapitre, nous avons appris à approvisionner un cluster Kubernetes entièrement hébergé sur le cloud Microsoft offrant AKS. De plus, nous avons appris à déployer, exécuter, surveiller, mettre à niveau et même déboguer de manière interactive une application exécutée dans ce cluster sur AKS. Nous avons également obtenu un bref aperçu de la façon dont nous pouvons mettre à jour la version de Kubernetes sur AKS sans perturber les applications en cours d’exécution dans le cluster.
Avec cela, vous avez réussi à parcourir cet article, et il est temps pour moi de vous remercier d’avoir choisi cet article comme guide sur votre voyage d’un débutant Docker à un expert qui conteneurise leurs applications complexes et critiques et les déploie sur Kubernetes fonctionnant dans le cloud.
Questions
Pour évaluer vos connaissances, veuillez répondre aux questions suivantes :
1. Quelles sont les trois options dont vous disposez pour provisionner un cluster Kubernetes entièrement hébergé sur AKS ?
2. Nommez deux ou trois raisons pour lesquelles il est judicieux d’héberger vos images Docker dans l’ACR lorsque vous utilisez AKS.
3. Expliquez en trois à quatre phrases courtes les principales étapes nécessaires pour exécuter votre application conteneurisée sur AKS.
4. Montrez comment vous pouvez accéder aux fichiers journaux de conteneur de votre application exécutée sur AKS.
5. Décrivez comment mettre à l’échelle le nombre de nœuds de votre cluster Kubernetes sur AKS.
Évaluation
Chapitre 1: Que sont les conteneurs et pourquoi devrais-je les utiliser?
1. Les bonnes réponses sont : 4, 5.
2. Un conteneur Docker est, pour l’informatique, ce qu’un conteneur d’expédition est pour l’industrie du transport. Il définit une norme sur la façon d’emballer les marchandises. Dans ce cas, les produits sont les applications que les développeurs écrivent. Les fournisseurs (dans ce cas, les développeurs) sont responsables d’emballer les marchandises dans le conteneur et de s’assurer que tout rentre comme prévu. Une fois les marchandises emballées dans un conteneur, elles peuvent être expédiées. Puisqu’il s’agit d’un conteneur standard, les expéditeurs peuvent standardiser leurs moyens de transport tels que les camions, les trains ou les navires. L’expéditeur ne se soucie pas vraiment du contenu d’un conteneur. De plus, le processus de chargement et de déchargement d’un moyen de transport à un autre (par exemple, train pour expédier) peut être hautement normalisé. Cela augmente considérablement l’efficacité du transport. De même, un ingénieur des opérations en informatique peut prendre un conteneur de logiciels construit par un développeur et l’expédier à un système de production et l’exécuter de manière hautement standardisée, sans se soucier de ce qu’il y a dans le conteneur. Ça va juste marcher.
3. Certaines des raisons pour lesquelles les conteneurs changent la donne sont :
- Les conteneurs sont autonomes et donc s’ils s’exécutent sur un seul système, ils s’exécutent partout où un conteneur peut fonctionner.
- Les conteneurs s’exécutent sur site et dans le cloud, ainsi que dans des environnements hybrides. Ceci est important pour les entreprises typiques d’aujourd’hui, car il permet une transition généralement fluide du sur site au cloud.
- Les images de conteneur sont construites ou packagées par les personnes qui connaissent le mieux – les développeurs.
- Les images des conteneurs sont immuables, ce qui est important pour une bonne gestion des versions.
- Les conteneurs facilitent une chaîne d’approvisionnement de logiciels sécurisée basée sur l’encapsulation (à l’aide d’espaces de noms Linux et de groupes de contrôle), les secrets, la confiance du contenu et l’analyse de la vulnérabilité des images.
4. Un conteneur s’exécute partout où un conteneur peut s’exécuter car :
- Les conteneurs sont des boîtes noires autonomes. Ils encapsulent non seulement une application mais toutes ses dépendances, telles que les bibliothèques et les frameworks, les données de configuration, les certificats, etc.
- Les conteneurs sont basés sur des normes largement acceptées telles que l’OCI.
- TODO : ajoutez plus de raisons.
5. Faux ! Les conteneurs sont utiles pour les applications modernes ainsi que pour conteneuriser les applications traditionnelles. L’avantage pour une entreprise lors de cette dernière est énorme. Des économies de 50% ou plus sur la maintenance des applications héritées ont été signalées. Le temps entre les nouvelles versions de ces applications héritées pourrait être réduit jusqu’à 90%. Ces chiffres ont été rendus publics par de vrais clients d’entreprise.
6. 50% ou plus.
7. Les conteneurs sont basés sur des espaces de noms Linux (réseau, processus, utilisateur, etc.) et des groupes de contrôle (cgroups).
Chapitre 2: Mise en place d’un environnement de travail
1. docker-machine peut être utilisé pour effectuer les opérations suivantes :
- Créez une machine virtuelle configurée comme hôte Docker dans différents environnements, tels que VirtualBox
- SSH dans un hôte Docker
- Configurer la CLI Docker locale pour l’accès à un hôte Docker distant
- Lister tous les hôtes dans un environnement donné
- Supprimez ou détruisez les hôtes existants
2. Vrai. Docker pour Windows crée une machine virtuelle Linux dans Hyper-V, sur laquelle il exécute ensuite des conteneurs Linux.
3. Les conteneurs sont utilisés de manière optimale dans CI / CD, qui concerne l’automatisation. Chaque étape, de la création d’une image de conteneur, l’expédition de l’image et enfin l’exécution de conteneurs à partir de cette image, est idéalement scriptée pour une productivité maximale. Avec lui, on obtient un processus reproductible et vérifiable.
4. Ubuntu 17.4 ou version ultérieure, CentOS 7.x, Alpine 3.x, Debian, Suse Linux, RedHat Linux, etc.
5. Windows 10 Professionnel ou Enterprise Edition, Windows Server 2016.
Chapitre 3: Travailler avec des conteneurs
1. Les états d’un conteneur sont les suivants
- Créé
- Courir
- Quitté
2. La commande suivante nous aide à découvrir ce qui fonctionne actuellement sur notre hôte:
$ docker container ls
3. La commande suivante est utilisée pour répertorier les ID de tous les conteneurs : $ docker container ls -q
Chapitre 4: Création et gestion d’images de conteneurs
Voici les réponses possibles aux questions :
1. Dockerfile:
FROM ubuntu:17.04
RUN apt-get update
RUN apt-get install -y ping
ENTRYPOINT ping
CMD 127.0.0.1
2. Pour obtenir le résultat, vous pouvez exécuter les étapes suivantes :
$ docker container run -it –name sample \ alpine:latest /bin/sh / # apk update && \ apk add -y curl && \
rm -rf /var/cache/apk/* / # exit
$ docker container commit sample my-alpine:1.0
$ docker container rm sample
3. Voici un exemple du Hello World en C :
- Créez un fichier hello.c avec ce contenu :
#include <stdio.h>
int main()
{
printf(“Hello, World!”);
return 0;
}
- Créez un Dockerfile avec ce contenu :
FROM alpine:3.5 AS build
RUN apk update && \
apk add –update alpine-sdk
RUN mkdir /app
WORKDIR /app
COPY hello.c /app
RUN mkdir bin
RUN gcc -Wall hello.c -o bin/hello
FROM alpine:3.5
COPY –from=build /app/bin/hello /app/hello
CMD /app/hello
4. Certaines caractéristiques d’une image Docker sont :
- Il est immuable
- Il est composé de couches immuables
- Chaque couche contient uniquement ce qui a changé (le delta) par rapport aux couches inférieures
- Une image est une (grande) archive tar de fichiers et de dossiers
- Une image est un modèle pour les conteneurs
5. L’option 3 est correcte. Nous devons d’abord nous assurer que nous sommes connectés, puis nous marquons l’image et enfin la poussons. Puisqu’il s’agit d’une image, nous utilisons l’image docker … et non le conteneur docker … (comme au numéro 4).
Chapitre 5 : Volumes de données et gestion du système
La façon la plus simple de jouer avec les volumes est d’utiliser la Docker Toolbox comme lorsque vous utilisez directement Docker pour Mac ou Docker pour Windows, puis les volumes sont stockés dans une machine virtuelle Linux (quelque peu cachée) que Docker pour Mac / Win utilise de manière transparente.
Ainsi, nous suggérons ce qui suit :
$ docker-machine create –driver virtualbox volume-test
$ docker-machine ssh volume-test
Et maintenant que vous êtes dans une machine virtuelle Linux appelée volume-test, vous pouvez exécuter les exercices suivants :
1. Pour créer un volume nommé, exécutez la commande suivante :
$ docker volume create my-products
2. Exécutez la commande suivante :
$ docker container run -it –rm \
-v my-products:/data:ro \
alpine /bin/sh
3. Pour obtenir le chemin sur l’hôte pour le volume, utilisez, par exemple, cette commande :
$ docker volume inspect my-products | grep Mountpoint
Ce qui (si vous utilisez docker-machine et VirtualBox) devrait entraîner :
“Mountpoint”: “/mnt/sda1/var/lib/docker/volumes/my-products/_ data”
Exécutez maintenant la commande suivante :
$ sudo su
$ cd /mnt/sda1/var/lib/docker/volumes/my-products/_data
$ echo “Hello world” > sample.txt
$ exit
4. Exécutez la commande suivante :
$ docker run -it –rm -v my-products:/data:ro alpine /bin/sh
# / cd /data
# / cat sample.txt
Dans un autre terminal, exécutez :
$ docker run -it –rm -v my-products:/app-data alpine /bin/sh
# / cd /app-data
# / echo “Hello other container” > hello.txt
# / exit
5. Exécutez une commande comme celle-ci :
$ docker container run -it –rm \
-v $HOME/my-project:/app/data \
alpine /bin/sh
6. Quittez les deux conteneurs puis revenez sur l’hôte, exécutez cette commande :
$ docker volume prune
7. Exécutez la commande suivante :
$ docker system info | grep Version
Ce qui devrait produire quelque chose de similaire à ceci :
Server Version: 17.09.1-ce
Kernel Version: 4.4.104-boot2docker
Si vous avez utilisé docker-machine pour créer et utiliser une machine virtuelle Linux dans VirtualBox, n’oubliez pas de nettoyer une fois que vous avez terminé :
$ docker-machine rm volume-test
Chapitre 6: Architecture d’application distribuée
1. Dans un système composé de plusieurs parties, la défaillance d’au moins une partie n’est qu’une question de temps. Pour éviter tout temps d’arrêt si une telle situation se produit, on exécute plusieurs instances de chaque composant. Si l’une des instances échoue, il en reste d’autres pour répondre aux demandes.
2. Dans une architecture d’application distribuée, nous avons de nombreuses pièces mobiles. Si le service A a besoin d’accéder à une instance du service B, il ne peut pas savoir où trouver une telle instance. Les instances peuvent se trouver sur n’importe quel nœud aléatoire du cluster et elles peuvent même aller et venir comme le moteur d’orchestration le juge opportun. Nous n’identifions donc pas l’instance cible par, disons, son adresse IP et son port, mais plutôt par son nom et son port. Un service DNS sait comment résoudre un nom de service en une adresse IP car il dispose de toutes les informations sur toutes les instances de service exécutées dans le cluster.
3. Un disjoncteur est un mécanisme qui permet d’éviter les défaillances en cascade dans une application distribuée déclenchées par un seul service défaillant. Le disjoncteur observe une demande d’un service à un autre et mesure la latence dans le temps et le nombre d’échecs ou de temporisations de demande. Si une certaine instance cible provoque trop d’échecs, les appels qui lui sont adressés sont interceptés et un code d’erreur est renvoyé à l’appelant, ce qui donne instantanément à la cible le temps de récupérer si possible, et l’appelant, à son tour, sait instantanément qu’il doit se dégrader son propre service ou essayez avec une autre instance du service cible.
4. Un monolithe est une application qui se compose d’une seule base de code fortement couplée. Si des modifications sont apportées au code, aussi minime soit-il, l’application entière doit être compilée, mise en package et redéployée. Un monolithe est simple à déployer et à surveiller en production car il comporte très peu de pièces mobiles. Les monolithes sont difficiles à entretenir et à étendre. Une application distribuée se compose de nombreux services faiblement couplés. Chaque service provient de sa propre base de code source indépendante. Les services individuels peuvent et ont souvent des cycles de vie indépendants. Ils peuvent être développés et révisés indépendamment. Les applications distribuées sont plus difficiles à gérer et à surveiller.
5. On parle d’un déploiement bleu-vert lorsqu’une version en cours d’exécution d’un service, appelé bleu, est remplacée par une nouvelle version du même service, appelée verte. Le remplacement se produit sans aucun temps d’arrêt car pendant que la version bleue est toujours en cours d’exécution, la version verte du service est installée sur le système et, une fois prête, un simple changement dans la configuration du routeur qui achemine le trafic vers le service est nécessaire pour que le trafic est désormais entièrement dirigé vers le vert au lieu du bleu.
Chapitre 7: Réseau à hôte unique
1. Les trois éléments principaux sont le bac à sable, le point de terminaison et le réseau
2. Exécutez cette commande :
$ docker network create –driver bridge frontend
3. Exécutez cette commande :
$ docker container run -d –name n1 \
–network frontend -p 8080:80 \
nginx:alpine
$ docker container run -d –name n2 \
–network frontend -p 8081:80 \
nginx:alpine
Testez que les deux instances Nginx sont en cours d’exécution :
$ curl -4 localhost:8080
$ curl -4 localhost:8081
Vous devriez voir la page d’accueil de Nginx dans les deux cas.
4. Pour obtenir les adresses IP de tous les conteneurs attachés, exécutez :
$ docker network inspect frontend | grep IPv4Address
Vous devriez voir quelque chose de semblable au suivant :
“IPv4Address”: “172.18.0.2/16”,
“IPv4Address”: “172.18.0.3/16”,
Pour obtenir le sous-réseau utilisé par le réseau, utilisez ce qui suit (par exemple) :
$ docker network inspect frontend | grep subnet
Vous devriez recevoir quelque chose dans le sens de ce qui suit (obtenu à partir de l’exemple précédent) :
“Subnet”: “172.18.0.0/16”,
5. Le réseau hôte nous permet d’exécuter un conteneur dans l’espace de noms de mise en réseau de l’hôte.
6. N’utilisez ce réseau qu’à des fins de débogage ou lors de la création d’un outil au niveau du système. N’utilisez jamais le réseau hôte pour un conteneur d’applications en cours de production !
7. Le réseau none dit essentiellement que le conteneur n’est attaché à aucun réseau. Il doit être utilisé pour les conteneurs qui n’ont pas besoin de communiquer avec d’autres conteneurs et qui n’ont pas besoin d’être accessibles de l’extérieur.
8. Le réseau none pourrait par exemple être utilisé pour un processus par lots exécuté dans un conteneur qui n’a besoin que d’accéder à des ressources locales telles que des fichiers accessibles via un volume monté sur l’hôte.
Chapitre 8 : Docker Compose
1. Le code suivant peut être utilisé pour exécuter l’application en mode démon.
$ docker-compose up -d
2. Exécutez la commande suivante pour afficher les détails du service en cours d’exécution.
$ docker-compose ps
Cela devrait entraîner la sortie suivante :
Name Command State Ports
mycontent_nginx_1 nginx -g daemon off; Up 0.0.0.0:3000>80/tcp
3. La commande suivante peut être utilisée pour mettre à l’échelle le service Web :
$ docker-compose up –scale web=3
Chapitre 9: Orchestrateurs
Voici les exemples de réponses aux questions de ce chapitre :
1. Voici quelques raisons pour lesquelles nous avons besoin d’un moteur d’orchestration :
- Les conteneurs sont éphémères et seul un système automatisé (l’orchestrateur) peut gérer cela efficacement.
- Pour des raisons de haute disponibilité, nous voulons exécuter plusieurs instances de chaque conteneur. Le nombre de conteneurs à gérer devient rapidement énorme.
- Pour répondre à la demande d’Internet d’aujourd’hui, nous devons rapidement augmenter et diminuer.
- Les conteneurs, contrairement aux VM, ne sont pas traités comme des animaux de compagnie et fixés ou guéris lorsqu’ils se comportent mal, mais sont traités comme des bovins. Si quelqu’un se comporte mal, nous le tuons et le remplaçons par une nouvelle instance. L’orchestrateur met rapidement fin à un conteneur défectueux et planifie une nouvelle instance.
2. Voici quelques responsabilités d’un moteur d’orchestration de conteneurs :
- Gère un ensemble de nœuds dans un cluster
- Planifie la charge de travail sur les nœuds avec suffisamment de ressources libres
- Surveille la santé des nœuds et la charge de travail
- Réconcilie l’état actuel avec l’état souhaité des applications et des composants
- Fournit la découverte et le routage des services
- Demandes d’équilibrage de charge
- Sécurise les données confidentielles en fournissant un support pour les secrets
3. Voici une liste (incomplète) d’orchestrateurs, classés par ordre de popularité :
- Kubernetes by Google, reversé à la CNCF
- SwarmKit by Docker, c’est-à-dire le système de support des opérations (OSS)
- AWS ECS par Amazon
- Azure AKS par Microsoft
- Mesos par Apache, c’est-à-dire OSS
- Bovins par Rancher
- Nomad par HashiCorp
Chapitre 10: Orchestrer des applications conteneurisées avec Kubernetes
1. Le maître Kubernetes est responsable de la gestion du cluster. Toutes les demandes de création d’objets, la planification des pods, la gestion des ReplicaSets , etc. se produisent sur le maître. Le maître n’exécute pas la charge de travail d’application dans un cluster de production ou de type production.
2. Sur chaque nœud de travail, nous avons le kubelet, le proxy et un runtime de conteneur.
3. La réponse est oui. Vous ne pouvez pas exécuter de conteneurs autonomes sur un cluster Kubernetes. Les pods sont l’unité atomique de déploiement dans un tel cluster.
4. Tous les conteneurs exécutés à l’intérieur d’un pod partagent le même espace de noms de réseau du noyau Linux. Ainsi, tous les processus s’exécutant à l’intérieur de ces conteneurs peuvent communiquer entre eux via localhost de la même manière que les processus ou applications s’exécutant directement sur l’hôte peuvent communiquer entre eux via localhost.
5. Le seul rôle du conteneur de pause est de réserver les espaces de noms du pod pour les conteneurs qui s’exécutent dans le pod.
6. C’est une mauvaise idée car tous les conteneurs d’un pod sont colocalisés, ce qui signifie qu’ils s’exécutent sur le même nœud de cluster. Mais les différents composants de l’application (c’est-à-dire le Web, l’inventaire et la base de données) ont généralement des exigences très différentes en termes d’évolutivité ou de consommation de ressources. Le composant Web peut avoir besoin d’être mis à l’échelle vers le haut et vers le bas en fonction du trafic et le composant db à son tour a des exigences spéciales sur le stockage que les autres n’ont pas. Si nous exécutons chaque composant dans son propre module, nous sommes beaucoup plus flexibles à cet égard.
7. Nous avons besoin d’un mécanisme pour exécuter plusieurs instances d’un pod dans un cluster et nous assurer que le nombre réel de pods en cours d’exécution correspond toujours au nombre souhaité, même lorsque des pods individuels se bloquent ou disparaissent en raison de défaillances de partition réseau ou de nœud de cluster. Le ReplicaSet est ce mécanisme qui fournit l’évolutivité et l’auto-réparation à n’importe quel service d’application.
8. Nous avons besoin d’objets de déploiement chaque fois que nous voulons mettre à jour un service d’application dans un cluster Kubernetes sans provoquer d’arrêt du service. Les objets de déploiement ajoutent des fonctionnalités de mise à jour et de restauration continues aux ReplicaSets.
9. Les objets de service Kubernetes sont utilisés pour faire participer les services d’application à la découverte de service. Ils fournissent un point de terminaison stable à un ensemble de pods (normalement régi par un ReplicaSet ou un déploiement). Les services Kube sont des abstractions qui définissent un ensemble logique de modules et une politique sur la façon d’y accéder. Il existe quatre types de services Kube :
- ClusterIP: expose le service sur une adresse IP accessible uniquement depuis l’intérieur du cluster; c’est une IP virtuelle (VIP)
- NodePort: publie un port compris entre 30 000 et 32 767 sur chaque nœud de cluster
- LoadBalancer: ce type expose le service d’application en externe à l’aide de l’équilibreur de charge d’un fournisseur de cloud tel que ELB sur AWS
- ExternalName: utilisé lorsque vous devez définir un proxy pour un service externe de cluster tel qu’une base de données
Chapitre 11: Déploiement, mise à jour et sécurisation d’une application avec Kubernetes
1. En supposant que nous ayons une image Docker dans un registre pour les deux services d’application, l’API Web et Mongo DB, nous devons alors procéder comme suit :
- Définir un déploiement pour Mongo DB à l’aide d’un StatefulSet ; appelons ce déploiement db-deployment . Le StatefulSet devrait avoir une réplique (la réplication de Mongo DB est un peu plus complexe et n’entre pas dans le cadre de cet article).
- Définissez un service Kubernetes appelé db de type ClusterIP pour le dbdeployment.
- Définir un déploiement pour l’API Web ; appelons cela le déploiement Web. Modifions ce service à trois instances.
- Définissez un service Kubernetes appelé api de type NodePort pour le déploiement Web.
- Si nous utilisons des secrets, définissez ces secrets directement dans le cluster à l’aide de kubectl.
- Déployez l’application à l’aide de kubectl.
2. Pour implémenter le routage de couche 7 pour une application, nous utilisons idéalement un IngressController . Le IngressController est un proxy inverse tel que Nginx qui a une écoute sidecar sur l’API Kubernetes Server pour la mise à jour des changements pertinents et la configuration du proxy inverse et le redémarrer, si un tel changement a été détecté. Nous devons ensuite définir les ressources Ingress dans le cluster qui définissent le routage, par exemple à partir d’une route contextuelle telle que https://example.com/pets vers une paire <a service name> / <port> telle que api / 32001. Au moment où Kubernetes crée ou modifie cet objet Ingress, le side-car d’IngressController le récupère et met à jour la configuration de routage du proxy.
3. En supposant qu’il s’agit d’un service d’inventaire interne de cluster :
- Lors du déploiement de la version 1.0, nous définissons un déploiement appelé inventaire-déploiement-bleu et étiquetons les pods avec une couleur d’étiquette : bleu.
- Nous déployons le service Kubernetes de type ClusterIP appelé inventaire pour le déploiement précédent avec le sélecteur contenant la couleur : bleu.
- Lorsque vous êtes prêt à déployer la nouvelle version du service de paiement, nous définissons d’abord un déploiement pour la version 2.0 du service et l’appelons l’inventaire-déploiement-vert. Nous ajoutons une couleur d’étiquette : verte aux dosettes.
- Nous pouvons maintenant tester la fumée du service “vert” et quand tout va bien, nous pouvons mettre à jour le service d’inventaire tel que le sélecteur contient la couleur : vert.
4. Certains types d’informations qui sont confidentielles et doivent donc être fournies aux services via les secrets Kubernetes comprennent : les mots de passe, les certificats, les ID de clé API, les secrets de clé API ou les jetons.
5. Les sources des valeurs secrètes peuvent être des fichiers ou des valeurs codées en base 64.
Chapitre 12: Exécution d’une application conteneurisée dans le cloud
1. Vous pouvez utiliser l’interface utilisateur graphique du portail Azure, la CLI Azure ou les modèles de ressources Azure combinés avec un outil tel que Terraform pour provisionner un cluster entièrement hébergé sur AKS.
2. Voici quelques raisons pour lesquelles il est judicieux d’utiliser le Registre de conteneurs Azure pour stocker des images :
- Pour éviter une latence élevée lors du déploiement d’images dans un système de production, il est important de les stocker dans un registre de conteneurs proche du cluster Kubernetes où les conteneurs créés à partir des images seront exécutés.
- Pour des raisons de sécurité, il est possible que les hôtes du cluster Kubernetes n’atteignent pas le réseau Azure pour télécharger des images à partir d’un registre de conteneurs externe tel que Docker Hub. L’ACR peut être dans le même réseau (interne) que le cluster Kubernetes.
- La bande passante utilisée pour télécharger des images de conteneur est moins chère si elle se trouve à l’intérieur du même centre de données que lors de l’utilisation de liaisons de données externes.
- Si nous voulons nous concentrer sur un seul fournisseur et ne pas traiter avec plusieurs fournisseurs.
3. Pour exécuter une application conteneurisée dans AKS, nous devons :
- Provisionner un cluster Kubernetes entièrement géré sur AKS
- Construisez et envoyez les images du conteneur vers l’ACR
- Utilisez kubectl pour déployer l’application dans le cluster
4. Une façon d’afficher les journaux de conteneur ou les journaux de kubelet de n’importe quel nœud de travail consiste à SSH dans ce nœud. Nous le faisons en exécutant un conteneur spécial sur ledit hôte à partir duquel nous établirons la connexion SSH à l’hôte. Nous pouvons ensuite utiliser un outil tel que journalctl pour analyser les journaux système, ou simplement exécuter des commandes docker normales sur l’hôte pour récupérer les journaux du conteneur.
5. Nous pouvons utiliser la CLI Azure pour augmenter ou diminuer le nombre de nœuds de travail. La commande pour ce faire est :
az aks scale –resource-group=<group-name> –name=<cluster-name> –node-count <num-nodes>


Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.