Résumé de la publication
Docker est une plate-forme de conteneur de niveau entreprise qui vous permet de créer et de déployer vos applications. Son format portable vous permet d’exécuter votre code directement depuis vos postes de travail vers les fournisseurs de cloud computing populaires. Ce guide complet améliorera vos flux de travail Docker et garantira le bon fonctionnement de l’environnement de production de votre application.
Cet article commence par un rappel sur la configuration et l’exécution de Docker et détaille la configuration de base pour la création d’un cluster Docker Swarm. Vous apprendrez ensuite à automatiser ce cluster en utilisant Chef Server et Cookbook. Après cela, vous exécuterez le système de surveillance Docker avec Prometheus et Grafana et déploierez la pile ELK. Vous apprendrez également quelques conseils pour optimiser les images Docker.
Après avoir déployé des conteneurs à l’aide de Jenkins, vous passerez ensuite à un didacticiel sur l’utilisation d’Apache JMeter pour analyser les performances de votre application. Vous apprendrez comment utiliser Docker Swarm et NGINX pour équilibrer la charge de votre application et comment les outils de débogage courants sous Linux peuvent être utilisés pour dépanner les conteneurs Docker.
À la fin de cet article, vous pourrez intégrer toutes les optimisations que vous avez apprises et tout mettre en pratique dans vos applications.
Objectifs de la publication
- Automatisez le provisionnement et la configuration des nœuds dans un cluster Docker Swarm
- Configurer un système de surveillance avec Prometheus et Grafana
- Utilisez Apache JMeter pour créer des charges de travail pour comparer les performances des conteneurs Docker
- Comprendre comment équilibrer la charge d’une application avec Docker Swarm et Nginx
- Déployer strace, tcdump, blktrace et d’autres outils de débogage Linux pour dépanner les conteneurs
- Intégrez les optimisations Docker pour DevOps, Site Reliability Engineering, CI et CD
Préparation des hôtes Docker
Docker nous permet de fournir des applications à nos clients plus rapidement. Il simplifie les flux de travail nécessaires pour obtenir le code du développement à la production en étant capable de créer et de lancer facilement des conteneurs Docker. Ce chapitre sera un rappel rapide sur la façon de préparer notre environnement à exécuter le flux de travail de développement et d’opérations basé sur Docker en procédant comme suit :
- Préparation d’un hôte Docker
- Activation de l’accès à distance aux hôtes Docker
- Création d’un cluster Docker Swarm
La plupart des parties de ce chapitre sont des concepts que nous connaissons déjà et qui sont facilement disponibles sur le site Web de documentation Docker. Ce chapitre présente les commandes sélectionnées et les interactions avec l’hôte Docker qui seront utilisées dans les chapitres suivants.
Préparation d’un hôte Docker
On suppose que nous savons déjà comment configurer un hôte Docker. Pour la plupart des chapitres de cet article, nous fonctionnerons contre l’environnement suivant, sauf mention explicite :
- Système d’exploitation : CentOS 7.5
- Version Docker : 18.09.0
Les commandes suivantes affichent le système d’exploitation et la version du moteur Docker exécutés dans notre hôte Docker :
$ ssh dockerhost
dockerhost$ lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 7.5.1804 (Core)
Release: 7.5.1804
Codename: Core
dockerhost$ docker version
Version: 18.09.0
API version: 1.39
Go version:go1.10.4
Git commit:4d60db4
Built: Wed Nov 7 00:48:22 2018
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine – Community
Engine:
Version: 18.09.0
API version: 1.39 (minimum version 1.12)
Go version: go1.10.4
Git commit: 4d60db4
Built: Wed Nov 7 00:19:08 2018
OS/Arch: linux/amd64
Experimental: false
Si nous n’avons pas configuré notre environnement Docker, nous pouvons suivre les instructions du site Web Docker disponible sur https://docs.docker.com/install/linux/docker-ce/centos/ pour préparer notre hôte Docker.
Activation de l’accès à distance
Au lieu de vous connecter à distance à notre hôte Docker pour exécuter des conteneurs, nous accéderons à l’hôte Docker en activant l’API distante dans Docker Engine. Cela nous permet de gérer nos conteneurs Docker à partir de notre poste de travail client ou serveur de livraison continue. Nous interagirons ensuite avec notre hôte Docker pour représenter notre environnement de production. L’API distante sera ensuite utilisée à partir de notre poste de travail client pour effectuer des déploiements de nos conteneurs Docker.
Cette section couvrira les étapes pour sécuriser et activer l’accès à distance à notre hôte Docker :
- Configuration d’une autorité de certification
- Reconfiguration de Docker Engine pour permettre l’accès à distance
- Configuration du client Docker pour l’accès à distance
Configuration d’une autorité de certification
Pour le reste de cette section, nous allons installer des certificats TLS sur notre serveur hôte et client Docker. Pour assurer une communication fiable entre le serveur et le client, nous allons mettre en place une infrastructure à clé publique (PKI). Cela permettra au moteur Docker en cours d’exécution sur notre hôte et à notre client Docker d’établir la connexion pour vérifier l’identité l’un de l’autre.
La première étape de la création de l’ICP consiste à configurer l’autorité de certification (CA). Une autorité de certification est un tiers de confiance qui délivre des certificats numériques aux membres de notre infrastructure à clé publique, à savoir notre hôte et client Docker.
Dans les prochaines étapes, nous allons configurer notre autorité de certification à l’intérieur de notre poste de travail client :
1. Tout d’abord, nous allons créer un répertoire pour notre PKI et générer la clé privée de l’autorité de certification dans un fichier appelé ca-key.pem :
client$ mkdir ~/ca
client$ cd ~/ca
client$ openssl genrsa -aes256 -out ca-key.pem 4096
Generating RSA private key, 4096 bit long modulus
………………………………..++
…………………………………………++
e is 65537 (0x10001)
Enter pass phrase for ca-key.pem: ****
Verifying — Enter pass phrase for ca-key.pem: ****
Nous devons nous souvenir des mots de passe définis pour la clé privée de notre autorité de certification, car nous en aurons toujours besoin pour le reste de ce chapitre.
2. Ensuite, nous nous assurons que cette clé privée est sécurisée en nous restreignant l’accès en lecture et en écriture :
client$ chmod 600 ca-key.pem
client$ ls -l ca-key.pem
-rw——-. 1 dockeruser group 3326 Dec 2 20:45 ca-key.pem
3. Enfin, nous allons générer un certificat auto-signé pour notre autorité de certification. Laissez ‘ s tapez la commande suivante pour placer le certificat auto-signé dans un fichier appelé ca.pem :
client$ openssl req -key ca-key.pem -new -x509 \
-subj ‘/CN=Certificate Authority’ \
-sha256 -days 365 -out ca.pem
Enter pass phrase for ca-key.pem: ****
Nous avons maintenant une autorité de certification et nous distribuerons son certificat ca.pem à notre hôte et client Docker plus tard dans cette section. Pour l’instant, « inspectent s le certificat génèrent :
client$ cat ca.pem
—–BEGIN CERTIFICATE—–
MIIFEzCCAvugAwIBAgIJAM19ce5sap+kMA0GCSqGSIb3DQEBCwUAMCAxHjAcBgNV
BAMMFUNlcnRpZmljYXRlIEF1dGhvcml0eTAeFw0xODEyMDYwMzQ5MTNaFw0xOTEy
MDYwMzQ5MTNaMCAxHjAcBgNVBAMMFUNlcnRpZmljYXRlIEF1dGhvcml0eTCCAiIw
DQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAKCESs7QpRZ78v8p2nKomCGABqCN
b3E0vBpjveTnjA4kOEWVsHloq2o66yuuNff75GNWghzq791KyKJOy/dehNL9DauA
DD3DJh0+uaOGn547W827Z37wJ64acNyvIQjyiyeLrpF4BzzxaZ/AJFVgqar5Kuqc
qiOG3GUYcnfu6mpmlKoa1XqBtSQ+A2fd4/mpXC0zrDrz9MSEOCs5/Xm6/faexYae
V8gBkCYWiUVUi+RRRc2vU1LzuiI5FsXmD3kNHCjNIbYIoyqKMzbTJjEffhN+5B/V
Rc3qfRmfoEv8P0Hc4Wx55qH8BLWwhvNFAZ+nre+j7zPz+dTfLVyveOPxErHaI1V8
WH9qEVf+haNqUBrjNCuL+xyVNx7evPygD88jyZDWLK5Y0JTh2GSPqMeVi3hSKzNP
GbVjT8tmkCUEsYbSJg2vkPYJR4aC8LLdJsjr7wkWBF1IcYYZpLo3EsUnkjNi7MGS
pGdLob3UtoekXaA1D6esDhlEB+3Tt/RWJkS91ijUiDs2kTSmDfnxUQGyeD4wx/rj
lPFRSLdUUYiFcdI5VegZVSqYxW/Qw2/t+GvoLkrOrggqY1f++XugK5hSoT8EqgiG
SjapkgphMEquVP8UlZ3jC0VmgwFnRUEdqau6yLWMYG6TvLkyVi1Vmfam7CoB1aDn
TccUszk+rezX+1nJAgMBAAGjUDBOMB0GA1UdDgQWBBTrqfPKO0i2peZ6Hd/BYOMq
WXD9kDAfBgNVHSMEGDAWgBTrqfPKO0i2peZ6Hd/BYOMqWXD9kDAMBgNVHRMEBTAD
AQH/MA0GCSqGSIb3DQEBCwUAA4ICAQCa6SPGncEZSWu0WLfkh1mERa9JfBQzJFpv
1E7M3tZeFyJS7LfXdcf9WEAaWqTpha87A+5g9uBi/whYk47dyTik07/k+CyF112i
9GXK8j/UNCjAMOSluOCxpIsmMXp2Dn+ma21msN1K/lHK0ZhGWB9ZDggvdzRRPjic
Dq3aQ49ATHQHGg9cqgZO0zXtcQYaHfCNds5YLNVL66eDhuN91V2MEqWtRDHfr0vA
F3KldXfQ/clnrjGLqo7a3oR1R4QofQ03bV+PRIgub+l3Fee1D68BqF9dLRjUABd2
zm5OzNAmmHPSGWGvOxylvPrUS0ulUzMUWdoXN85SDdLHFXTXwpbD/GgqK+Y3BtgO
7d+mOoTHVEdw2gUXLaqeEchBge2Kh/LqtiN7Zp8OY7snX66Z8tF6W2MKhnSpDzcW
J4WmbmaRqsTEeaRk0aTWkhBZukSZf4zjaa/abF+iRvU5c1OGS9GmYfuGq3Tlj+Xo
JZNuKp9HzOPaj8qiD0DJW9EnuZ24zzpDSiSdmOdARcaaFFKhW8i+SVP6VqrAR3Nb
OL8ne6w6kdoiq4+hPKfWVS9Yh0aQstJMNP91Nnw3J+aRz9eN03jpl/z18vHhW/xl
nYJrB2KlC7SonUT7TMJr4O5Aw1SidxMH6NliiC1jbTWXDMuYL8UghDIk9Ne/WhBd
qg0sW+boLw==
—–END CERTIFICATE—–
Activation de l’accès à distance dans Docker Engine
Maintenant que nous avons une autorité de certification pour notre infrastructure à clé publique, nous pouvons l’utiliser pour vérifier l’identité de notre hôte Docker. Les étapes suivantes prépareront l’identité de notre hôte Docker :
1. Tout d’abord, nous nous connectons à notre hôte Docker. Ici, nous générerons une clé privée qui sécurisera l’API distante servie en exécutant Docker Engine. La commande suivante enregistrera la clé privée dans un fichier appelé /etc/docker/server-key.pem :
dockerhost$ openssl genrsa -out /etc/docker/server-key.pem 2048
Generating RSA private key, 2048 bit long modulus
…………………………..+++
……..+++
e is 65537 (0x10001)
2. Ensuite, nous nous assurons que ce fichier est sécurisé et accessible uniquement par le démon Docker Engine (via l’utilisateur root):
dockerhost$ chmod 600 /etc/docker/server-key.pem
dockerhost$ ls -l /etc/docker/server-key.pem
-rw——-. 1 root root 1675 Dec 2 21:09 /etc/docker/server-key.pem
3. Maintenant que la clé privée est prête, nous allons utiliser ce fichier pour générer une demande de signature de certificat (CSR). La commande suivante openssl req générera une CSR:
dockerhost$ openssl req -key /etc/docker/server-key.pem
-new -subj “/CN=dockerhost” -sha256 -out
dockerhost.csr
dockerhost$ ls -l dockerhost.csr
-rw-r—r–. 1 root root 891 Dec 2 21:33 dockerhost.csr
4. Ensuite, nous revenons à notre poste de travail client où les fichiers de notre autorité de certification sont hébergés. Ici, nous téléchargerons la CSR à partir de notre hôte Docker :
client$ scp dockerhost:~/dockerhost.csr dockerhost.csr
dockerhost.csr 100% 891 1.5MB/s 00 :00
5. Nous préparons maintenant un fichier de configuration OpenSSL server-ext.cnf qui indique que les certificats que notre autorité de certification délivrera sont utilisés pour l’authentification du serveur:
extendedKeyUsage = serverAuth
6. Enfin, nous pouvons signer le CSR avec notre CA. La commande suivante placera notre hôte Docker ‘ certificat signé dans un fichier appelé dockerhost.pem :
client$ cd ~/ca
client$ openssl x509 -req -CA ca.pem -Cakey ca-key.pem \
-Cacreateserial -extfile server-ext.cnf \
-in dockerhost.csr -out dockerhost.pem
Signature ok
subject=/CN=dockerhost
Getting CA Private Key
Enter pass phrase for ca-key.pem: ****
Maintenant que l’identité de notre hôte Docker est vérifiée par notre autorité de certification, nous pouvons maintenant activer le port TCP sécurisé dans notre hôte Docker. Nous allons afficher l’API distante sécurisée avec les étapes suivantes :
- Maintenant revenir dans notre hôte Docker. Ici, nous allons copier les certificats de notre hôte Docker et de notre autorité de certification depuis notre poste de travail client:
dockerhost$ scp client:~/ca/ca.pem /etc/docker/ca.pem
ca.pem 100% 1911 1.1MB/s 00:00
dockerhost$ scp client:~/ca/dockerhost.pem /etc/docker/server.pem
dockerhost.pem 100% 1428 1.2MB/s 00 :00
2. Maintenant que nos actifs TLS sont en place, laissez ‘ s reconfigurer maintenant le fichier démon Engine Docker, /etc/docker/daemon.json , d’utiliser ces certificats:
{
“tlsverify”: true,
“tlscacert”: “/etc/docker/ca.pem”,
“tlskey”: “/etc/docker/server-key.pem”,
« tlscert » : « /etc/docker/server.pem »
}
3. Ensuite, nous configurons le démon Docker Engine pour écouter un port sécurisé en créant un fichier de remplacement 1 ystem / etc / 1 ystem /system/docker.service.d/override.conf :
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd -H unix:// -H tcp://0.0.0.0:2376
4. Enfin, nous sommes maintenant prêts à redémarrer Docker Engine:
dockerhost$ systemctl daemon-reload
dockerhost$ systemctl restart docker.service
Notre hôte Docker est maintenant prêt et sert une API sécurisée.
Connexion à distance à partir du client Docker
Maintenant que notre hôte Docker est sécurisé, il ne répondra pas encore aux demandes de notre client Docker. L’hôte Docker ne répondra qu’aux demandes des clients vérifiées par notre autorité de certification.
Les étapes suivantes généreront une identité pour notre client Docker :
1. Tout d’abord, laissez ‘ s générer la clé privée de notre client Docker dans ~ / .docker / key.pem :
client$ openssl genrsa -out ~/.docker/key.pem 4096
Generating RSA private key, 4096 bit long modulus
……………….++
…………………………………………………++
e is 65537 (0x10001)
2. Ensuite, nous nous assurons que cette clé privée nous est réservée pour la visualisation :
client$ chmod 600 ~/.docker/key.pem
3. Nous générons maintenant la CSR pour le client dans un fichier appelé client.csr :
client$ openssl req -subj ‘/CN=client’ -new \
-key ~/.docker/key.pem -out client.csr
4. Maintenant que notre CSR est prête, nous allons maintenant créer une configuration OpenSSL pour indiquer que les certificats seront utilisés pour l’authentification du client. La commande OpenSSL suivante crée cette configuration dans un fichier appelé ~ / ca / client-ext.cnf :
extendedKeyUsage = clientAuth
5. Enfin, nous sommes prêts à émettre le certificat pour notre client Docker. La commande suivante écrit le certificat de notre client Docker dans ~ / .docker / cert.pem :
client$ openssl x509 -req -CA ca.pem
-Cakey ca-key.pem -Cacreateserial
-extfile client-ext.cnf -in
~/client.csr -out ~/.docker/cert.pem
Signature ok
subject=/CN=client
Getting CA Private Key
Enter pass phrase for ca-key.pem: ****
6. Enfin, nous indiquons à notre client Docker que nous nous connecterons en toute sécurité à notre hôte Docker distant en exportant les variables d’environnement suivantes :
client$ cp ca.pem ~/.docker/ca.pem
7. Enfin, nous indiquons à notre client Docker que nous nous connecterons en toute sécurité à notre hôte Docker distant en exportant les variables d’environnement suivantes :
client$ export DOCKER_HOST=tcp://dockerhost:2376
client$ export DOCKER_TLS_VERIFY=true
Toutes nos félicitations ! Nous avons maintenant un canal de communication sécurisé entre notre client Docker et l’hôte Docker. Pour vérifier la connexion, nous pouvons exécuter la commande suivante et afficher des informations sur notre hôte Docker distant :
client$ docker info
Création d’un cluster Docker Swarm
Docker a introduit le mode Swarm dans son moteur Docker à partir de la version 1.12.0. Docker Swarm nous permet de regrouper plusieurs hôtes Docker pour déployer nos conteneurs de manière évolutive et à haute disponibilité. Dans cette section, nous allons construire un petit cluster Docker Swarm.
Plongeons dans la construction de notre cluster avec les étapes suivantes :
1. Tout d’abord, nous allons aller sur notre hôte Docker et l’initialiser en tant que gestionnaire. Le gestionnaire est responsable du maintien de l’état de notre cluster Docker Swarm. Il envoie également des tâches aux autres hôtes Docker de notre cluster. Tapons la commande suivante pour commencer l’initialisation :
dockerhost$ docker swarm init
Swarm initialized: current node (w49smc2ciy100gaecgx77yir3)
is now a manager
To add a worker to this swarm, run the following command:
docker swarm join –token SWMTKN-1-4wbs…aq2r \
172.16.132.187:2377
La commande précédente a généré un jeton qui sera utilisé par d’autres hôtes Docker pour rejoindre notre cluster.
2. Ensuite, nous irons à un nouvel hôte Docker appelé node1. Nous utilisons le jeton de l’étape précédente pour que cet hôte Docker rejoigne notre cluster Docker Swarm en tant que travailleur. Les travailleurs sont membres du cluster qui sont responsables de la gestion de nos conteneurs. Tapons maintenant la commande suivante pour que ce nouveau nœud rejoigne notre cluster :
node1$ docker swarm join –token SWMTKN-1-4…aq2r \ 172.16.132.187:2377
This node joined a swarm as a worker.
Nous pouvons étendre notre cluster Docker Swarm en ajoutant plus de gestionnaires et de travailleurs à l’aide de la même commande Docker Swarm join . Plus de détails peuvent être trouvés dans la documentation Docker en amont à https://docs.docker.com/engine/swarm/join-nodes.
Nous avons maintenant terminé la configuration de notre cluster Docker Swarm. Revenons à notre poste de travail client Docker et confirmons les membres de notre cluster :
client$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
w49smc * dockerhost Ready Active Leader 18.09.0
2e0aif node1 Ready Active 18.09.0
Résumé
J’espère qu’à ce stade, nous nous sommes familiarisés avec l’interaction avec Docker Engine. Nous avons préparé un hôte Docker où nous gérerons nos conteneurs. Nous avons construit une PKI pour assurer une communication sécurisée entre notre hôte Docker et notre station de travail client Docker, et nous avons construit un petit cluster Docker Swarm composé de plusieurs hôtes Docker.
Nous avons accompli tout cela en nous connectant aux serveurs et en tapant manuellement les commandes de configuration. Dans le chapitre suivant, nous apprendrons à automatiser le provisionnement de ces hôtes Docker et à nous éviter de taper !
Configuration de Docker avec Chef
Maintenant, nous connaissons déjà les différents aspects de l’écosystème Docker. L’hôte Docker a plusieurs paramètres de configuration. Cependant, la configuration manuelle des hôtes Docker est un processus lent et sujet aux erreurs. Nous aurons des problèmes pour faire évoluer nos déploiements Docker en production si nous n’avons pas de stratégie d’automatisation en place.
Dans ce chapitre, nous apprendrons le concept de gestion de configuration pour résoudre ce problème. Nous utiliserons Chef, un logiciel de gestion de configuration, pour gérer les hôtes Docker à grande échelle. Ce chapitre couvrira les sujets suivants :
- Importance de la gestion de la configuration
- Utilisation de Chef
- Provisionnement des hôtes Docker
- Configuration du mode Docker Swarm
- Outils d’automatisation alternatifs
Importance de la gestion de la configuration
Le moteur Docker a plusieurs paramètres à régler, tels que les groupes de contrôle, la mémoire, le processeur, les systèmes de fichiers, la mise en réseau, etc. L’identification des conteneurs Docker exécutés sur les hôtes Docker est un autre aspect de la configuration. Obtenir la combinaison de paramètres pour optimiser notre application prendra du temps.
La réplication de tous les éléments de configuration précédents vers un autre hôte Docker est difficile à effectuer manuellement. Nous ne nous souvenons peut-être pas de toutes les étapes requises pour créer un hôte, et c’est un processus lent et sujet aux erreurs. La création de documentation pour capturer ce processus n’aide pas non plus, car ces artefacts ont tendance à devenir périmés au fil du temps.
Si nous ne pouvons pas approvisionner de nouveaux hôtes Docker en temps opportun et de manière fiable, nous n’aurons pas d’espace pour étendre notre application Docker. Par conséquent, il est important de préparer et de configurer nos hôtes Docker de manière cohérente et rapide. Sinon, la capacité de Docker à créer des packages de conteneurs pour notre application deviendra rapidement inutile.
La gestion de la configuration est une stratégie pour gérer les changements qui se produisent dans tous les aspects de notre application, et elle rend compte et vérifie les modifications apportées à notre système. Cela ne s’applique pas uniquement lors du développement de notre application. Pour notre cas, il enregistre toutes les modifications apportées à nos hôtes Docker. Docker, dans un sens, accomplit les aspects suivants de la gestion de la configuration de notre application :
- Les conteneurs Docker reproduisent n’importe quel environnement pour notre application, du développement à la préparation, au test et à la production.
- La création d’images Docker est un moyen simple de modifier les applications et de les déployer dans tous les environnements.
- Docker permet à tous les membres de l’équipe d’obtenir des informations sur notre application et d’apporter les modifications nécessaires pour fournir efficacement le logiciel aux clients. En inspectant le Dockerfile , ils peuvent savoir quelle partie de l’application doit être mise à jour et ce dont elle a besoin pour fonctionner correctement.
- Docker suit tout changement dans notre environnement vers une image Docker particulière. Ensuite, il le retrace à la version correspondante du Dockerfile. Il retrace ce qu’est le changement, qui l’a fait et quand il a été fait.
Mais qu’en est-il de l’hôte Docker exécutant notre application ? Tout comme un Dockerfile nous permet de gérer l’environnement de notre application dans le contrôle de version, les outils de gestion de la configuration peuvent décrire nos hôtes Docker en code. Il simplifie le processus de création d’hôtes Docker. Dans le cas de l’extension de notre application Docker, nous pouvons recréer un nouvel hôte Docker à partir de zéro facilement. En cas de panne matérielle, nous pouvons faire apparaître de nouveaux hôtes Docker ailleurs dans leur configuration connue. La gestion de la configuration nous permet de gérer nos déploiements Docker à grande échelle.
Dans la section suivante, nous allons configurer Chef comme système de gestion de configuration pour notre infrastructure Docker.
Utilisation de Chef
Chef est un outil de gestion de configuration qui fournit un langage spécifique au domaine pour modéliser la configuration de notre infrastructure. Chaque élément de configuration de notre infrastructure est modélisé comme une ressource. Une ressource est essentiellement une méthode Ruby qui accepte plusieurs paramètres dans un bloc. L’exemple de ressource suivant décrit l’installation du package docker-engine :
package ‘docker-engine’ do
action :install
end
Ces ressources sont ensuite écrites ensemble dans des fichiers source Ruby appelés recettes. Lors de l’exécution d’une recette sur un serveur (un hôte Docker dans notre cas), toutes les ressources définies sont exécutées pour atteindre la configuration d’état souhaitée.
Certaines recettes Chef peuvent dépendre d’autres éléments supplémentaires, tels que les modèles de configuration et d’autres recettes. Toutes ces informations sont rassemblées dans les cookbook avec les recettes. Un cookbook est une unité fondamentale pour distribuer la configuration et la politique à nos serveurs.
Nous allons écrire des recettes Chef pour représenter la configuration d’état souhaitée de nos hôtes Docker. Nos recettes seront organisées dans des cookbook Chef pour les diffuser dans notre infrastructure. Cependant, tout d’abord, préparons notre environnement Chef afin de pouvoir commencer à décrire notre infrastructure Docker dans des recettes. Un environnement Chef comprend trois éléments :
- Un serveur Chef
- Un poste de travail
- Un nœud
Les prochaines sous-sections vous donneront une description détaillée de chaque composant. Ensuite, nous les configurerons pour préparer notre environnement Chef afin de pouvoir gérer notre hôte Docker.
Il y a plus de détails sur la configuration d’un environnement Chef qui sortent du cadre de ce chapitre. Plus d’informations peuvent être trouvées sur le site Web de documentation de Chef à http://docs.chef.io .
Inscription à un serveur Chef
Le serveur Chef est le référentiel central des cookbook et d’autres éléments de politique régissant l’ensemble de notre infrastructure. Il contient des métadonnées sur l’infrastructure que nous gérons. Dans notre cas, le serveur Chef contient le cookbook, la politique et les métadonnées sur notre hôte Docker.
Pour préparer un serveur Chef, nous allons simplement nous inscrire à un serveur Chef hébergé. Un compte de serveur Chef gratuit nous permet de gérer jusqu’à cinq nœuds dans notre infrastructure. Suivez les étapes suivantes pour préparer un compte de serveur Chef hébergé :
1. Accédez à https://manage.chef.io/signup et remplissez le formulaire pour les détails de notre compte, comme indiqué dans la capture d’écran suivante :
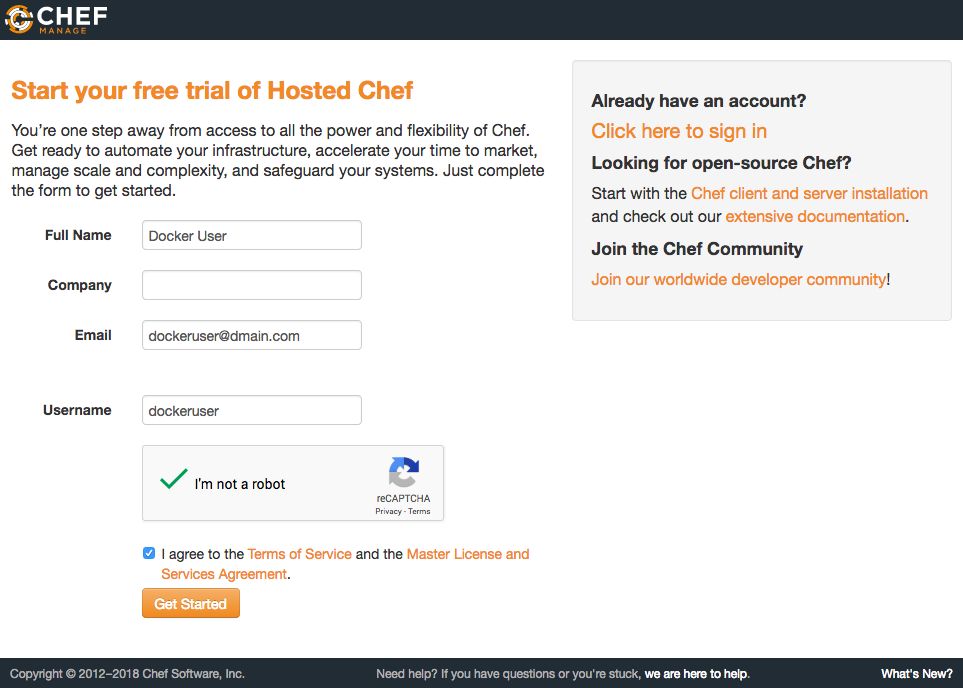
2. Après avoir créé un compte utilisateur, le serveur Chef hébergé va maintenant nous inviter à créer une organisation. Les organisations sont simplement utilisées pour gérer le contrôle d’accès basé sur les rôles pour notre serveur Chef. Créez une organisation en fournissant les détails sur le formulaire et cliquez sur le bouton Créer une organisation.
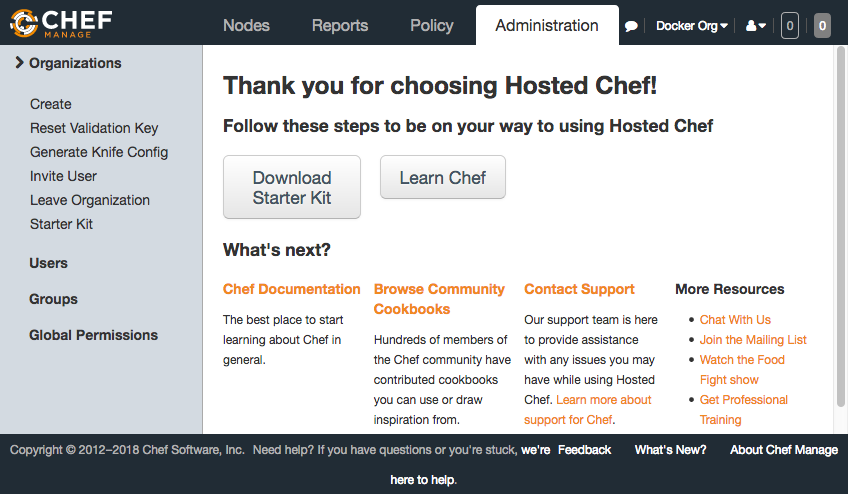
3. Nous avons maintenant presque terminé d’obtenir notre compte de serveur Chef hébergé. Enfin, cliquez sur Télécharger le kit de démarrage. Cela va télécharger un fichier ZIP contenant notre chef-repo de démarrage. Nous parlerons plus du chef-repo dans la section suivante :
Configuration de notre poste de travail
La deuxième partie de notre environnement Chef est le poste de travail. Le poste de travail est utilisé pour interagir avec le serveur Chef. C’est là que nous ferons la plupart du travail de préparation et créerons le code à envoyer au serveur Chef. Dans notre poste de travail, nous préparerons les éléments de configuration de notre infrastructure dans un référentiel Chef.
Le référentiel Chef contient toutes les informations nécessaires pour interagir et se synchroniser avec le serveur Chef. Il contient la clé privée et les autres fichiers de configuration nécessaires pour s’authentifier et interagir avec le serveur Chef. Ces fichiers se trouvent dans le répertoire chef de notre référentiel Chef. Il contient également les cookbook que nous écrirons et synchroniserons plus tard avec le serveur Chef dans le répertoire cookbook / . Il existe d’autres fichiers et répertoires dans un référentiel Chef, tels que des sacs de données, des rôles et des environnements. Cependant, il suffit, pour l’instant, de connaître les cookbook et les fichiers d’authentification pour pouvoir configurer notre hôte Docker.
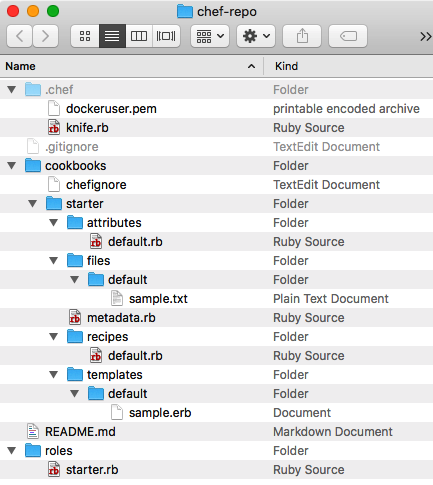
Vous souvenez-vous du kit de démarrage que nous avons téléchargé dans la section précédente ? Vous devez décompresser ce fichier pour extraire notre chef-repo. Nous devrions avoir les fichiers suivants décrits dans l’arborescence des répertoires :
Un autre composant important de notre poste de travail est le Kit de développement Chef. Il contient tous les programmes nécessaires pour lire toute la configuration de notre chef-repo et interagir avec le serveur Chef. Des programmes pratiques pour créer, développer et tester nos cookbook sont également disponibles dans le Kit de développement Chef. Nous utiliserons divers programmes dans le kit de développement tout au long de ce chapitre.
Maintenant, téléchargeons le Kit de développement Chef à partir de https://downloads.chef.io/chefdk selon la plate-forme de notre station de travail.
Ensuite, ouvrez le programme d’installation téléchargé. Installez le Kit de développement Chef selon les invites de notre plateforme. Enfin, confirmez que l’installation a réussi avec la commande suivante :
$ chef -v
Chef Development Kit Version: 3.5.13
chef-client version: 14.7.17
delivery version: master (6862f27aba89109a9630f0b6c6798efec56b4efe)
berks version: 7.0.6
kitchen version: 1.23.2
inspec version: 3.0.52
Maintenant que nous avons configuré notre poste de travail, allons dans notre répertoire chef-repo / pour préparer le dernier composant de notre environnement Chef.
Nœuds d’amorçage
La dernière partie de notre environnement Chef est constituée des nœuds. Un nœud est un ordinateur géré par Chef. Il peut s’agir d’une machine physique, d’une machine virtuelle, d’un serveur dans le cloud ou d’un périphérique réseau. Dans notre cas, notre hôte Docker est un nœud. Dans les prochaines étapes, nous allons configurer les hôtes Docker suivants :
- dockerhost : servira de Docker Swarm Manager
- node1 : se connectera en tant que nœud Docker Swarm à notre cluster
Le composant central de tout nœud à gérer par Chef est le chef-client. Il se connecte au serveur Chef pour télécharger les fichiers nécessaires pour amener notre nœud à son état de configuration. Lorsqu’un chef-client est exécuté sur notre nœud, il effectue les étapes suivantes :
- Il enregistre et authentifie le nœud avec le serveur Chef
- Il rassemble des informations système dans notre nœud pour créer un objet nœud
- Ensuite, il synchronise les cookbook Chef nécessaires à notre nœud
- Il compile les ressources en chargeant les recettes nécessaires de notre nœud
- Ensuite, il exécute toutes les ressources et effectue les actions correspondantes pour configurer notre nœud
- Enfin, il signale le résultat de l’exécution du client-chef sur le serveur Chef et d’autres points de terminaison de notification configurés.
Maintenant, préparons notre hôte Docker en tant que nœud en l’amorçant à partir de notre poste de travail. Le processus d’amorçage se connectera à notre nœud et installera le chef-client. Exécutez la commande suivante pour démarrer ce processus d’amorçage :
$ cd ~/chef-repo
$ knife bootstrap dockerhost -N dockerhost
Creating new client for dockerhost
Creating new node for dockerhost
Connecting to dockerhost
dockerhost —–> Installing Chef Omnibus (-v 14)
…
dockerhost Installing chef 14
dockerhost installing with rpm…
dockerhost warning: /tmp/install.sh.24627/chef-14.7.17-1.el7.x86_64.rpm: Header V4 DSA/SHA1 Signature, key ID 83ef826a: NOKEY
dockerhost Preparing… ################################# [100%]
dockerhost Updating / installing…
dockerhost 1:chef-14.7.17-1.el7 ################################# [100%]
dockerhost Thank you for installing Chef!
dockerhost Starting the first Chef Client run…
dockerhost Starting Chef Client, version 14.7.17
dockerhost resolving cookbooks for run list: []
dockerhost Synchronizing Cookbooks:
dockerhost Installing Cookbook Gems:
dockerhost Compiling Cookbooks…
dockerhost [2018-12-09T03:18:19+00:00] WARN: Node dockerhost has an empty run list.
dockerhost Converging 0 resources
dockerhost
dockerhost Running handlers:
dockerhost Running handlers complete
dockerhost Chef Client finished, 0/0 resources updated in 03 seconds
Comme nous pouvons le constater dans la commande précédente, le processus d’amorçage a fait deux choses. Tout d’abord, il a installé et configuré le chef-client sur notre nœud hôte Docker. Ensuite, il a démarré le chef-client pour synchroniser son état souhaité avec notre serveur Chef. Comme nous n’avons pas encore attribué d’état conçu à notre hôte Docker, cela n’a rien fait.
Enfin, fournissons le reste de nos hôtes Docker :
$ knife bootstrap node1 -N node1
Nous pouvons personnaliser ce processus d’amorçage selon nos besoins. Pour plus d’informations sur l’utilisation du bootstrap au couteau, rendez -vous sur http://docs.chef.io/knife_bootstrap.html. Dans certains cas, les fournisseurs de cloud ont déjà une intégration profonde de Chef. Donc, au lieu du bootstrap au couteau, nous allons simplement utiliser le SDK du fournisseur de cloud. Là, il suffit de préciser que nous voulons intégrer Chef. Nous lui fournirons les informations, telles que la configuration client.rb du chef-client et les informations d’identification des clés de validation.
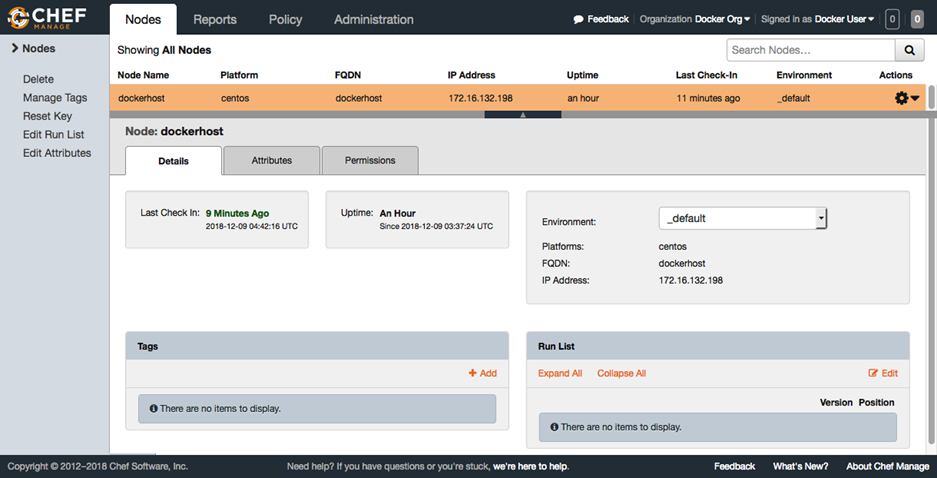
Notre hôte Docker est désormais correctement enregistré sur le serveur Chef, prêt à saisir sa configuration. Accédez à https://manage.chef.io/organizations/dockerorg/nodes/dockerhost pour vérifier notre hôte Docker en tant que nœud dans notre environnement Chef, comme indiqué dans la capture d’écran suivante :
Dans la section suivante, nous allons spécifier la configuration de nos hôtes Docker avec Chef.
Configuration de l’hôte Docker
Maintenant que tous les composants de notre environnement Chef sont correctement configurés, nous pouvons commencer à écrire des recettes Chef pour décrire réellement la configuration que nos hôtes Docker devraient avoir. De plus, nous dépasserons notre productivité en tirant parti des cookbook Chef existants dans l’écosystème Chef. Comme Docker est une pile d’infrastructure populaire à déployer, nous pouvons utiliser des cookbook à l’état sauvage qui nous permettent de configurer nos hôtes Docker. Les cookbook du chef fournis par la communauté se trouvent dans le supermarché Chef. Nous pouvons aller sur http://supermarket.chef.io pour découvrir d’autres cookbook que nous pouvons facilement utiliser.
Dans cette section, nous apprendrons à écrire des recettes Chef et à les appliquer à notre nœud.
Rédaction de recettes de chef
Les prochaines étapes nous montrent comment écrire la recette du chef pour notre hôte Docker:
1. Utilisons la commande chef générer du cookbook du kit de développement Chef pour générer un passe-partout pour notre cookbook. Après être entré dans le répertoire des cookbook, exécutez la commande suivante :
$ cd cookbooks
$ chef generate cookbook dockerhost
Generating cookbook dockerhost
– Ensuring correct cookbook file content
– Ensuring delivery configuration
– Ensuring correct delivery build cookbook content
Your cookbook is ready. Type `cd dockerhost` to enter it.
There are several commands you can run to get started locally
developing and testing your cookbook.
Type `delivery local –help` to see a full list.
Why not start by writing a test? Tests for the default recipe are stored at:
test/integration/default/default_test.rb
If you’d prefer to dive right in, the default recipe can be found at:
recipes/default.rb
La structure du répertoire du cookbook passe-partout ressemblera à la capture d’écran suivante :
2. Ensuite, nous nous préparerons à éditer notre cookbook. Remplacez notre répertoire de travail par le cookbook que nous avons créé précédemment à l’aide de la commande suivante :
$ cd dockerhost
3. Installez le cookbook docker du supermarché Chef comme notre dépendance. Ce cookbook fournit des définitions de ressources supplémentaires qui peuvent être utilisées dans nos recettes. Nous les utiliserons plus tard comme blocs de construction pour configurer notre hôte Docker. Pour ajouter les dépendances, mettez à jour le fichier metadata.rb , comme suit:
name ‘dockerhost’
maintainer ‘The Authors’
maintainer_email ‘you@example.com’
license ‘all_rights’
description ‘Installs/Configures a dockerhost’
long_description ‘Installs/Configures a dockerhost’
version ‘0.1.0’
depends ‘docker’, ‘~> 4.8’
Le fichier metadata.rb fournit des métadonnées sur nos cookbook Chef. Les informations contenues dans les métadonnées fournissent des conseils au serveur Chef afin que le cookbook puisse être correctement déployé sur nos nœuds. Pour plus d’informations sur la configuration des métadonnées dans nos cookbook Chef, visitez http://docs.chef.io/config_rb_metadata.html.
4. Nous allons maintenant créer une recette Chef dans recipes / base.rb pour décrire la configuration de base de nos hôtes Docker. Le contenu de la recette suivante installe et démarre le moteur Docker à partir du référentiel YUM de Docker CE :
yum_repository ‘docker-stable’ do
description ‘Docker CE Stable’
baseurl ‘https://download.docker.com/linux’\
‘/centos/7/$basearch/stable’
gpgkey ‘https://download.docker.com/linux/centos/gpg’
end
docker_service ‘default’ do
version ‘18.09.0’
install_method ‘package’
setup_docker_repo false
action %w(create start)
end
5. Maintenant que notre cookbook est prêt, nous allons créer un fichier de règles de chef pour gérer l’emballage de notre cookbook et ses dépendances. Nous allons créer une stratégie appelée policies / base.rb pour décrire la configuration de base de notre hôte Docker :
name ‘base’
default_source :supermarket
cookbook ‘dockerhost’, path: ‘../cookbooks/dockerhost’
run_list ‘dockerhost::base’
6. Maintenant que nos dépendances sont déclarées, nous pouvons les télécharger en exécutant la commande suivante :
$ cd ~/chef-repo
$ chef install policies/base.rb
Building policy base
Expanded run list: recipe[dockerhost::base]
Caching Cookbooks…
Installing dockerhost >= 0.0.0 from path
Using docker 4.8.0
Lockfile written to ./policies/base.lock.json
Policy revision id: 67435037674caf004468b9a775eb44
Nous avons maintenant terminé de créer notre politique de base pour décrire notre hôte Docker. Notre dernière étape a généré un chef Policyfile lock policies / base.lock.json qui représente l’ensemble de cookbook que nous avons utilisé pour cette politique.
Politiques Push Chef
La dernière étape consiste à appliquer cette politique à nos hôtes Docker afin de récupérer la configuration souhaitée. Nous effectuerons les étapes suivantes pour y parvenir :
1. Tout d’abord, nous téléchargeons la stratégie sur notre serveur Chef dans un groupe de stratégies appelé production . Notez que dans la sortie de la commande suivante, le cookbook docker dont nous dépendons sera également automatiquement téléchargé :
$ chef push production policies/base.lock.json
Uploading policy base (6743503767) to policy group production
Uploaded docker 4.8.0 (d074b095)
Uploaded dockerhost 0.1.0 (3f2a6710)
2. Ensuite, nous affecterons tous nos hôtes Docker au groupe de règles de production et à la base de règles que nous avons téléchargées précédemment :
$ knife node policy set dockerhost production base
Successfully set the policy on node dockerhost
$ knife node policy set node1 production base
Successfully set the policy on node node1
3. Enfin, nous exécuterons le chef-client sur nos deux hôtes Docker. Le chef-client récupérera et appliquera la configuration d’état souhaitée que nous avons appliquée dans les étapes précédentes :
$ knife ssh ‘policy_group:production’ ‘chef-client’
node1 Starting Chef Client, version 14.7.17
dockerhost Starting Chef Client, version 14.7.17
node1 Using policy ‘base’ at revision…
dockerhost Using policy ‘base’ at revision…
…
node1 * service[docker] action start dockerhost * service[docker] action start
node1
node1 Running handlers:
node1 Running handlers complete
node1 Chef Client finished, … in 53 seconds
dockerhost
dockerhost Running handlers:
dockerhost Running handlers complete
dockerhost Chef Client finished, … in 53 seconds
Maintenant, nous avons installé et configuré Docker dans notre hôte Docker à l’aide de Chef. Chaque fois que nous devons ajouter un autre hôte Docker, nous pouvons simplement créer un autre serveur dans notre fournisseur de cloud et l’affecter à notre groupe de politiques de production et à notre base de politiques.
Dans un environnement de production, le but d’avoir un logiciel de gestion de configuration installé sur notre hôte Docker n’est jamais d’avoir à s’y connecter juste pour effectuer des mises à jour de configuration. L’exécution manuelle du chef-client ne représente que la moitié de l’automatisation.
Nous voudrons exécuter le chef-client comme un processus démon afin de ne pas avoir à l’exécuter à chaque fois que nous effectuons une mise à jour. Le démon chef-client interrogera le serveur Chef pour vérifier s’il existe des mises à jour du nœud qu’il gère. Par défaut, cet intervalle d’interrogation est défini sur 30 minutes.Pour plus d’informations sur la configuration de chef-clien t en tant que démon, reportez-vous à la documentation de Chef sur https://docs.chef.io/chef_client.html .
Dans la section suivante, nous allons itérer sur notre cookbook Chef pour inclure l’initialisation de notre cluster Docker Swarm.
Initialisation de Docker Swarm
Maintenant que nous avons une configuration de base pour configurer un hôte Docker, passons au niveau suivant et configurons automatiquement un cluster Docker Swarm:
1. Tout d’abord, nous avons besoin d’un moyen de stocker le jeton de jointure Docker Swarm en toute sécurité. Nous utiliserons chef-vault comme moyen de stocker le jeton. Pour pouvoir utiliser chef-vault , nous l’ajouterons simplement en tant que dépendance de notre cookbook dans cookbooks / dockerhost / metadata.rb :
name ‘dockerhost’
# …
version ‘0.1.0’
depends ‘docker’, ‘~> 4.7’
depends ‘chef-vault’, ‘~> 3.1’ # update here
2. Ensuite, nous allons créer une recette Chef pour initialiser le nœud du gestionnaire dans cookbooks / dockerhost / recipes / manager.rb :
include_recipe ‘dockerhost::base’
execute ‘init swarm’ do
command ‘docker swarm init’
not_if ‘docker info -f “{{.Swarm.LocalNodeState}}” | egrep “^active”‘
end
Notez que nous avons utilisé les clauses de garde du chef pour empêcher l’initialisation de l’essaim de docker de s’exécuter plusieurs fois. Cela rend notre recette de chef idempotente.
3. De retour dans notre recette de base, cookbook / dockerhost / recipes / base.rb , nous allons récupérer le jeton de jointure de chef-vault et exécuter docker join avec :
# previous contents of
# cookbooks/dockerhost/recipes/base.rb
# …
swarm = begin
chef_vault_item(‘docker’, ‘swarm’)\
[node.policy_group]
rescue Net::HTTPServerException
{}
end
execute ‘join swarm’ do
command ‘docker swarm join ‘\
“–token #{swarm[‘token’]} #{swarm[‘manager’]}”
not_if { swarm.empty? }
not_if ‘docker info -f “{{.Swarm.LocalNodeState}}” | egrep “^active”‘
end
4. Ensuite, nous lierons toutes nos modifications en mettant à jour nos politiques Chef Cheffile / base.rb :
name ‘base’
default_source :supermarket
cookbook ‘dockerhost’, path: ‘../cookbooks/dockerhost’
run_list ‘dockerhost::base’
named_run_list ‘manager’, ‘dockerhost::manager’
5. Une fois que tout est mis à jour, nous mettrons à jour la politique pour générer un nouveau fichier de verrouillage :
$ chef update policies/base.rb
Building policy base
Expanded run list: recipe[dockerhost::base]
Caching Cookbooks…
Installing dockerhost >= 0.0.0 from path
Using docker 4.8.0
Installing chef-vault 3.1.1
Lockfile written to ./policies/base.lock.json
Policy revision id: 9f698c0ddb57b3dcc6af62406588c3
6. Enfin, poussons maintenant cette nouvelle politique vers notre serveur Chef :
$ chef push production policies/base.lock.json
Maintenant que nous avons mis à jour notre politique, nous pouvons maintenant l’appliquer à nouveau à nos hôtes Docker. Les prochaines étapes initialiseront notre cluster Docker Swarm:
1. Tout d’abord, nous exécutons la recette du gestionnaire que nous avons créée précédemment dans notre hôte Docker dockerhost :
$ knife ssh -m dockerhost ‘chef-client –named-run-list manager’
dockerhost Starting Chef Client, version 14.7.17
…
dockerhost * execute[join swarm] action run (skipped due to not_if)
dockerhost Recipe: dockerhost::manager
dockerhost * execute[init swarm] action run
dockerhost – execute docker swarm init
dockerhost
dockerhost Running handlers:
dockerhost Running handlers complete
dockerhost Chef Client finished, … in 09 seconds
2. Ensuite, nous allons nous connecter à cet hôte Docker pour récupérer le jeton de jointure :
$ knife ssh -m dockerhost ‘docker swarm join-token worker’
dockerhost To add a worker to this swarm, run the following command:
dockerhost
dockerhost
docker swarm join –token SWMTKN-1-31h15evixetseazrs… 172.16.132.218:2377
dockerhost
3. Maintenant que nous savons ce qu’est le jeton de jointure, nous allons utiliser ces informations pour créer un fichier d’élément chef-vault dans vault / docker / swarm.json :
{
“production”: {
“token”: “SWMTKN-1-31h15evixetseazrs…”,
“manager”: “172.16.132.218:2377”
}
}
4. Ensuite, nous téléchargerons cet élément chef-vault en exécutant la commande suivante:
$ knife vault create -m client \
docker swarm “$(cat vault/docker/swarm.json) \
-S ‘policy_group:production’
5. Enfin, nous exécuterons à nouveau Chef dans tous nos hôtes Docker:
$ knife ssh ‘policy_group:production’ ‘chef-client’
dockerhost Starting Chef Client, version 14.7.17
node1 Starting Chef Client, version 14.7.17
…
dockerhost * execute[join swarm] action run (skipped…)
node1 * execute[join swarm] action run
node1 – execute docker swarm join –token …
dockerhost
dockerhost Running handlers:
dockerhost Running handlers complete
dockerhost Chef Client finished, … in 09 seconds
node1
node1 Running handlers:
node1 Running handlers complete
node1 Chef Client finished, … in 10 seconds
Comme nous pouvons le voir dans l’extrait précédent, node1 a rejoint notre cluster Docker Swarm. Notre noeud gestionnaire dockerhost n’a pas réinitialisé l’essaim car il fait déjà partie du cluster.
Nous avons maintenant terminé la configuration de notre cluster Docker Swarm comme nous l’avons fait dans le chapitre précédent. Mais maintenant, nous avons automatisé la plupart des étapes de sa configuration.
Nous pouvons également utiliser chef-vault pour distribuer les clés TLS et les certificats du gestionnaire Docker Swarm de la même manière.
Méthodes alternatives
Il existe d’autres outils de gestion de configuration à usage général qui nous permettent de configurer notre hôte Docker. Voici une courte liste des autres outils que nous pouvons utiliser :
- Puppet : Reportez-vous à http://puppetlabs.com .
- Ansible : Vous pouvez le trouver sur http://ansible.com .
- CFEngine : disponible sur http://cfengine.com .
- SaltStack : Vous pouvez trouver plus d’informations à ce sujet sur http://saltstack.com .
- Docker Machine : il s’agit d’un outil de gestion de configuration très spécifique qui nous permet de provisionner et de configurer les hôtes Docker dans notre infrastructure. Plus d’informations sur Docker Machine peuvent être trouvées sur la page de documentation Docker sur https://docs.docker.com/machine .
Si nous ne voulons pas du tout gérer notre infrastructure hôte Docker, nous pouvons utiliser les services d’hébergement Docker. Les fournisseurs de cloud populaires ont commencé à proposer des hôtes Docker en tant qu’image cloud pré-provisionnée que nous pouvons utiliser. D’autres offrent une solution plus complète qui nous permet d’interagir avec tous les hôtes Docker dans le cloud en tant qu’hôte Docker virtuel unique. Voici une liste de liens des fournisseurs de cloud populaires décrivant leur intégration avec l’écosystème Docker:
- Moteur Google Kubernetes ( https://cloud.google.com/kubernetes-engine )
- Amazon EC2 Container Service ( http://aws.amazon.com/documentation/ecs )
- Instances de conteneur Azure ( https://azure.microsoft.com/en-us/services/container-instances/ )
- Joyent Triton Compute ( https://www.joyent.com/triton/compute )
En termes de déploiement de conteneurs Docker, plusieurs outils de conteneur vous permettent de le faire. Ils fournissent des API pour exécuter et déployer nos conteneurs Docker. Certaines des API proposées sont même compatibles avec le moteur Docker lui-même. Cela nous permet d’interagir avec notre pool d’hôtes Docker comme s’il s’agissait d’un seul hôte Docker virtuel. Voici une liste de quelques outils qui nous permettent d’orchestrer le déploiement de nos conteneurs sur un pool d’hôtes Docker :
- CNCF Kubernetes ( http://kubernetes.io )
- Marathon mésophere ( https://mesosphere.github.io/marathon )
- Moteur SmartDataCenter Docker ( https://github.com/joyent/sdc-docker )
Cependant, nous avons toujours besoin d’outils de gestion de la configuration tels que Chef pour déployer et configurer nos systèmes d’orchestration au sommet de notre pool d’hôtes Docker.
Résumé
Dans ce chapitre, nous avons appris à automatiser la configuration de nos déploiements Docker. L’utilisation de Chef nous permet de configurer et de provisionner plusieurs hôtes Docker à l’échelle. À partir de ce moment, nous pouvons écrire des recettes Chef pour conserver toutes les techniques d’optimisation Docker que nous apprendrons dans cet article.
Dans le chapitre suivant, nous présenterons l’instrumentation pour surveiller l’ensemble de notre infrastructure et application Docker. Cela nous donnera d’autres réactions sur la façon d’optimiser nos déploiements Docker mieux pour de meilleures performances.
Surveillance de Docker
Nous savons maintenant comment optimiser nos déploiements Docker. Nous savons également comment évoluer pour améliorer les performances. Mais comment savons-nous que nos hypothèses de réglage étaient correctes ? Il est important de pouvoir surveiller notre infrastructure et notre application Docker pour comprendre pourquoi et quand nous devons optimiser. Mesurer les performances de notre système nous permet d’identifier ses limites pour évoluer et régler en conséquence.
En plus de surveiller les informations de bas niveau sur Docker, il est également important de mesurer les performances commerciales de notre application. En traçant le flux de valeur de notre application, nous pouvons corréler les mesures liées à l’entreprise à celles au niveau du système. Grâce à cela, nos équipes de développement et d’exploitation Docker peuvent montrer à leurs collègues comment Docker réduit les coûts de leur organisation et augmente la valeur commerciale.
Dans ce chapitre, nous aborderons les sujets suivants concernant notre capacité à surveiller notre infrastructure Docker et nos applications à grande échelle :
- L’importance du suivi
- Collecte de métriques dans Prometheus
- Consolidation des journaux dans une pile ELK
L’importance du suivi
La surveillance est importante car elle fournit une source de rétroaction sur le déploiement Docker que nous avons construit. Il offre une vue approfondie de notre application, des performances du système d’exploitation de bas niveau aux cibles commerciales de haut niveau. L’insertion d’une instrumentation appropriée dans nos hôtes Docker nous permet d’identifier l’état de notre système. Nous pouvons utiliser cette source de commentaires pour déterminer si notre application se comporte comme prévu à l’origine.
Si notre hypothèse initiale était incorrecte, nous pouvons utiliser les données de rétroaction pour réviser notre plan et changer notre système en conséquence en ajustant notre hôte Docker et ses conteneurs ou en mettant à jour notre application Docker en cours d’exécution. Nous pouvons également utiliser le même processus de surveillance pour identifier les erreurs et les bogues après le déploiement de notre système en production.
Docker a des fonctionnalités intégrées pour se connecter et surveiller. Par défaut, un hôte Docker stocke les flux d’erreur et de sortie standard d’un conteneur Docker dans des fichiers JSON dans /var/lib/docker/<container_id>/<container_id>-json.log. La commande docker logs demande au démon Docker Engine de lire le contenu des fichiers ici.
Une autre fonction de surveillance est la commande docker stats. Cela interroge le point de terminaison / containers / <contain_id> / stats de l’API distante du moteur Docker pour rapporter des statistiques d’exécution sur le groupe de contrôle du conteneur en cours d’exécution concernant son processeur, sa mémoire et l’utilisation du réseau. Voici un exemple de sortie de la commande docker stats signalant ces mesures :
dockerhost$ docker run –name running –d busybox \
/bin/sh -c ‘while true; do echo hello && sleep 1; done’
dockerhost$ docker stats running
CONTAINER CPU % MEM USAGE/LIMIT MEM % NET I/O
running 0.00% 0 B/518.5 MB 0.00% 17.06 MB/119.8 kB
Les commandes Docker logs et docker stats intégrées fonctionnent bien pour surveiller nos applications Docker pour le développement et les déploiements à petite échelle. Lorsque nous arrivons à un point de notre déploiement Docker de niveau production où nous gérons des dizaines, des centaines, voire des milliers d’hôtes Docker, cette approche ne sera plus évolutive. Il n’est pas possible de se connecter à chacun de nos milliers d’hôtes Docker et de saisir les journaux et les statistiques de docker.
Faire cela un par un rend également difficile la création d’une image plus globale de l’ensemble de notre déploiement Docker. De plus, toutes les personnes intéressées par les performances de notre application Docker ne peuvent pas se connecter à nos hôtes Docker. Les collègues qui ne traitent que l’aspect commercial de notre application voudront peut-être poser certaines questions concernant la façon dont le déploiement de notre application dans Docker améliore ce que notre organisation veut ; cependant, ils ne veulent pas nécessairement apprendre à se connecter et à commencer à taper des commandes Docker dans notre infrastructure.
Par conséquent, il est important de pouvoir consolider tous les événements et mesures de nos déploiements Docker dans une infrastructure de surveillance centralisée. Cela permet à nos opérations d’évoluer en ayant un point unique à partir duquel nous pouvons savoir ce qui se passe dans notre système. Un tableau de bord centralisé permet également aux personnes extérieures à notre équipe de développement et d’exploitation, telles que nos collègues de travail, d’avoir accès aux commentaires fournis par notre système de surveillance. Les sections restantes vous montreront comment consolider les messages des journaux Docker et collecter des statistiques à partir de sources de données, telles que les statistiques Docker.
Collecte de métriques avec Prometheus
Pour commencer à surveiller nos déploiements Docker, nous devons d’abord configurer un point de terminaison auquel envoyer nos valeurs surveillées. Prometheus est une pile de surveillance populaire pour collecter diverses mesures. Il fournit une API simple pour l’intégration avec divers outils. La plupart des outils natifs du cloud et liés aux conteneurs prennent déjà en charge l’intégration avec Prometheus. Plus tard, nous configurerons Prometheus pour collecter les métriques de notre infrastructure Docker.
Dans cette section, nous allons configurer les composants suivants pour construire notre infrastructure de surveillance basée sur Prometheus:
- Clients / exportateurs de Prometheus : il s’agit essentiellement de tout type de composant utilisant le format d’exposition de Prometheus qui expose les mesures à collecter par Prometheus. Nous activerons l’intégration de Prometheus avec Docker Engine pour surveiller les métriques liées à Docker dans notre cluster. Nous déploierons également cAdvisor, un outil pour surveiller les conteneurs qui s’exécutent dans tous nos nœuds Docker Swarm.
- Prometheus : nous allons configurer Prometheus lui-même pour extraire et rassembler les métriques des différents clients / exportateurs que nous avons mis en place.
- Grafana : Grafana fournit une belle visualisation pour divers moteurs de stockage métriques. Bien que Prometheus fournisse des graphiques de base prêts à l’emploi, Grafana possède une interface plus agréable pour visualiser les métriques que nous rassemblerons. Nous allons configurer Grafana pour se connecter à notre service Prometheus et inspecter les conteneurs exécutés à l’intérieur de notre cluster Docker Swarm.
Exposer les métriques de Prometheus
Pour commencer à surveiller notre infrastructure Docker, nous devons exposer les métriques des nœuds de notre cluster Docker Swarm. À la fin de cette section, nous obtiendrons des mesures compatibles avec Prometheus à partir des composants suivants :
- Docker Engine : fournit une intégration Prometheus intégrée au Docker Engine lui-même
- cAdvisor : un outil de Google qui surveille tous les conteneurs fonctionnant sur une machine. Il fournit une intégration avec Docker prêt à l’emploi
Tout d’abord, nous devons mettre à jour le démon Docker Engine s’exécutant dans chacun de nos nœuds. Les étapes suivantes illustrent comment effectuer cette mise à jour :
1. Tout d’abord, revenons à notre cookbook Chef que nous avons écrit dans le chapitre précédent. Mettons à jour notre recette de chef dans les cookbook / dockerhost / recipes / base.rb en utilisant le code suivant :
# cookbooks/dockerhost/recipes/base.rb
# …
docker_service ‘default’ do
misc_opts ‘–experimental=true –metrics-addr=0.0.0.0:1337’
# …
end
# …
Dans le code précédent, nous avons permis à Prometheus de s’intégrer au Docker Engine en spécifiant l’indicateur –metrics-addr. À l’heure actuelle, il s’agit toujours d’une fonctionnalité expérimentale de Docker, nous devons donc également définir l’indicateur –experimental .
2. Maintenant que nous avons édité notre cookbook, mettons à jour notre politique Chef et transmettons-la à notre serveur Chef, comme suit :
$ chef update policies/base.rb
$ chef push production policies/base.lock.json
3. Enfin, exécutons le chef-client dans tous nos nœuds, comme suit. Cela redémarrera tous les démons Docker Engine pour récupérer la configuration mise à jour :
$ knife ssh policy_group:production ‘sudo chef-client’
Nos métriques Prometheus sont exposées. Nous pouvons tester cela en interrogeant manuellement les points de terminaison Prometheus de chacun de nos nœuds Docker :
$ curl http://dockerhost:1337/metrics
…
$ curl http://node1:1337/metrics
…
swarm_store_write_tx_latency_seconds_bucket{le=”2.5″} 0
swarm_store_write_tx_latency_seconds_bucket{le=”5″} 0
swarm_store_write_tx_latency_seconds_bucket{le=”10″} 0
swarm_store_write_tx_latency_seconds_bucket{le=”+Inf”} 0
swarm_store_write_tx_latency_seconds_sum 0
swarm_store_write_tx_latency_seconds_count 0
Au moment de la rédaction de ce document, l’intégration de Prometheus dans Docker prend uniquement en charge l’exposition des métriques pour le moteur Docker lui-même. Afin de collecter les métriques réelles de nos conteneurs en cours d’exécution sur chaque hôte, nous devrons installer cAdvisor de Google.
Les prochaines étapes déploieront cAdvisor sur tous les nœuds participant à notre cluster Docker Swarm :
1. Tout d’abord, nous allons créer un fichier Docker Compose YAML appelé compose-monitoring.yml pour décrire comment exécuter le service cAdvisor, comme suit :
—
version: ‘3.7’
services:
cadvisor:
image: google/cadvisor
hostname: ‘{{.Node.Hostname}}’
deploy:
mode: global
command: -logtostderr=true -docker_only=true
volumes:
– /:/rootfs:ro
– /var/run:/var/run:rw
– /sys:/sys:ro
– /var/lib/docker:/var/lib/docker:ro
# Set for debugging and testing purposes
networks:
default:
driver: overlay
attachable: true
L’aspect important de cette définition de service est le déploiement / mode : entrée globale. Un service global exécutera des conteneurs cAdvisor sur chaque nœud de notre cluster Docker Swarm. Cela inclut également les nœuds de gestionnaire.
2. Après avoir créé le fichier Compose YAML, déployons-le maintenant sur notre cluster Docker Swarm, comme suit :
$ docker stack deploy -c compose-monitoring.yml monitoring
Creating network monitoring_default
Creating service monitoring_cadvisor
3. Nous pouvons maintenant tester si cAdvisor expose des métriques de conteneur en contactant le service Docker en cours d’exécution, comme suit :
$ docker run –network monitoring_default -it –rm alpine /bin/sh
/ # apk add -y curl
/ # curl http://cadvisor:8080/metrics
…
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.54791282078e+09
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 7.63068416e+0
Nous avons maintenant des processus qui exposent les métriques Prometheus pour nos conteneurs. Vous pouvez utiliser les références suivantes pour en savoir plus sur ces outils :
- Docker : https://docs.docker.com/config/thirdparty/prometheus
- cAdvisor : https://github.com/google/cadvisor
Gratter et visualiser les métriques
Maintenant que tous les noeuds finaux Prometheus sont préparés, nous pouvons maintenant procéder à la collecte de ces métriques dans Prometheus lui-même. Ensuite, nous exécuterons Grafana pour visualiser toutes les métriques que nous avons exposées dans la sous-section précédente.
Les étapes suivantes déploieront Prometheus en tant que service dans notre cluster Docker Swarm:
1. Tout d’abord, préparons une configuration de service pour Prometheus dans un fichier appelé prometheus.yml, comme suit :
—
global:
scrape_interval: 15s
scrape_configs:
– job_name: cadvisor
dns_sd_configs:
– names:
– ‘tasks.cadvisor’
type: A
port: 8080
– job_name: docker
static_configs:
– targets:
– dockerhost:1337
– node1:1337
Dans la configuration précédente, nous avons supprimé chaque moteur Docker de notre cluster Docker Swarm en spécifiant le nom d’hôte de chaque nœud. Pour cAdvisor, nous avons utilisé la découverte de service intégrée de Prometheus via DNS pour nous connecter à tous les conteneurs cAdvisor exécutés dans chaque nœud.
2. Pour démarrer Prometheus, mettons à jour notre fichier compose-monitoring.yml avec l’entrée suivante :
—
version: ‘3.7’
services:
prometheus:
image: prom/prometheus
configs:
– source: prometheus.yml
target: /etc/prometheus/prometheus.yml
# … cadvisor:
configs:
prometheus.yml:
file: ./prometheus.yml
# networks …
Dans la mise à jour précédente, nous nous sommes assurés que la configuration du service est correctement référencée.
3. Enfin, mettons à jour le déploiement de notre pile de services de surveillance, comme suit :
$ docker stack deploy -c compose-monitoring.yml monitoring
Creating config monitoring_prometheus.yml
Creating service monitoring_prometheus
Updating service monitoring_cadvisor (id: eiqb0w6e86bjm596vsut377)
Prometheus est maintenant prêt et élimine les points de terminaison métriques que nous avons configurés plus tôt. Confirmez que tous les points de terminaison sont correctement supprimés en interrogeant le point de terminaison de l’API cible de notre service Prometheus, comme suit :
$ docker run –network monitoring_default -it –rm alpine /bin/sh
/ # apk add -y curl jq
/ # curl -s http://prometheus:9090/api/v1/targets \
| jq ‘.data.activeTargets | .[].labels’
{
“instance”: “10.0.4.3:8080”,
“job”: “cadvisor”
}
{
“instance”: “10.0.4.4:8080”,
“job”: “cadvisor”
}
{
“instance”: “dockerhost:1337”,
“job”: “docker”
}
{
“instance”: “node1:1337”,
“job”: “docker”
}
Le composant suivant de notre pile de surveillance est Grafana. Les étapes suivantes déploieront Grafana en tant que service dans notre cluster Docker Swarm :
1. Tout d’abord, mettons à jour le fichier Docker Compose nommé compose-logging.yml pour définir comment Grafana s’exécutera dans notre cluster, comme suit :
—
version: ‘3.7’
services:
grafana:
image: grafana/grafana
ports:
– 3000:3000
# prometheus:
# cadvisor:
# …
2. Maintenant que nous avons terminé la mise à jour du fichier Compose, effectuons un redéploiement à l’aide de la commande suivante :
$ docker stack deploy -c compose-monitoring.yml monitoring
Creating service monitoring_grafana
Updating service monitoring_prometheus (id: hzarfvo8kd9g6cj441n31db7g)
Updating service monitoring_cadvisor (id: eiqb0w6e86bjm596vsut377ws)
3. Grafana devrait maintenant être prêt. Puisque nous avons configuré un port d’entrée pour le maillage de routage de Docker Swarm, nous pouvons aller sur http://dockerhost:3000 pour visiter notre déploiement Grafana.
4. Lorsque nous lançons Grafana pour la première fois, il nous sera demandé de nous connecter. Utilisons le nom d’utilisateur par défaut admin et le mot de passe admin configurés dans le conteneur officiel Grafana, comme indiqué dans la capture d’écran suivante :

Bien que facultatif, modifions également le mot de passe administrateur par défaut de notre installation Grafana :
5. Sur le tableau de bord principal, l’installation de Grafana nous dit quoi faire en premier, qui est d’ajouter une source de données. Dans la page de configuration (comme illustré dans la capture d’écran suivante), nous allons insérer un type de source de données Prometheus :
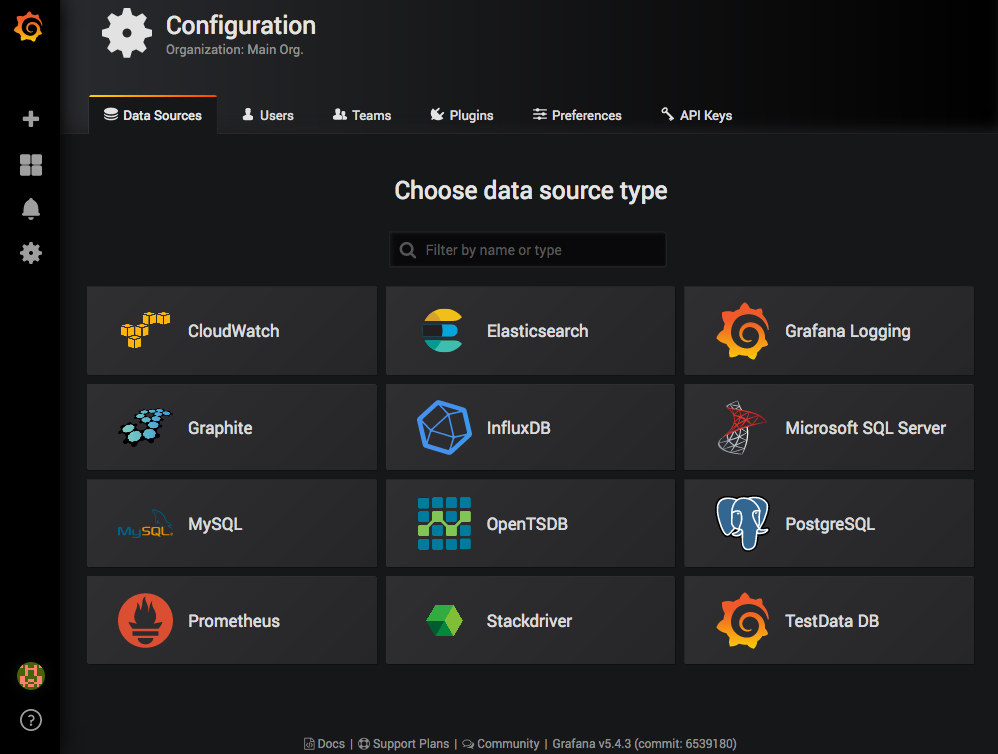
2. Pour configurer Grafana pour interroger notre service Prometheus, définissons l’URL HTTP à http://prometheus:9090, comme indiqué dans la capture d’écran suivante. C’est là que se trouve le service en fonction de la définition de notre fichier Docker Compose :
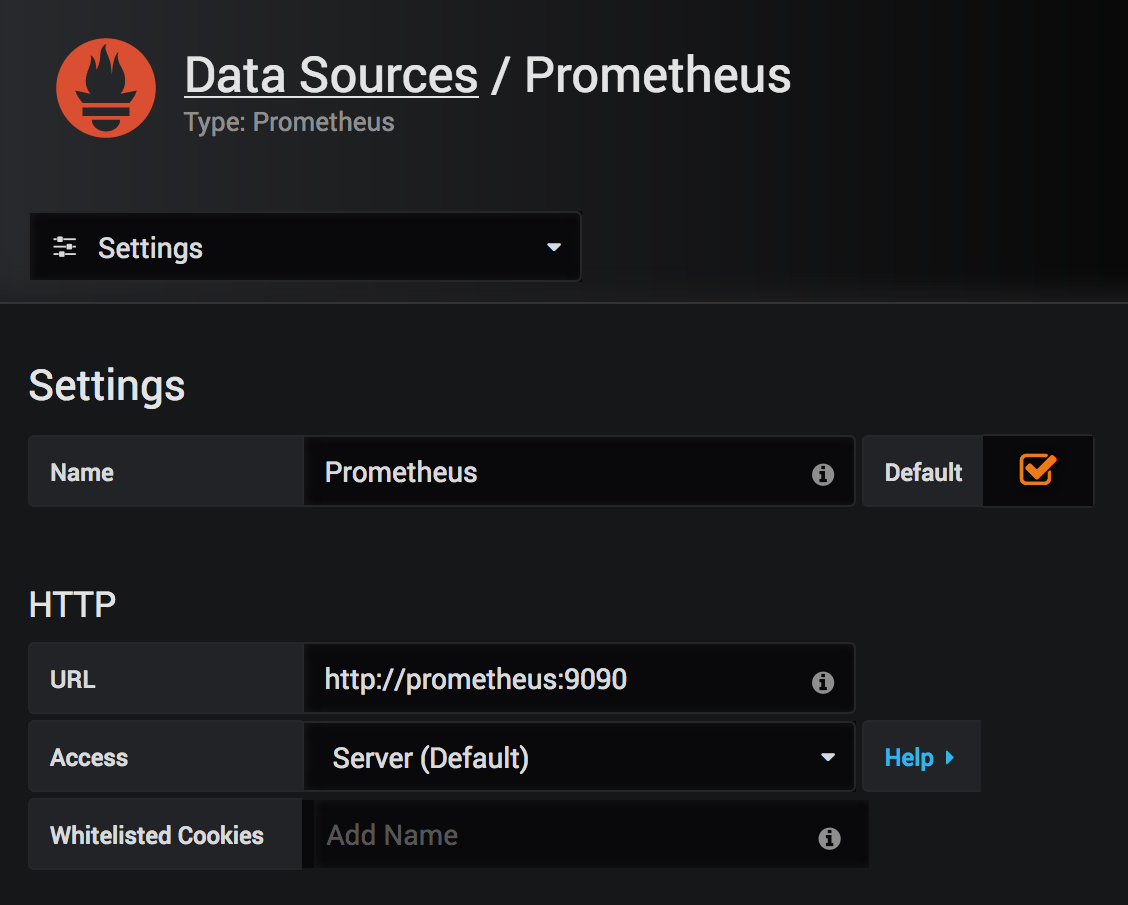
3. Pour mettre à jour les modifications, descendons tout le long de la page et appuyez sur le bouton Enregistrer et tester .
4. Nous sommes maintenant prêts à visualiser les métriques des conteneurs dans notre cluster Docker Swarm.
5. Allons dans la zone de recherche du tableau de bord de Grafana et cliquez sur Importer le tableau de bord . Collons le texte suivant dans la zone de texte JSON :
{
“panels”: [
{
“id”: 2,
“stack”: true,
“targets”: [
{
“expr”: “rate(container_cpu_usage_seconds_total
{container_label_com_docker_stack_namespace=\”monitoring\”}[1m])”,
“legendFormat”: “{{name}}”
}
],
“title”: “Container CPU usage”,
“type”: “graph”
}
],
“title”: “Docker Monitoring”
}
Nous pouvons avoir besoin d’ajuster la taille de la zone graphique dans notre tableau de bord si nécessaire pour voir la visualisation correctement.
Une fois le tableau de bord importé, nous verrons l’utilisation du processeur de la pile de surveillance que nous venons de déployer dans cette section. Le tableau de bord ressemblera à la capture d’écran suivante :
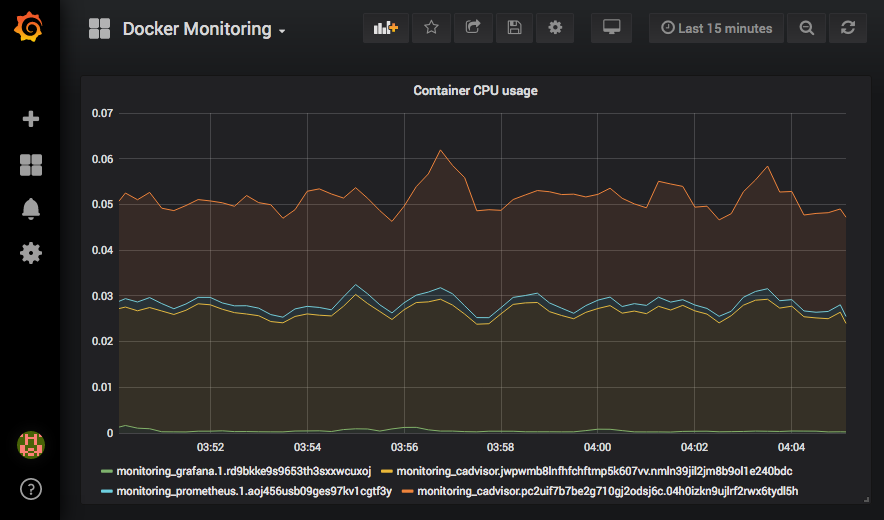
Toutes nos félicitations ! Nous avons maintenant une pile de surveillance appropriée pour notre cluster Docker Swarm.
Consolidation des journaux dans une pile ELK
Tous les statuts de nos hôtes et conteneurs Docker ne sont pas facilement disponibles pour être interrogés avec notre solution de surveillance dans Prometheus. Certains événements et mesures ne sont disponibles que sous forme de lignes brutes de texte dans les fichiers journaux. Nous devons transformer ces journaux bruts et non structurés en mesures significatives. Semblable aux mesures brutes, nous pouvons plus tard poser des questions de niveau supérieur sur ce qui se passe dans notre application Docker à l’aide de l’analyse.
La pile ELK est une suite de combinaisons populaire d’Elastic qui résout ces problèmes. Chaque lettre de l’acronyme représente chacun de ses composants. La liste suivante contient des descriptions de chacun d’eux :
- Elasticsearch : Elasticsearch est un moteur de recherche distribué hautement évolutif. Ses capacités de partage nous permettent de développer et de faire évoluer notre stockage de journaux alors que nous continuons à recevoir de plus en plus de journaux de nos conteneurs Docker. Son moteur de base de données est orienté document. Cela nous permet de stocker et d’annoter les journaux comme bon nous semble alors que nous continuons à découvrir plus d’informations sur les événements que nous gérons dans nos grands déploiements Docker.
- Logstash : Logstash est le composant utilisé pour collecter et gérer les journaux et les événements. Il s’agit du point central que nous utilisons pour collecter tous les journaux de différentes sources de journaux, tels que plusieurs hôtes Docker et conteneurs exécutés dans notre déploiement. Nous pouvons également utiliser Logstash pour transformer et annoter les journaux que nous recevons. Cela nous permet de rechercher et d’explorer les fonctionnalités plus riches de nos journaux plus tard.
- Kibana : Kibana est un tableau de bord d’analyse et de recherche pour Elasticsearch. Sa simplicité nous permet de créer des tableaux de bord pour nos applications Docker ; Cependant, Kibana est également très flexible à personnaliser, nous pouvons donc créer des tableaux de bord qui peuvent fournir des informations précieuses aux personnes qui souhaitent comprendre nos applications basées sur Docker, qu’elles aient un faible niveau de détails techniques ou un besoin commercial de niveau supérieur.
Dans les autres parties de cette section, nous allons configurer chacun de ces composants et leur envoyer nos journaux d’accueil et de conteneur Docker.
Déploiement d’Elasticsearch, Logstash et Kibana
Nous allons configurer la pile ELK en créant un fichier Docker Compose pour décrire ces services. Les étapes suivantes décrivent comment créer la pile ELK :
1. Tout d’abord, déployons le service Elasticsearch en créant le fichier appelé compose-logging.yml , comme indiqué dans le code suivant :
—
version: ‘3.7’
services:
elasticsearch:
image: elasticsearch:6.5.4
environment:
discovery.type: single-node
networks:
default:
driver: overlay
attachable: true
2. Ensuite, nous déployons ce fichier Docker Compose et faisons un test rapide pour confirmer qu’Elasticsearch s’exécute à l’aide du code suivant. Selon la capacité de notre hôte Docker, Elasticsearch peut mettre un certain temps à être prêt :
$ docker stack deploy -c compose-logging.yml logging
Creating network logging_default
Creating service logging_elasticsearch
$ docker run –network logging_default -it –rm alpine /bin/sh
/ # apk add curl
/ # curl http://elasticsearch:9200/_cluster/health\?pretty=true
{
“cluster_name” : “docker-cluster”,
“status” : “green”,
“timed_out” : false,
“number_of_nodes” : 1,
…
}
3. Ensuite, nous mettrons à jour le fichier compose-logging.yml pour lancer Kibana, comme suit :
—
version: ‘3.7’
services:
kibana:
image: kibana:6.5.4
ports:
– 5601:5601
# elasticsearch: …
# networks: …
4. Une fois le nouveau fichier Docker Compose prêt, lancez Kibana en réexécutant le déploiement de la pile comme suit :
$ docker stack deploy -c compose-logging.yml logging
Creating service logging_kibana
Updating service logging_elasticsearch (id:\ lewcnk24h7xdc3obwd7nwy9nm)
5. Depuis que nous avons activé le port d’entrée Docker Swarm pour Kibana, nous pouvons visiter http://dockerhost:5601 pour voir si notre service Kibana fonctionne. Nous devrions voir une page d’accueil comme celle de la capture d’écran suivante :
Nous examinerons la création d’un tableau de bord à partir des données Elasticsearch dans la section suivante :
1. Pour créer la dernière partie de notre pile de journalisation, nous devons d’abord créer un fichier de configuration nommé logstash.conf pour Logstash, comme suit :
input {
gelf { }
}
output {
# Optional: Enable for debugging
# stdout { }
elasticsearch {
hosts => [“http://elasticsearch:9200”]
}
}
2. Ensuite, nous mettons à jour le fichier compose-logging.yml en définissant le mode d’exécution du service Logstash à l’aide du code suivant. Notez que nous incluons également le fichier logstash.conf que nous avons préparé à l’étape précédente :
—
version: ‘3.7’
services:
# kibana: …
# elasticsearch: …
logstash:
configs:
– source: logstash.conf
target: /usr/share/logstash/pipeline/logstash.conf
image: logstash:6.5.4
ports:
– 12201:12201/udp
configs:
logstash.conf:
file: ./logstash.conf
# networks: …
3. Enfin, nous déployons Logstash et confirmons qu’il fonctionne en utilisant le code suivant :
$ docker stack deploy -c compose-logging.yml logging
Creating config logging_logstash.conf
Updating service logging_kibana (id: 1utcs8yl6k3zavdrms8q7vccm)
Updating service logging_elasticsearch (id:\ lewcnk24h7xdc3obwd7nwy9nm)
Creating service logging_logstash
$ docker run –network logging_default -it –rm alpine /bin/sh
/ # apk add curl
/ # curl http://logstash:9600/\?pretty
{
“host” : “3645f635a7b8”,
“version” : “6.5.4”,
“http_address” : “0.0.0.0:9600”,
“id” : “704b7fa5-1286-49ed-8381-f5ed79eb109d”,
“name” : “3645f635a7b8”,
“build_date” : “2018-12-17T22:04:46+00:00”,
“build_sha” : “7bf353ed88a10f3f2a9b81f6f3510ee41061e2f8”,
“build_snapshot” : false
}/
Nous avons maintenant la pile complète de notre infrastructure de journalisation en place. Nous devons maintenant configurer notre cluster Docker Swarm pour envoyer des journaux aux services de cette pile.
Transfert des journaux de conteneur Docker
Maintenant que nous avons une pile ELK fonctionnelle de base, nous pouvons commencer à lui transmettre nos journaux Docker. La prise en charge des pilotes de journalisation personnalisés est disponible à partir de Docker 1.7. Dans cette section, nous allons configurer notre hôte Docker pour utiliser le pilote GELF. Passons en revue les étapes suivantes pour commencer à recevoir nos journaux de conteneur dans la pile ELK :
1. Mettez à jour la recette base.rb comme suit :
# cookbooks/dockerhost/recipes/base.rb
# …
docker_service ‘default’ do
log_driver ‘gelf’
log_opts “gelf-address=udp://#{node[‘ipaddress’]}:12201”
# misc_opts … (for metrics in the previous section)
# …
end
# …
2. Mettez à jour la stratégie et déployez-la à l’aide du code suivant :
$ chef update policies/base.rb
$ chef push production policies/base.lock.json
3. Exécutez chef-client dans les nœuds Docker Swarm, comme suit :
$ knife ssh policy_group:production ‘sudo chef-client’
Tous les flux de sortie et d’erreur standard provenant de notre conteneur Docker doivent maintenant être capturés et placés dans notre pile ELK. Nous pouvons faire quelques tests préliminaires pour confirmer que la configuration fonctionne. Tapez la commande suivante pour créer un message de test à partir de Docker :
$ docker run –rm busybox echo message to elk
La commande docker run prend également en charge les options de ligne de commande –log-driver et –log-opt = [] pour configurer le pilote de journalisation uniquement pour le conteneur que nous voulons exécuter. Nous pouvons l’utiliser pour affiner nos politiques de journalisation pour chaque conteneur Docker exécuté sur notre hôte Docker.
Dans les étapes suivantes, nous effectuerons une configuration minimale dans Kibana afin de pouvoir rechercher le message de journal que nous avons envoyé de Docker plus tôt :
1. Tout d’abord, nous devons créer un modèle d’index dans lequel Kibana recherchera les journaux Elasticsearch. Allons à http://dockerhost:5601/app/kibana#/management/kibana/ index et utilisons les indices par défaut générés par Logstash logstash- * comme modèle d’index, comme le montre la capture d’écran suivante :
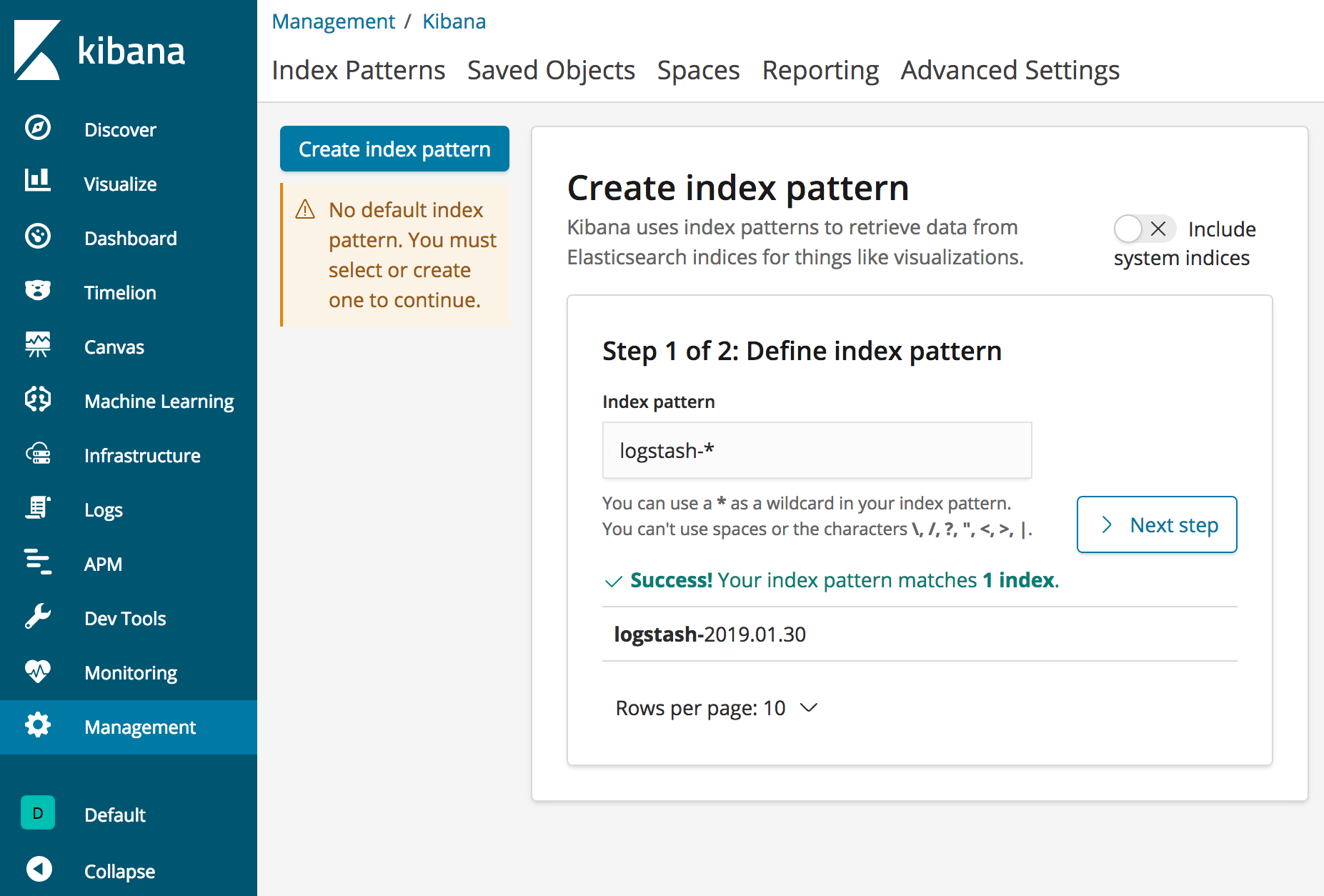
Cliquons sur Étape suivante pour passer aux boîtes de dialogue de configuration suivantes.
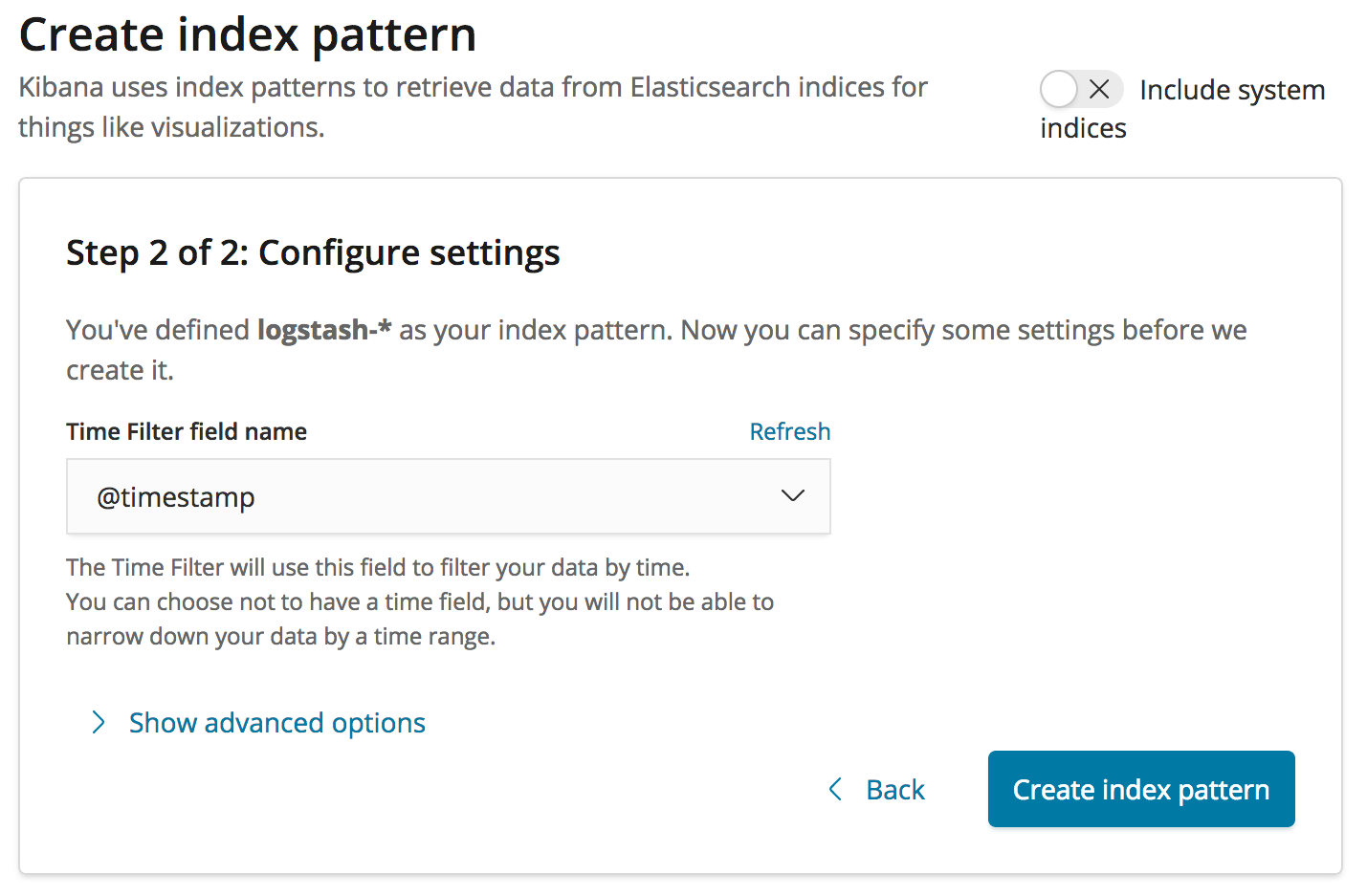
2. Maintenant que nous avons un modèle d’index, nous devons indiquer quels champs dans les documents d’index contiennent l’horodatage de nos journaux. Utilisons le champ temporel par défaut @timestamp, comme suit :
3. Enfin, cliquons sur le bouton Créer un modèle d’index pour terminer la création de notre modèle d’index.
Kibana est maintenant configuré pour consulter nos journaux Docker. Allons à notre point de terminaison Kibana dans http://dockerhost:5601/app/kibana#/ découvrez et recherchez l’expression “message à wapiti” (y compris les guillemets) dans la zone de texte. Le résultat de la recherche doit donner l’entrée du message que nous avons envoyé plus tôt. La capture d’écran suivante est à quoi devrait ressembler le résultat de la recherche :
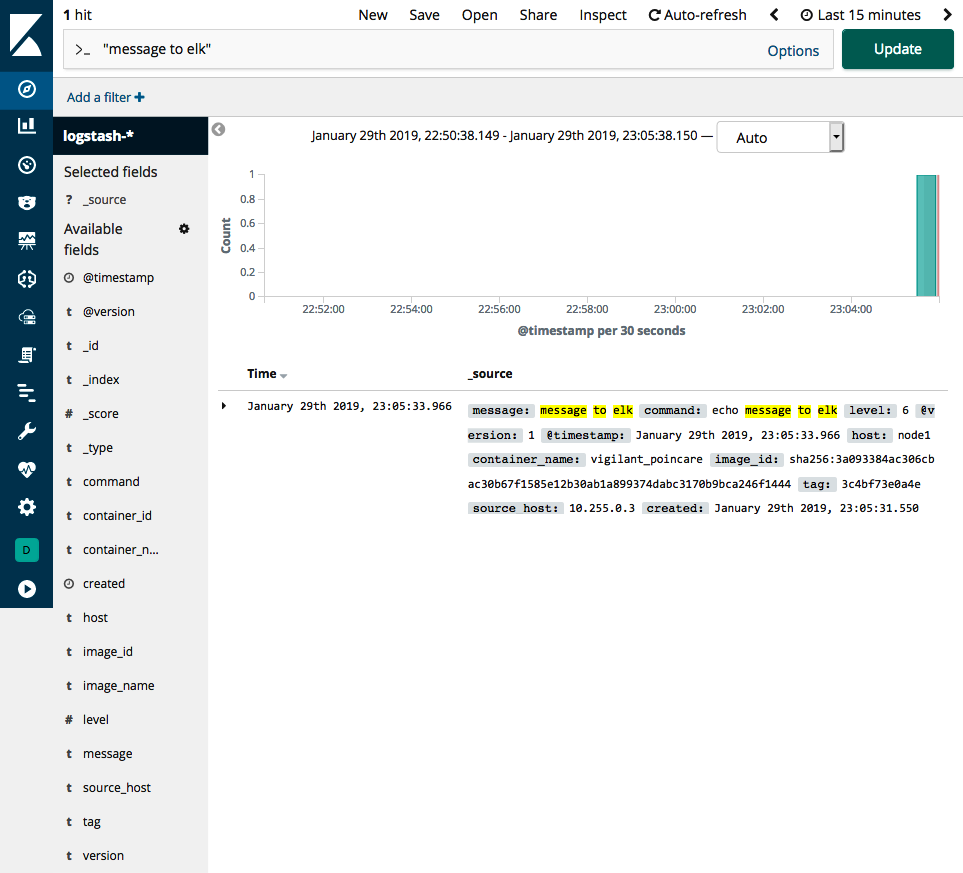
Dans la capture d’écran précédente, nous pouvons voir le message que nous avons envoyé. Il existe également d’autres informations sur le conteneur qui a généré le message de journal. Le pilote de journal GELF de Docker contient des informations telles que le nom de l’image Docker source, l’identification du conteneur et l’hôte Docker sur lequel le conteneur a été exécuté.
Outre les pilotes de journalisation de fichiers GELF et JSON par défaut, Docker prend en charge plusieurs autres points de terminaison vers lesquels envoyer des journaux. Plus d’informations sur tous les pilotes de journalisation et leurs guides d’utilisation respectifs sont disponibles sur https://docs.docker.com/config/containers/logging/.
Autres solutions de surveillance et de journalisation
Il existe plusieurs autres solutions que nous pouvons utiliser pour surveiller et journaliser l’infrastructure afin de prendre en charge notre application Docker. Certains d’entre eux ont déjà un support intégré pour surveiller les conteneurs Docker. D’autres doivent être combinées avec d’autres solutions, telles que celles que nous avons vues précédemment, car elles ne se concentrent que sur une partie spécifique de la surveillance ou de la journalisation.
Avec d’autres solutions, nous devrons peut-être utiliser certaines solutions de contournement ; cependant, leurs avantages l’emportent clairement sur le compromis que nous devons faire. Bien que la liste suivante ne soit pas exhaustive, elle montre quelques-unes des piles que nous pouvons explorer pour créer nos solutions de journalisation et de surveillance :
- Graphite ( http://graphiteapp.org/ )
- InfluxDB ( http://influxdb.com )
- Sensu ( http://sensuapp.org )
- Fluentd ( http://www.fluentd.org/ )
- Graylog ( http://www.graylog.org )
- Splunk ( http://www.splunk.com )
Parfois, le personnel d’exploitation et les développeurs exécutant et développant nos applications Docker ne sont pas encore suffisamment mûrs ou ne souhaitent pas se concentrer sur la maintenance de telles infrastructures de surveillance et de journalisation. Il existe plusieurs plates-formes de surveillance et de journalisation hébergées que nous pouvons utiliser afin de nous concentrer sur l’écriture et l’amélioration des performances de notre application Docker.
Certains d’entre eux fonctionnent avec des agents de surveillance et de journalisation existants. Avec d’autres, nous devrons peut-être télécharger et déployer leurs agents pour pouvoir transmettre les événements et les métriques à leur plateforme hébergée. Voici une liste non exhaustive de quelques solutions que nous pourrions envisager :
- Nouvelle relique ( http://www.newrelic.com )
- Datadog ( http://www.datadoghq.com )
- Librato ( http://www.librato.com )
- Elastic Cloud ( http://www.elastic.co/cloud )
- Treasure Data ( http://www.treasuredata.com )
- Splunk Cloud ( http://www.splunk.com )
Résumé
Nous savons maintenant pourquoi il est important de surveiller nos déploiements Docker de manière évolutive et accessible. Nous avons déployé Prometheus pour surveiller les métriques de notre conteneur Docker. Nous avons déployé une pile ELK pour consolider les journaux provenant de divers hôtes et conteneurs Docker.
En plus des mesures et événements bruts, il est également important de savoir ce que cela signifie pour notre application. Grafana et Kibana nous permettent de créer des tableaux de bord et des analyses personnalisés pour donner un aperçu de nos applications Docker. Grâce à ces outils de surveillance et à nos compétences dans notre arsenal, nous devrions être en mesure d’exploiter et d’exécuter correctement nos déploiements Docker en production.
Dans le prochain chapitre, nous allons optimiser nos images Docker et améliorer notre flux de travail de développement.
Optimisation des images Docker
Les images Docker fournissent un format de package standard qui permet aux développeurs et aux administrateurs système de travailler ensemble pour simplifier la gestion du code d’une application. Le format de conteneur de Docker nous permet d’itérer rapidement les versions de notre application et de les partager avec le reste de notre organisation. Nos temps de développement, de test et de déploiement sont plus courts qu’ils ne le seraient autrement en raison de la fonctionnalité légère et de la vitesse des conteneurs Docker. La portabilité des conteneurs Docker nous permet de faire évoluer nos applications des serveurs physiques aux machines virtuelles dans le cloud.
Cependant, nous commencerons à remarquer que les mêmes raisons pour lesquelles nous avons utilisé Docker en premier lieu perdent leurs effets bénéfiques. Le temps de développement augmente car nous devons toujours télécharger la dernière version de la bibliothèque d’exécution d’images Docker de notre application. Le déploiement prend beaucoup plus de temps car Docker Hub est lent; au pire, Docker Hub est peut-être en panne, et nous ne pourrons pas faire de déploiement du tout. Nos images Docker sont maintenant si grandes, de l’ordre de gigaoctets, que de simples mises à jour sur une seule ligne prennent toute la journée.
Ce chapitre couvrira les scénarios suivants sur la façon dont les conteneurs Docker deviennent incontrôlables et suggère des étapes pour résoudre les problèmes mentionnés précédemment :
- Réduction du temps de déploiement des images
- Amélioration du temps de création d’image
- Réduction de la taille de l’image Docker
- Guide d’optimisation
Après ce chapitre, nous aurons une construction et un déploiement de flux de travail plus rationalisés de nos images Docker.
Réduction du temps de déploiement
Au fur et à mesure que nous construisons notre conteneur Docker, sa taille augmentera de plus en plus. La mise à jour des conteneurs en cours d’exécution dans nos hôtes Docker existants n’est pas un problème. Docker tire parti des couches d’images Docker que nous créons au fil du temps à mesure que notre application se développe ; cependant, considérons le cas où nous voulons étendre notre application. Cela nécessite le déploiement de plus de conteneurs Docker sur des hôtes Docker supplémentaires. Dans ce cas, chaque nouvel hôte Docker devra télécharger toutes les grandes couches d’images que nous avons construites au fil du temps. Cette section vous montrera comment une grande application Docker affecte le temps de déploiement sur les nouveaux hôtes Docker. Commençons par créer cette application Docker problématique en procédant comme suit :
1. Écrivez le Dockerfile suivant pour créer notre grande image Docker :
FROM debian:stretch
RUN dd if=/dev/urandom of=/largefile bs=1024 count=524288
2. Ensuite, créez le Dockerfile en tant que hubuser / largeapp à l’aide de la commande suivante :
dockerhost$ docker build -t hubuser/largeapp .
3. Prenez note de la taille de l’image Docker créée. Dans l’exemple de sortie suivant, la taille est de 662 Mo :
dockerhost$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
aespinosa/largeapp latest 0e519ec6e31f 2 minutes ago 637MB
debian stretch d508d16c64cd 2 days ago 101MB
4. À l’aide de la commande time, enregistrez le temps qu’il faut pour le pousser et le retirer de Docker Hub, comme suit :
dockerhost$ time docker push hubuser/largeapp
The push refers to repository [docker.io/hubuser/largeapp]
eb6ed1590bf8: Pushed
13d5529fd232: Layer already exists
latest: digest: sha256:0ff29cc728fc8c274bc0ac43ca2815986ced89fbff35399b1c0e7d4bf31c
size: 742
real 11m34.133s
user 0m0.164s
sys 0m0.104s
5. Faisons également le même test de synchronisation lors de l’extraction de l’image Docker, mais supprimons d’abord l’image de notre démon Docker, comme indiqué dans le code suivant :
dockerhost$ docker rmi hubuser/largeapp
dockerhost$ time docker pull hubuser/largeapp
Using default tag: latest
latest: Pulling from hubuser/largeapp
741437d97401: Pull complete
d7d6d7c9ffc5: Pull complete
Digest: sha256:0ff29cc728fc8c274bc0ac43ca2815986ced89fbff35399b1c0e7d4bf31c
Status: Downloaded newer image for hubuser/largeapp:latest
real 2m19.909s
user 0m0.707s
sys 0m0.645s
Comme nous pouvons le voir dans les résultats de chronométrage, il faut beaucoup de temps pour utiliser Docker Push pour télécharger une image sur Docker Hub. Lors du déploiement, le docker pull prend autant de temps pour propager notre nouvelle image Docker à nos nouveaux hôtes Docker de production. Ces valeurs de temps de téléchargement et de téléchargement dépendent également de la connexion réseau entre Docker Hub et nos hôtes Docker. En fin de compte, lorsque Docker Hub tombera en panne, nous perdrons la possibilité de déployer de nouveaux conteneurs Docker ou d’évoluer vers des hôtes Docker supplémentaires à la demande.
Afin de profiter de la livraison rapide des applications de Docker et de la facilité de déploiement et de mise à l’échelle, il est important que notre méthode de pousser et de tirer des images Docker soit fiable et rapide. Heureusement, nous pouvons exécuter notre propre registre Docker afin qu’il puisse héberger et distribuer nos images Docker sans compter sur le Docker Hub public. Les étapes suivantes décrivent comment configurer cela pour confirmer l’amélioration des performances :
1. Exécutons notre propre registre Docker en tapant la commande suivante. Ce code est destiné à un registre local exécuté sur tcp: // dockerhost: 5000 :
dockerhost$ docker run –network=host -d registry:2
2. Ensuite, confirmons comment nos déploiements d’images Docker se sont améliorés. Tout d’abord, créez une balise pour l’image que nous avons créée plus tôt afin de la pousser vers le registre Docker local en utilisant ce qui suit :
dockerhost$ docker tag hubuser/largeapp dockerhost:5000/largeapp
3. Observez combien il est plus rapide de pousser la même image Docker sur notre registre Docker en cours d’exécution. Les tests suivants montrent que l’envoi d’images Docker est désormais au moins 10 fois plus rapide :
dockerhost$ docker push dockerhost:5000/largeapp
The push refers to repository [dockerhost:5000/largeapp]
latest: digest: sha256:0ff29cc728fc8c274bc0ac43ca2815986ced89fbff35399b1c0e7d4bf… size: 742
real 0m46.816s
user 0m0.090s
sys 0m0.064s
4. Maintenant, confirmez les nouvelles performances lorsque nous extrayons nos images Docker de notre registre Docker local. Les tests suivants montrent que le téléchargement d’images Docker est désormais plus rapide de plusieurs ordres de grandeur :
# make sure we removed the image we built
dockerhost$ docker rmi dockerhost:5000/largeapp hubuser/largeapp
dockerhost$ time docker pull dockerhost:5000/largeapp
Using default tag: latest
latest: Pulling from largeapp
Digest: sha256:0ff29cc728fc8c274bc0ac43ca2815986ced89fbff35399b1c0e7d4bf31c38e1
Status: Downloaded newer image for dockerhost:5000/largeapp:latest
real 0m16.328s
user 0m0.039s
sys 0m0.100s
La principale cause de ces améliorations est que nous avons téléchargé et téléchargé les mêmes images à partir de notre réseau local. Nous avons économisé la bande passante de nos hôtes Docker et notre temps de déploiement est devenu plus court. La meilleure partie de toutes, c’est que nous ne devons plus compter sur la disponibilité de Docker Hub pour déployer.
Afin de déployer nos images Docker sur d’autres hôtes Docker, nous devons configurer la sécurité de notre registre Docker. Les détails sur la façon de configurer cela sont en dehors de la portée de cet article ; cependant, plus de détails sur la façon de configurer un registre Docker sont disponibles sur https://docs.docker.com/registry/deploying .
Amélioration du temps de construction de l’image
Les images Docker sont les principaux artefacts sur lesquels les développeurs travaillent la plupart du temps. La simplicité des fichiers Docker et la rapidité de la technologie des conteneurs nous permettent de permettre une itération rapide sur l’application sur laquelle nous travaillons ; cependant, ces avantages de l’utilisation de Docker commencent à diminuer une fois que le temps nécessaire pour créer des images Docker commence à croître de manière incontrôlable. Dans cette section, nous allons discuter de certains cas de création d’images Docker qui prennent un certain temps à s’exécuter. Nous vous donnerons ensuite quelques conseils sur la façon de remédier à ces effets en procédant comme suit :
- Utilisation des miroirs de registre
- Réutilisation des calques d’image
- Réduction de la taille du contexte de génération
- Utilisation de proxys de mise en cache
Utilisation des miroirs de registre
Un grand contributeur au temps de création d’image est le temps passé à chercher des images en amont. Supposons que nous ayons un Dockerfile avec la ligne suivante :
FROM openjdk:jre-stretch
Cette image devra télécharger openjdk: jre-stretch pour être construit. Lorsque nous passons à un autre hôte Docker, ou si l’image openjdk: jre-stretch est mise à jour dans Docker Hub, notre temps de construction augmente momentanément. La configuration d’un miroir de registre local réduira ces augmentations du temps de création d’image.
Cela est très utile dans une organisation, où chaque développeur a ses propres hôtes Docker sur ses postes de travail. Le réseau de l’organisation ne télécharge l’image de Docker Hub qu’une seule fois. Chaque hôte Docker de poste de travail de l’organisation peut désormais extraire directement les images du miroir de registre local.
La configuration d’un miroir de registre est aussi simple que le processus de configuration d’un registre local dans la section précédente ; cependant, en plus, nous devons configurer l’hôte Docker pour qu’il soit au courant de ce miroir de registre en passant l’option –registry-mirror au démon Docker.
Suivez les étapes suivantes pour configurer cela :
1. Dans notre hôte CentOS Docker, configurez le démon Docker en mettant à jour le fichier de configuration, /etc/docker/daemon.json , comme suit:
{
“registry-mirrors”: [
“http://127.0.0.1:5000”
]
}
2. Ensuite, redémarrez le démon Docker pour le démarrer avec l’ unité systemd nouvellement configurée à l’aide de la commande suivante:
dockerhost$ systemctl restart docker.service
3. Enfin, exécutez le conteneur Docker du miroir de registre à l’aide de la commande suivante:
dockerhost$ docker run –network=host -d \
-e PROXY_REMOTEURL=https://registry-1.docker.io \
registry:2
Si nous voulons appliquer ces modifications à notre cluster, nous devons mettre à jour la recette de base Chef pour nos nœuds Docker Swarm.
Pour le registre, il peut être déployé en tant que service approprié sécurisé et géré par Docker Compose.
Pour confirmer que le miroir de registre fonctionne comme prévu, procédez comme suit :
1. Générez le Dockerfile décrit au début de cette sous-section et notez son heure de génération. Notez que la plupart du temps nécessaire pour créer l’image Docker est consacré au téléchargement de l’image Docker openjdk: jre-stretch en amont , comme indiqué dans la commande suivante :
dockerhost$ time docker build -t hubuser/mirror
Sending build context to Docker daemon 2.048kB
Step 1/1 : FROM openjdk:jre-stretch
jre-stretch: Pulling from library/openjdk
…
Status: Downloaded newer image for openjdk:jre-stretch
—> 9df4aac22102
Successfully built 9df4aac22102
Successfully tagged hubuser/mirror:latest
real 1m58.095s
user 0m0.036s
sys 0m0.028s
2. Maintenant, supprimez l’image et sa dépendance en amont et reconstruisez l’image à nouveau à l’aide des commandes suivantes :
dockerhost$ docker rmi openjdk:jre-stretch hubuser/mirror
dockerhost$ time docker build -t hubuser/mirror
Sending build context to Docker daemon 2.048kB
Step 1/1 : FROM openjdk:jre-stretch
jre-stretch: Pulling from library/openjdk
…
Status: Downloaded newer image for openjdk:jre-stretch
—> 9df4aac22102
Successfully built 9df4aac22102
Successfully tagged hubuser/mirror:latest
real 0m24.422s
user 0m0.073s
sys 0m0.081
Lorsque l’image Docker openjdk: jre-stretch a été téléchargée pour la deuxième fois, elle a été récupérée à partir du miroir de registre local au lieu d’être connectée à Docker Hub. La configuration d’un miroir de registre Docker a amélioré le temps de téléchargement de l’image en amont de près de deux fois l’habituel. Si nous avons d’autres hôtes Docker pointés sur ce même miroir de registre, cela fera la même chose : ignorer le processus de téléchargement depuis Docker Hub.
Ce guide sur la configuration d’un miroir de registre est basé sur celui du site Web de documentation Docker. Plus de détails peuvent être trouvés sur https://docs.docker.com/registry/recipes/mirror/.
Réutilisation des couches d’image
Comme nous le savons déjà, une image Docker se compose d’une série de couches combinées avec le système de fichiers union d’une seule image. Lorsque nous travaillons sur la construction de notre image Docker, les instructions précédentes de notre Dockerfile sont examinées par Docker pour vérifier s’il existe une image existante dans son cache de génération qui peut être réutilisée au lieu de créer une image similaire ou en double pour ces instructions.
En découvrant le fonctionnement du cache de génération, nous pouvons augmenter considérablement la vitesse des générations suivantes de nos images Docker. Un bon exemple de cela est lorsque nous développons le comportement de notre application ; nous n’ajouterons pas de dépendances à notre application tout le temps. La plupart du temps, nous souhaitons simplement mettre à jour le comportement de base de l’application elle-même. Sachant cela, nous pouvons concevoir la façon dont nous allons construire nos images Docker autour de cela dans notre flux de travail de développement.
Des règles détaillées sur la façon dont les instructions Dockerfile sont mises en cache peuvent être trouvées sur https://docs.docker.com/develop/develop-images/dockerfile_best-practices/#leverage-build-cache.
Par exemple, supposons que nous travaillons sur une application Ruby dont l’arborescence source ressemble à la suivante :
config.ru serait le suivant :
app = proc do |env|
[200, {}, %w(hello world)]
end
run app
Gemfile serait comme suit :
gem ‘rack’
gem ‘nokogiri’
Dockerfile serait comme suit :
FROM ruby:2.6.1
ADD . /app
WORKDIR /app
RUN bundle install
EXPOSE 9292
CMD rackup -E none
Les étapes suivantes vous montreront comment créer l’application Ruby que nous avons écrite plus tôt en tant qu’image Docker :
1. Commençons par créer cette image Docker à l’aide de la commande suivante. Notez que le temps de construction est d’environ une minute :
dockerhost$ time docker build -t slowdependencies .
Sending build context to Docker daemon 4.096kB
Step 1/6 : FROM ruby:2.6.1
…
Step 4/6 : RUN gem install -g
—> Running in 55ed0862f20a
Installing rack (2.0.6)
Installing mini_portile2 (2.4.0)
Installing nokogiri (1.10.1)
Building native extensions. This could take a while…
Removing intermediate container 55ed0862f20a
—> 61a50ca8c9a6
…
Successfully built af27ef83d1a2
Successfully tagged slowdependencies:latest
real 0m55.799s
user 0m0.035s
sys 0m0.039s
2. Ensuite, mettez à jour config.ru pour modifier le comportement de l’application, comme suit :
app = proc do |env|
[200, {}, %w(hello other world)]
end
run app
3. Construisons à nouveau l’image Docker et notons le temps qu’il faut pour terminer la construction. Exécutez la commande suivante :
$ time docker build -t slowdependencies .
…
Step 4/6 : RUN gem install -g
—> Running in 02c2daf0bc40
Installing rack (2.0.6)
Installing mini_portile2 (2.4.0)
Installing nokogiri (1.10.1)
Building native extensions. This could take a while…
…
Successfully tagged slowdependencies:latest
real 0m56.138s
user 0m0.028s
sys 0m0.051s
Notez que, même avec une modification sur une seule ligne de notre application, nous devons exécuter gem install -g pour chaque itération de l’image Docker que nous construisons. Cela peut être très inefficace et perturber le flux de notre développement car il faut une minute pour créer et exécuter notre application Docker. Pour les développeurs impatients, cela ressemble à une éternité !
Afin d’optimiser ce flux de travail, nous pouvons séparer la phase dans laquelle nous préparons les dépendances de notre application séparément de notre application réelle. Les étapes suivantes nous montrent comment procéder :
1. Tout d’abord, mettez à jour notre Dockerfile avec les modifications suivantes :
FROM ruby:2.6.1
ADD Gemfile /app/Gemfile
WORKDIR /app
RUN gem install -g
ADD . /app
EXPOSE 9292
CMD rackup -E none
2. Ensuite, créez la nouvelle image Docker refactorisée à l’aide de cette commande :
dockerhost$ $ time docker build -t fastdependencies .
Sending build context to Docker daemon 6.144kB
…
Step 4/7 : RUN gem install -g
—> Running in 01c6d0732716
Installing rack (2.0.6)
Installing mini_portile2 (2.4.0)
Installing nokogiri (1.10.1)
Building native extensions. This could take a while…
Removing intermediate container 01c6d0732716
—> 5d6848c306b6
…
Successfully tagged fastdependencies:latest
real 0m52.838s
user 0m0.034s
sys 0m0.039s
Prenons note de l’ID d’image du conteneur intermédiaire généré par l’étape 4/7 : gem install -g.
3. Maintenant, mettons à jour config.ru à nouveau et reconstruisons l’image, comme suit :
dockerhost$ vi config.ru # edit as we please
dockerhost$$ time docker build -t fastdependencies .
…
…
Step 4/7 : RUN gem install -g
—> Using cache
—> 5d6848c306b6
Step 5/7 : ADD . /app
—> d917b622038b
…
Successfully tagged fastdependencies:latest
real 0m0.540s
user 0m0.036s
sys 0m0.046s
Comme nous pouvons le voir dans la sortie précédente, la construction de docker a réutilisé le cache jusqu’à l’étape 4/7, car il n’y avait aucun changement dans Gemfile. Notez que le temps de construction de nos images Docker a diminué de 80 fois le temps de construction habituel !
Ce type de refactoring pour notre image Docker est également utile pour réduire le temps de déploiement. Nos hôtes Docker en production ont déjà des couches d’images jusqu’à l’étape 4/7 de notre image Docker dans la version précédente de notre conteneur. Une nouvelle version de notre application Docker ne nécessitera que l’hôte Docker pour extraire de nouvelles couches d’image de l’étape 4/7 à l’étape 7/7 afin de mettre à jour notre application.
Réduction de la taille du contexte de génération
Supposons que nous ayons un Dockerfile dans le contrôle de version Git similaire au suivant :
À un moment donné, nous remarquerons que notre répertoire .git est trop volumineux. C’est probablement le résultat d’avoir de plus en plus de code engagé dans notre arbre source :
dockerhost$ du -hsc .git
1001M .git
1001M total
Maintenant, lorsque nous construisons notre application Docker, nous remarquerons que le temps nécessaire pour créer notre application Docker est également très élevé. Jetez un œil à la sortie suivante :
dockerhost$ time docker build -t hubuser/largecontext .
Sending build context to Docker daemon 1.024GB
…
Successfully tagged hubuser/largecontext:latest
real 0m12.638s
user 0m0.572s
sys 0m1.388s
Si nous regardons attentivement la sortie précédente, nous verrons que le client Docker a téléchargé l’intégralité du répertoire .git de 1 Go sur le démon Docker car il fait partie de notre contexte de génération. De plus, comme il s’agit d’un contexte de construction volumineux, il faut du temps au démon Docker pour le recevoir avant de pouvoir commencer à construire notre image Docker.
Cependant, ces fichiers ne sont pas nécessaires pour construire notre application. De plus, ces fichiers liés à Git ne sont pas du tout nécessaires lorsque nous exécutons notre application en production. Nous pouvons configurer Docker pour ignorer un ensemble spécifique de fichiers qui ne sont pas nécessaires pour créer notre image Docker. Suivez les étapes suivantes pour effectuer cette optimisation :
1. Créez un fichier .dockerignore avec le contenu suivant dans le même répertoire que notre Dockerfile :
.git
2. Enfin, reconstruisez notre image Docker en exécutant la commande suivante :
dockerhost$ time docker build -t hubuser/largecontext .
Sending build context to Docker daemon 3.072kB
…
Successfully tagged hubuser/largecontext:latest
real 0m0.224s
user 0m0.027s
sys 0m0.070s
Nous pouvons voir dans la sortie ci-dessus que le temps de construction est réduit de plus de 500 fois simplement en diminuant la taille du contexte de construction du Docker.
Pour plus d’informations sur l’utilisation des fichiers .dockerignore , rendez -vous sur https://docs.docker.com/reference/builder/#dockerignore-file .
Utilisation de proxy de mise en cache
Un autre problème courant qui provoque de longs temps d’exécution dans la création d’images Docker est les instructions qui téléchargent les dépendances. Par exemple, une image Docker basée sur CentOS doit récupérer des packages à partir de référentiels YUM. Selon la taille de ces packages, le temps de génération d’une instruction d’installation yum peut être long.
Une technique utile pour réduire le temps nécessaire à ces instructions de génération consiste à introduire des proxys qui mettent en cache ces packages de dépendance. Un proxy de mise en cache populaire est apt-cacher-ng. Cette section décrit comment l’exécuter et le configurer pour améliorer notre flux de travail de construction d’image Docker.
Ce qui suit est un exemple de Dockerfile qui installe beaucoup de paquets Debian :
FROM centos:7
RUN yum install -y java-11-openjdk-headless
Notez que son temps de génération dans la sortie suivante est assez long car ce fichier Dockerfile télécharge de nombreuses dépendances et packages liés à Java (java-11-openjdk-headless). Exécutez la commande suivante :
dockerhost$ time docker build -t beforecaching .
…
Successfully tagged beforecaching:latest
real 3m41.779s
user 0m0.035s
sys 0m0.079s
Afin d’améliorer le flux de travail pour la construction de cette image Docker, nous allons configurer un proxy de mise en cache avec apt-cacher-ng . Il existe quelques images Docker prêtes à l’emploi d’apt-cacher-ng de Docker Hub. Suivez les étapes suivantes pour préparer apt-cacher-ng :
En général, il est recommandé de vérifier le contenu des images Docker dans des environnements tels que Docker Hub, au lieu de leur faire confiance aveuglément. La page de l’image Docker apt-cacher-ng que nous utilisons se trouve à l’ adresse https://hub.docker.com/r/sameersbn/apt-cacher-ng .
1. Exécutez la commande suivante dans notre hôte Docker pour démarrer apt-cacher-ng :
dockerhost$ docker run -d –network=host sameersbn/apt-cacher-ng
2. Nous allons créer une nouvelle image Docker de base. Après cela, nous utiliserons le proxy de mise en cache que nous avons exécuté plus tôt, comme décrit dans le Dockerfile suivant :
FROM centos:7
ADD proxy.conf /etc/yum/proxy.conf
RUN sed -i ‘s/^mirr/#mirr/’ /etc/yum.repos.d/CentOS-Base.repo && \
sed -i ‘s/^#bas/bas/’ /etc/yum.repos.d/CentOS-Base.repo
3. Pour le fichier proxy.conf à l’intérieur de notre image Docker, nous avons l’entrée suivante afin que YUM télécharge via notre installation apt-cacher-ng :
[main]
proxy=http://dockerhost:3142
4. Générez le Dockerfile que nous avons créé plus tôt en tant qu’image Docker étiquetée comme hubuser / centos: 7 à l’aide de la ligne de commande suivante :
dockerhost$ docker build -t hubuser/centos:7
5. Ensuite, faites hubuser / debian: jessie notre nouvelle image Docker de base en mettant à jour notre Dockerfile qui installe beaucoup de paquets Debian pour les dépendances, tels que les suivants:
FROM hubuser/centos:7
RUN yum install -y java-11-openjdk-headless
6. Pour confirmer le nouveau flux de travail, exécutez une génération initiale pour réchauffer le cache à l’aide de la commande suivante :
dockerhost$ docker build -t aftercaching .
7. Enfin, exécutons les commandes suivantes pour reconstruire l’image. Assurez-vous de supprimer d’abord l’image :
dockerhost$ docker rmi aftercaching dockerhost$ time docker build -t aftercaching .
…
Successfully tagged aftercaching:latest
real 0m33.942s
user 0m0.039s
sys 0m0.035s
Notez comment la construction suivante est plus rapide, même si nous n’utilisons pas le cache de construction de Docker. Cette technique est utile lorsque nous développons des images Docker de base pour notre équipe ou organisation. Les membres de l’équipe qui tentent de reconstruire notre image Docker exécuteront leurs versions 6,5 fois plus rapidement car ils peuvent télécharger des packages à partir du proxy de cache de notre organisation que nous avons préparé plus tôt. Les builds sur notre serveur d’intégration continue seront également plus rapides lors de l’enregistrement car nous avons déjà réchauffé le serveur de mise en cache pendant le développement.
Dans cette section, nous avons expliqué comment utiliser un serveur de mise en cache très spécifique. Voici quelques autres que nous pouvons utiliser, ainsi que leurs pages de documentation correspondantes :
- apt-cacher-ng : cela prend en charge la mise en cache de Debian, RPM et d’autres packages spécifiques à la distribution, et peut être trouvé à https://www.unix-ag.uni-kl.de/~bloch/acng .
- Sonatype Nexus : il prend en charge les packages Maven, Ruby Gems, PyPI et NuGet prêts à l’emploi. Il est disponible sur http://www.sonatype.org/nexus .
- Polipo : Il s’agit d’un proxy de mise en cache générique qui est utile pour le développement, et il peut être trouvé à http://www.pps.univ-paris-diderot.fr/~jch/software/polipo .
- Squid : Il s’agit d’un autre proxy de mise en cache populaire qui peut également fonctionner avec d’autres types de trafic réseau. Vous pouvez le rechercher sur http://www.squid-cache.org .
Dans la section suivante, nous examinerons quelques détails supplémentaires sur le fonctionnement des couches d’images de Docker et sur la façon dont elles affectent la taille de l’image résultante. Nous apprendrons ensuite comment optimiser ces couches d’images en exploitant le fonctionnement des images Docker.
Réduction de la taille de l’image Docker
Alors que nous continuons à travailler sur nos applications Docker, les tailles des images auront tendance à devenir de plus en plus grandes si nous ne faisons pas attention. La plupart des utilisateurs de Docker constatent que la taille des images Docker personnalisées de leur équipe atteint au moins 1 Go ou plus. Avoir des images plus grandes signifie que le temps de construction et de déploiement de notre application Docker augmentera également. En conséquence, les commentaires que nous obtenons pour déterminer le résultat de l’application que nous déployons sont réduits. Cela diminue les avantages de Docker, nous permettant de développer et de déployer nos applications en itérations rapides.
Chaînage des commandes
Les images Docker grossissent car certaines instructions sont ajoutées qui ne sont pas nécessaires pour créer ou exécuter une image. Les métadonnées et le cache de l’empaquetage sont les parties communes du code qui sont généralement augmentées en taille. Après avoir installé les packages nécessaires pour construire et exécuter notre application, ces packages téléchargés ne sont plus nécessaires. Les modèles d’instructions suivants dans un Dockerfile se trouvent couramment dans la nature (comme dans Docker Hub) pour nettoyer les images de ces fichiers inutiles des images Docker :
FROM debian:stretch
RUN echo deb http://httpredir.debian.org/debian stretch-backports main \
> /etc/apt/sources.list.d/stretch-backports.list
RUN apt-get update
RUN apt-get –no-install-recommends install -y openjdk-11-jre-headless
RUN rm -rfv /var/lib/apt/lists/*
Cependant, la taille d’une image Docker est essentiellement la somme de chaque image de couche individuelle ; c’est ainsi que fonctionnent les systèmes de fichiers union. Cela signifie que les étapes propres ne suppriment pas vraiment l’espace. Jetez un œil aux commandes suivantes :
dockerhost$ docker build -t fakeclean .
dockerhost$ docker history fakeclean
IMAGE CREATED CREATED BY SIZE
2fb3cfa78a67 3 minutes ago /bin/sh -c rm -rfv /var/lib/apt/l… 0B
5c914734e883 3 minutes ago /bin/sh -c apt-get –no-install-r… 220MB
f3d93082de54 4 minutes ago /bin/sh -c apt-get update 17.5MB
de762158876a 4 minutes ago /bin/sh -c echo deb http://httpre… 62B
d508d16c64cd 7 days ago /bin/sh -c #(nop) CMD [“bash”] 0B
<missing> 7 days ago /bin/sh -c #(nop) ADD file:4fec87… 101MB
Il n’y a pas de taille de couche négative, donc chaque instruction d’un Dockerfile ne peut que maintenir la taille de l’image constante ou l’augmenter. De plus, à mesure que chaque étape introduit des métadonnées, la taille totale continue d’augmenter.
Afin de réduire la taille totale de l’image, les étapes de nettoyage doivent être effectuées dans la même couche d’image, et la solution consiste donc à enchaîner les commandes de plusieurs instructions en une seule. Comme Docker utilise / bin / sh pour exécuter chaque instruction, nous pouvons utiliser l’opérateur && du shell Bourne pour effectuer le chaînage, comme suit :
FROM debian:stretch
RUN echo deb http://httpredir.debian.org/debian stretch-backports main \
> /etc/apt/sources.list.d/stretch-backports.list && \
apt-get update && \
apt-get –no-install-recommends install -y openjdk-11-jre-headless && \
rm -rfv /var/lib/apt/lists/*
Notez comment chaque couche individuelle est beaucoup plus petite maintenant. Comme la taille des couches individuelles a été réduite, la taille totale de l’image a également diminué. Maintenant, exécutez les commandes suivantes et jetez un œil à la sortie :
dockerhost$ docker build -t trueclean .
dockerhost$ docker history trueclean
IMAGE CREATED CREATED BY SIZE
d16c1aa0553a 3 minutes ago /bin/sh -c echo deb http://httpredir… 220MB
d508d16c64cd 7 days ago /bin/sh -c #(nop) CMD [“bash”] 0B
<missing> 7 days ago /bin/sh -c #(nop) ADD file:4fec879fd… 101MB
Séparation des images de génération et de déploiement
Une autre source de fichiers inutiles dans les images Docker est les dépendances de temps de construction. Les bibliothèques source, telles que les compilateurs et les fichiers d’en-tête source, ne sont nécessaires que lors de la création d’une application à l’intérieur d’une image Docker. Une fois l’application créée, ces fichiers ne sont plus nécessaires, car seuls les fichiers binaires compilés et les bibliothèques partagées associées sont nécessaires pour exécuter l’application.
Pour voir un exemple de cela, construisons l’application suivante qui est maintenant prête à être déployée sur un hôte Docker que nous avons préparé dans le cloud. L’arborescence source suivante est une simple application Web écrite en Go :
$ tree
.
├── Dockerfile
├── README.md
└── hello.go
0 directories, 3 files
Voici le contenu de hello.go décrivant l’application:
package main
import (
“fmt”
“net/http”
)
func handler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, “hello world”)
}
func main() {
http.HandleFunc(“/”, handler)
http.ListenAndServe(“:8080”, nil)
}
Le Dockerfile correspondant suivant montre comment créer le code source et exécuter le binaire résultant :
FROM golang:1.11-stretch
ADD hello.go hello.go
RUN go build hello.go
EXPOSE 8080
ENTRYPOINT [“./hello”]
Dans les prochaines étapes, nous vous montrerons comment la taille de l’image de cette application Docker devient grande :
1. Commençons par créer l’image Docker :
dockerhost $ docker build -t largeapp .
2. Ensuite, notons sa taille (823 Mo), comme indiqué dans le code suivant :
dockerhost$ docker build -t largeapp .
dockerhost$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
largeapp latest a10f9baee2e5 9 seconds ago 823MB
golang 1.11-stretch 901414995ecd 6 days ago 816MB
3. Pour collecter des données pour l’étape suivante, exécutons maintenant notre application en utilisant les éléments suivants :
dockerhost$ docker run –name large -d largeapp
4. Entrons maintenant dans le conteneur en cours d’exécution pour identifier la taille réelle de notre application, comme indiqué dans le code suivant :
dockerhost$ docker exec -it large /bin/sh
# ls -lh
total 6.3M
drwxrwxrwx. 2 root root 6 Feb 6 12:53 bin
-rwxr-xr-x. 1 root root 6.3M Feb 13 11:09 hello
-rw-r–r–. 1 root root 221 Feb 13 11:06 hello.go
drwxrwxrwx. 2 root root 6 Feb 6 12:53 src
L’un des avantages de l’écriture d’applications Go, et du code compilé en général, est que nous pouvons produire un seul binaire facile à déployer. La taille restante de l’image Docker est constituée des fichiers inutiles fournis par l’image Docker de base, tels que le système d’exploitation et le compilateur Go lui-même. Dans les étapes que nous avons exécutées précédemment, la surcharge provenant de l’image Docker de base crée une taille d’image totale qui est 100 fois la taille d’origine !
Nous pouvons optimiser l’image Docker finale déployée en production en compressant uniquement le binaire hello final et ses bibliothèques partagées. Suivez les étapes suivantes pour effectuer l’optimisation :
1. Tout d’abord, entrons à nouveau dans le conteneur exécutant notre application :
dockerhost$ docker exec -it large /bin/sh
2. Si le binaire hello était compilé en tant que bibliothèque statique, nous aurions maintenant terminé et nous pourrions passer à l’étape suivante. Cependant, l’outil Go crée des binaires partagés par défaut. Pour que le binaire fonctionne correctement, il a besoin des bibliothèques partagées. Exécutons la commande suivante dans notre conteneur pour répertorier ces dépendances :
# ldd hello
linux-vdso.so.1 (0x00007ffce3fda000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007ff980d1c000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ff98097d000)
/lib64/ld-linux-x86-64.so.2 (0x00007ff980f39000)
3. Avec cette connaissance, nous pouvons maintenant mettre à jour notre Dockerfile pour utiliser un processus de construction en plusieurs étapes. Nous allons copier notre binaire et ses dépendances de bibliothèque à la prochaine étape de construction :
FROM golang:1.11-stretch
ADD hello.go hello.go
RUN go build hello.go
# Good to have a base image that has some debugging tools
FROM busybox
COPY –from=0 /go/hello /app/hello
COPY –from=0 /lib/x86_64-linux-gnu/libpthread.so.0 \
/lib/x86_64-linux-gnu/libpthread.so.0
COPY –from=0 /lib/x86_64-linux-gnu/libc.so.6 /lib/x86_64-linux-gnu/libc.so.6
COPY –from=0 /lib64/ld-linux-x86-64.so.2 /lib64/ld-linux-x86-64.so.2
WORKDIR /app
EXPOSE 8080
ENTRYPOINT [“./hello”]
4. Reconstruisons maintenant notre image Docker. Comme nous pouvons le voir sur la sortie suivante, la taille d’image résultante est beaucoup plus petite :
dockerhost$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
binary-only latest 5c33cc2b31cd 4 minutes ago 9.74MB
largeapp latest a10f9baee2e5 21 minutes ago 823MB
golang 1.11-stretch 901414995ecd 6 days ago 816MB
busybox latest 3a093384ac30 6 weeks ago 1.2MB
La même approche peut également être utilisée pour créer d’autres applications compilées, telles que les logiciels normalement installés à l’aide des combinaisons. /configure && make && make install. Nous pouvons faire de même pour les langages interprétés, tels que Python, Ruby ou PHP ; cependant, il faudra un peu plus de travail pour créer une image Ruby Docker d’exécution à partir d’une image Ruby Docker de génération. Un bon moment pour commencer à étudier ce type d’optimisation est lorsque la livraison de nos applications devient trop longue car les images sont trop grandes pour un flux de travail de développement durable.
Guide d’optimisation
Les techniques spécifiées dans ce chapitre ne sont pas complètes ; d’autres moyens d’atteindre ces objectifs seront certainement trouvés à mesure que de plus en plus de personnes découvriront comment utiliser Docker pour leurs applications. Plus de techniques surgiront également à mesure que Docker lui-même mûrit et développe plus de fonctionnalités. Le facteur directeur le plus important pour ces optimisations est de nous demander si nous obtenons vraiment les avantages de l’utilisation de Docker. Voici quelques bons exemples de questions à poser :
- Le temps de déploiement s’améliore-t-il ?
- L’équipe de développement reçoit-elle suffisamment de commentaires de la part de l’équipe des opérations en fonction de ce qu’elle a appris lors de l’exécution de notre application ?
- Sommes-nous capables d’itérer sur de nouvelles fonctionnalités assez rapidement pour intégrer les nouveaux commentaires que nous avons découverts des clients utilisant notre application ?
En gardant à l’esprit notre motivation et notre objectif d’utiliser Docker, nous pouvons trouver nos propres moyens d’améliorer nos flux de travail.
Résumé
Dans ce chapitre, vous avez appris plus sur la façon dont Docker crée des images et appliqué ces connaissances pour améliorer plusieurs facteurs, tels que le temps de déploiement, le temps de génération et la taille de l’image. Nous avons également appris quelques points pour nous guider davantage dans notre parcours d’optimisation.
Dans le chapitre suivant, nous prendrons ces images Docker optimisées que nous avons construites et les déploierons.
Déployer des conteneurs
Dans ce chapitre, nous allons utiliser Jenkins, exécuté dans un conteneur Docker, pour déclencher une génération d’une application, la pousser vers Docker Hub, puis la déployer dans notre cluster Docker Swarm.
Dans ce chapitre, nous couvrirons les sujets suivants :
- Création d’une image Jenkins personnalisée
- Déploiement de Jenkins dans notre cluster Docker Swarm
- Configuration de Jenkins pour interagir avec notre cluster Docker Swarm et notre compte Docker Hub
- Création et déploiement d’une application simple à l’aide d’un pipeline en trois étapes
Déploiement et configuration de Jenkins
Jenkins a initialement commencé sa vie en tant que serveur de construction open source, initialement appelé Hudson (le nom a été changé à la suite d’un différend avec Oracle), dont le seul but était de compiler des applications Java. Depuis sa sortie en 2004, son rôle a été considérablement élargi et il est désormais considéré comme l’une des principales solutions d’intégration continue et de livraison continue disponibles et pas seulement comme un serveur de génération pour les applications Java.
Avant de pouvoir déployer notre application de test, nous devons déployer et configurer Jenkins. Voici les étapes à suivre pour déployer et configurer un serveur Jenkins complet.
Déploiement du conteneur Jenkins
Avant de lancer et de configurer notre conteneur Jenkins dans notre cluster Docker Swarm, nous devons créer une image. Pour cela, nous utiliserons l’image Jenkins officielle comme base, puis nous ajouterons quelques-unes de nos propres personnalisations :
1. Nous allons commencer par préparer un fichier de configuration Jenkins ; le fichier doit être nommé init.groovy.d / plugins.groovy . Ce fichier sera chargé au démarrage du conteneur et demandera à Jenkins d’installer quelques-uns des prérequis dont nous avons besoin. Le contenu du fichier doit être le suivant :
import jenkins.model.Jenkins;
pm = Jenkins.instance.pluginManager
uc = Jenkins.instance.updateCenter
uc.updateAllSites()
installed = false
[“git”, “workflow-aggregator”].each {
if (! pm.getPlugin(it)) {
deployment = uc.getPlugin(it).deploy(true)
deployment.get()
installed = true
}
}
if (installed) {
Jenkins.instance.restart()
}
2. Maintenant que nous avons notre fichier init.groovy.d / plugins.groovy , nous pouvons passer à notre image Docker réelle, puis placer le contenu suivant dans un fichier appelé Dockerfile . Comme vous pouvez le voir, nous utilisons la version de support à long terme de l’image Jenkins, qui peut être trouvée à https://hub.docker.com/r/jenkins/jenkins. Une autre chose intéressante à noter est que nous installons également Docker lui-même dans l’image ; nous le faisons pour que Jenkins ait un moyen d’interagir avec notre cluster Docker Swarm. Nous verrons comment configurer cela plus tard dans le chapitre :
FROM jenkins/jenkins:lts
ARG docker_version=18.09.5
ARG docker_tarball=https://download.docker.com/linux/static/stable/x86_64/docker-$docker_version.tgz
LABEL com.docker.version=$docker_version
USER root
RUN cd /usr/local/bin && \
curl -s $docker_tarball | tar xz docker/docker –strip-components=1
USER jenkins
COPY init.groovy.d/plugins.groovy \
/usr/share/jenkins/ref/init.groovy.d/plugins.groovy
3. Maintenant que nous avons les fichiers de configuration de base en place, nous pouvons créer notre image Jenkins Docker et la pousser vers Docker Hub à l’aide des commandes suivantes. N’oubliez pas de vous assurer que vous remplacez hubuser par votre propre nom d’utilisateur Docker Hub :
$ docker build -t hubuser/jenkins:latest .
$ docker push hubuser/jenkins:latest
4. Avant de lancer nos conteneurs Jenkins, nous devons préparer une définition de service dans un fichier de composition. Créez un fichier appelé docker-compose.yml et entrez ce qui suit, en vous assurant à nouveau de mettre à jour hubuser pour qu’il soit celui de votre propre nom d’utilisateur Docker Hub :
version: ‘3.7’
services:
jenkins:
image: hubuser/jenkins:latest
ports:
– ‘8080:8080’
deploy:
replicas: 1
5. Nous devrions pouvoir déployer Jenkins en utilisant la définition de service que nous venons de créer en exécutant le code suivant :
$ docker stack deploy jenkins –compose-file docker-compose.yml
Comme nous avons demandé à Jenkins de faire une configuration initiale en utilisant le fichier init.groovy.d / plugins.groovy lors de son premier démarrage, le lancement et le téléchargement des plugins supplémentaires peuvent prendre quelques instants; vous pouvez vérifier l’état de la pile en exécutant le code suivant:
$ docker stack ls
$ docker stack services jenkins
Une fois que vous voyez les répliques 1/1, votre conteneur Jenkins devrait être prêt et nous pouvons passer à la fin de l’installation dans notre navigateur.
Fin de la configuration Jenkins
Lorsque vous ouvrez votre navigateur et accédez à http://dockerhost:8080, en vous assurant de remplacer dockerhost par l’adresse IP de votre hôte Docker Swarm, vous devriez être accueilli avec une page qui ressemble à ceci:
Comme vous pouvez le voir, une des choses que Jenkins fait lors de son premier démarrage est de se sécuriser – pour une bonne raison aussi ; si votre instance Jenkins était accessible au public, vous ne voudriez pas qu’elle soit exposée avec un nom d’utilisateur et un mot de passe par défaut configurés, car il existe des bots qui ont été créés pour cibler et compromettre l’installation de Jenkins, qui attendent d’être configurés.
Pour trouver le mot de passe administrateur, qui est une chaîne alphanumérique de 32 caractères, nous devons simplement exécuter les deux commandes suivantes :
$ container=jenkins_jenkins.1.$(docker service ps jenkins_jenkins -q)
$ docker exec $container cat /var/jenkins_home/secrets/initialAdminPassword
La première commande génère le nom complet du conteneur et la deuxième commande utilise la commande docker exec pour imprimer le contenu du fichier / var / jenkins_home / secrets / initialAdminPassword à l’écran ou, dans notre cas, sortir le mot de passe.
En entrant le mot de passe administrateur dans l’espace prévu et en cliquant sur le bouton Continuer, vous accédez à une page qui vous donne deux choix :
De là, sélectionnez le deuxième choix, sélectionnez les plugins à installer. Sur la page qui est ensuite chargée, vous avez le choix entre plusieurs options ; Cependant, comme nous avons installé les plugins dont nous avons besoin au premier démarrage de Jenkins, vous pourrez cliquer sur Aucun, qui se trouve dans le menu supérieur et désélectionne tout, puis cliquez sur le bouton Installer :
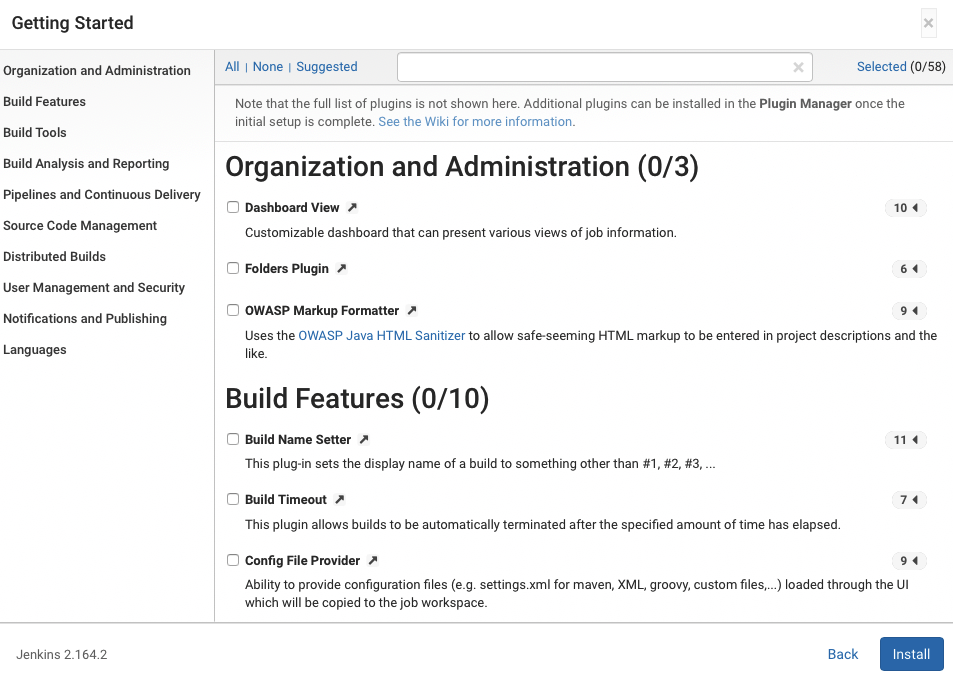
Comme il n’y a rien à installer, cela vous amènera à une page où vous pourrez créer votre propre utilisateur administrateur. Ici, vous pouvez entrer votre combinaison nom d’utilisateur / mot de passe préférée ou vous pouvez continuer à utiliser le nom d’utilisateur et le mot de passe administrateur qui ont été générés lors du premier lancement de Jenkins :
La dernière étape de la configuration consiste à confirmer l’URL Jenkins. Ceci est prérempli avec l’URL sur laquelle vous accédez actuellement à Jenkins ; pour la plupart des gens, ce sera parfait et vous pouvez cliquer sur le bouton Enregistrer et terminer pour terminer la configuration :
Cela devrait terminer la configuration et, selon le message à l’écran illustré dans la capture d’écran suivante, vous pouvez commencer à utiliser Jenkins :
Maintenant que vous avez une installation Jenkins fonctionnelle, nous pouvons commencer à vous parler de notre cluster Docker Swarm.
Configuration de nos informations d’identification Docker dans Jenkins
Il y a quelques étapes différentes pour fournir l’accès à notre cluster Swarm, ainsi qu’à notre compte Docker Hub, afin que notre conteneur Jenkins récemment déployé puisse créer, pousser et déployer des conteneurs pour nous.
Commençons par fournir les certificats requis pour accéder à notre cluster Docker Swarm. Vous pouvez saisir ces informations d’identification en accédant à http://dockerhost:8080/credentials/store/system/domain/_/newCredentials (n’oubliez pas de mettre à jour l’URL si nécessaire) ou en cliquant sur Credentials > System > Global credentials (sans restriction), puis en cliquant sur Ajouter des informations d’identification.
Sur le formulaire qui vous est présenté, définissez Kind sur Docker Host Certificate Authentication et le formulaire devrait changer, en demandant les détails suivants :
- Client Key: collez le contenu du fichier ~ / .docker / key.pem sur votre hôte Docker
- Client Certificate: collez le contenu du fichier ~ / .docker / cert.pem sur votre hôte Docker
- Server CA Certificate : collez le contenu du fichier ~ / .docker / ca.pem sur votre hôte Docker
- ID : Entrez docker-swarm
- Cliquez sur OK
Cela devrait ressembler à ceci :
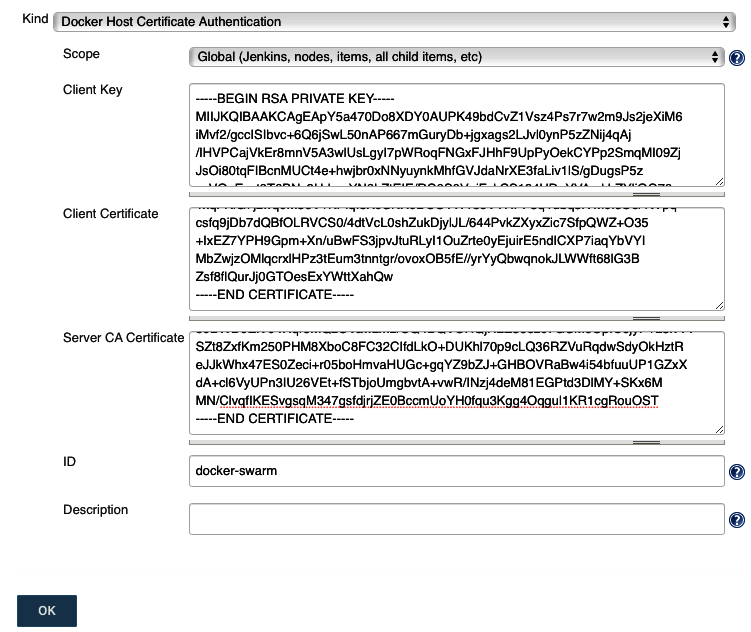
Rappelez-vous la référence à ces informations d’identification de docker-swarm secrètes, car nous les utiliserons plus tard. Ensuite, nous devons fournir à Jenkins nos informations d’identification Docker Hub. Pour ce faire, cliquez à nouveau sur Ajouter des informations d’identification. Cette fois, laissez le type à nom d’utilisateur avec mot de passe, qui devrait être l’option par défaut :
- Username: entrez votre nom d’utilisateur Docker Hub, par exemple, hubuser
- Password: entrez votre mot de passe Docker Hub
- Id : utiliser dockerhub – nous y ferons référence plus tard
Maintenant que nous avons ajouté les informations d’identification à notre installation Jenkins, nous sommes prêts à envisager de créer un pipeline Jenkins, qui utilisera ces informations d’identification et créera une application de test.
Construction et déploiement d’un conteneur
Maintenant que Jenkins a été configuré, nous devons décider d’une application à configurer et à déployer.
Préparer notre candidature
Si vous vous souvenez, au chapitre 4, Optimisation des images Docker, nous avons créé une application Go simple, qui imprime bonjour à l’écran lorsque vous l’ouvrez dans un navigateur. Dockerfile contenait une construction en plusieurs étapes qui ressemblait à ceci :
FROM golang:1.11-stretch
ADD hello.go hello.go
RUN go build hello.go
FROM busybox
COPY –from=0 /go/hello /app/hello
COPY –from=0 /lib/x86_64-linux-gnu/libpthread.so.0 \
/lib/x86_64-linux-gnu/libpthread.so.0
COPY –from=0 /lib/x86_64-linux-gnu/libc.so.6 /lib/x86_64-linux-gnu/libc.so.6
COPY –from=0 /lib64/ld-linux-x86-64.so.2 /lib64/ld-linux-x86-64.so.2
WORKDIR /app
EXPOSE 8080
ENTRYPOINT [“./hello”]
Le fichier hello.go contient les éléments suivants :
package main
import (
“fmt”
“net/http”
)
func handler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, “hello world”)
}
func main() {
http.HandleFunc(“/”, handler)
http.ListenAndServe(“:8080”, nil)
}
En plus des deux fichiers précédents, nous devons ajouter Jenkinsfile . Comme vous l’avez probablement deviné par le nom de fichier, il est similaire à un Dockerfile en ce qu’il définit la manière dont Jenkins doit construire notre application. Le fichier Jenkins de notre application est divisé en trois étapes de génération :
- Construire une image Docker : Cette étape crée l’image localement en utilisant le Dockerfile de notre application
- Publier sur Docker Hub : cette étape prend l’image créée par la première étape et la transmet à Docker Hub
- Déployer en production : cette dernière étape déploie notre application en utilisant l’image qui a été poussée vers Docker Hub :
node {
def app
stage(‘Build Docker Image’) {
checkout scm
docker.withServer(‘tcp://dockerhost:2376’, ‘docker-swarm’) {
app = docker.build(‘hubuser/jenkins-app:latest’)
}
}
stage(‘Publish to Docker Hub’) {
docker.withServer(‘tcp://dockerhost:2376’, ‘docker-swarm’) {
docker.withRegistry(“https://index.docker.io/v1/”, “dockerhub”) {
app.push(‘latest’)
}
}
}
stage(‘Deploy to Production’) {
docker.withServer(‘tcp://dockerhost:2376’, ‘docker-swarm’) {
sh “docker service update app –force –image ${app.id}”
}
}
}
Nous utiliserons Git pour distribuer la configuration de notre application. Il est composé des trois fichiers suivants, Dockerfile, hello.go et Jenkinsfile . Je recommanderais de cloner l’exemple de référentiel, qui peut être trouvé sur GitHub à https://github.com/dockerhp/jenkins-app et est accessible au public.
Comme vous pouvez le voir, les deux ensembles d’informations d’identification sont référencés dans Jenkinsfile , où nous devons interagir avec notre cluster Docker Swarm. Les informations d’identification de docker-swarm sont référencées, et, lorsque nous devons nous connecter au Docker Hub, nous référençons dockerhub . Cela signifie que, bien que votre fichier Jenkins soit accessible au public, vous n’exposez jamais réellement d’informations sensibles, telles que les certificats ou vos connexions Docker Hub dans le référentiel – tout est stocké en toute sécurité dans votre installation Jenkins.
Avant de progresser, vous devrez modifier le fichier Jenkins et vous assurer que toutes les références de tcp://dockerhost:2376 sont mises à jour pour refléter l’IP / nom d’hôte de votre hôte Docker et que hubuser est mis à jour pour refléter votre propre utilisateur Docker Hub. Enfin, assurez-vous que votre fichier Jenkins est validé et poussé vers votre référentiel Git.
Une fois mis à jour, nous pouvons déployer le service, qui finira par héberger notre application en exécutant ce qui suit :
$ docker service create –name app –publish 80:8080 nginx
Comme vous l’avez peut-être remarqué, nous déployons l’image officielle NGINX et non notre application ; ne vous inquiétez pas, la troisième étape de la construction la remplace par l’image correcte. Vous pouvez tester rapidement le déploiement en exécutant la commande suivante :
$ curl http://dockerhost
curl: (7) Failed connect to dockerhost:80; Connection refused
Comme vous pouvez le voir, cela a échoué ! Cependant, c’est normal, car nous n’avons pas vraiment configuré correctement NGINX. Dans la section suivante, nous allons créer un travail Jenkins, qui utilisera le pipeline défini dans notre fichier Jenkins pour enfin déployer notre application.
Création d’un travail Jenkins
Nous avons atteint la dernière partie de notre déploiement. Ici, nous allons rassembler tous les bits que nous avons configurés jusqu’à présent dans un pipeline de construction qui construira et déploiera notre application. Pour commencer, nous devons créer un nouvel emploi ; vous pouvez le faire en allant sur http://dockerhost:8080/newJob. Ici, vous serez présenté avec cinq types différents d’emplois Jenkins :
Sur cette page, entrez un nom d’élément d’application, sélectionnez Pipeline et cliquez sur OK.
Sur la page qui se charge, il existe plusieurs options, faites défiler vers le bas en passant par Général, Générer des déclencheurs et Options de projet avancées jusqu’à Pipeline.
Par défaut, la définition aura le script Pipeline sélectionné. Comme notre pipeline est en cours de définition dans un fichier Jenkins hébergé dans notre référentiel Git, mettez à jour la définition vers le script Pipeline à partir de SCM. Cela mettra à jour le formulaire avec le menu déroulant à côté de SCM indiquant Aucun. Mettez à jour ceci pour que Git soit sélectionné.
Dans la zone URL du référentiel, entrez l’URL HTTPS de votre référentiel Git, par exemple, https://github.com/dockerhp/jenkins-app.git. Laissez tous les autres champs à leur valeur par défaut et cliquez sur Enregistrer.
Cela devrait vous amener à une page qui ressemble à ceci :
Il ne vous reste plus qu’à cliquer sur Build Now .
Exécution du pipeline
Lorsque vous cliquez sur Créer maintenant, vous devriez voir un travail apparaître en bas du menu de gauche, cliquez sur le numéro du travail, puis la sortie de la console vous donnera une vue en temps réel du travail en cours d’exécution et vous devriez voir quelque chose semblable à ce qui suit :
Une fois terminé, le retour à l’application dans Jenkins devrait vous montrer quelque chose comme la page suivante :
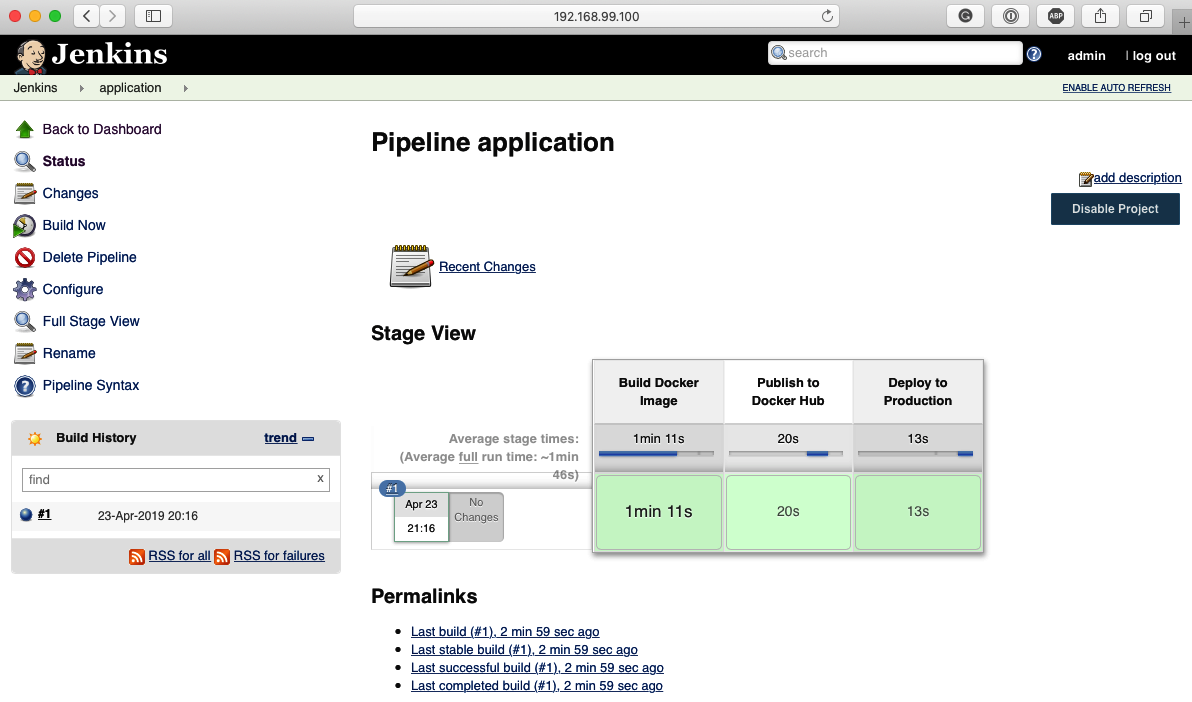
Comme vous pouvez le voir, nos trois étapes de construction se sont toutes déroulées avec succès. Si, pour une raison quelconque, votre build a échoué, vous devriez pouvoir consulter la sortie de la console. Je vous recommande de mettre à jour correctement l’URL Docker et le nom d’utilisateur Docker Hub dans le fichier Jenkins – si vous devez réexécuter la génération, assurez-vous que vos modifications sont validées, poussez-les vers GitHub, puis cliquez à nouveau sur Build Now.
Une fois déployée, l’exécution de la commande suivante devrait retourner bonjour au monde :
$ curl http://dockerhost
hello world
Bien qu’il s’agisse d’un exemple vraiment basique, il est difficile de voir comment cela peut être avantageux ; Par exemple, sans beaucoup plus d’efforts, vous pouvez configurer un webhook dans Jenkins pour surveiller votre référentiel GitHub et, chaque fois qu’un changement est détecté, votre pipeline peut être automatiquement déclenché pour créer, publier et déployer votre conteneur mis à jour.
Résumé
Dans ce chapitre, nous avons examiné comment utiliser Jenkins pour créer, distribuer et déployer notre application conteneurisée. Pour plus d’informations sur Jenkins, consultez le site Web du projet à https://jenkins.io/.
Dans le chapitre suivant, nous commencerons à faire des tests de performances et à évaluer comment nos applications Docker déployées se comportent sous charge.
Analyse comparative
Pour optimiser nos applications Docker, il est important de valider les paramètres que nous avons réglés. Le benchmarking est un moyen expérimental d’identifier si les éléments que nous avons modifiés dans nos conteneurs Docker ont fonctionné comme prévu. Notre application aura un large éventail d’options à optimiser. Les hôtes Docker qui les exécutent ont également leur propre ensemble de paramètres, tels que la mémoire, la mise en réseau, le processeur et le stockage. Selon la nature de notre application, un ou plusieurs de ces paramètres peuvent devenir un goulot d’étranglement. Disposer d’une série de tests pour valider chaque composant avec des benchmarks est important pour guider notre stratégie d’optimisation.
De plus, en créant des tests de performances appropriés, nous pouvons identifier les limites de la configuration actuelle de notre application Docker. Avec ces informations, nous pouvons commencer à explorer les paramètres d’infrastructure, tels que la mise à l’échelle de notre application en les déployant sur davantage d’hôtes Docker. Nous pouvons également utiliser ces informations pour faire évoluer la même application en déplaçant notre charge de travail vers un hôte Docker avec un stockage, une mémoire ou un processeur plus élevé, et lorsque nous avons des déploiements de cloud hybrides, nous pouvons utiliser ces mesures pour identifier le fournisseur de cloud qui fournit notre application.
Il est important de mesurer la façon dont notre application répond à ces critères de référence lors de la planification de la capacité requise pour notre infrastructure Docker. En créant une charge de travail de test simulant les conditions de pointe et normales, nous pouvons prédire comment notre application fonctionnera une fois qu’elle sera mise en production. Notez que nous pouvons facilement appliquer les enseignements tirés de nos benchmarks, car nous avons un moyen fiable et cohérent de déployer des conteneurs à partir du chapitre 5, Déployer des conteneurs.
Dans ce chapitre, nous aborderons les sujets suivants pour comparer une application Web simple déployée dans notre infrastructure Docker :
- Configuration d’Apache JMeter pour l’analyse comparative
- Création et conception d’une charge de travail de référence
- Analyse des performances des applications
Configuration d’Apache JMeter
Apache JMeter est une application populaire utilisée pour tester les performances des serveurs Web. Outre le test de charge des serveurs Web, le projet open source s’est développé pour prendre en charge le test d’autres protocoles réseau, tels que LDAP, FTP et même des paquets TCP bruts. Il est hautement configurable et suffisamment puissant pour concevoir des charges de travail complexes de différents modèles d’utilisation. Cette fonctionnalité peut être utilisée pour simuler des milliers d’utilisateurs visitant soudainement notre application Web, induisant ainsi un pic de charge.
Une autre caractéristique attendue dans tout logiciel de test de charge est ses fonctions de capture et d’analyse des données. JMeter dispose d’une telle variété de fonctionnalités d’enregistrement, de traçage et d’analyse de données que nous pouvons explorer les résultats de nos benchmarks immédiatement. Enfin, il dispose d’une grande variété de plugins qui peuvent déjà avoir le modèle de charge, l’analyse ou la connexion réseau que nous prévoyons d’utiliser.
Pour plus d’informations sur les fonctionnalités et l’utilisation d’Apache JMeter, consultez son site Web à l’adresse http://jmeter.apache.org.
Dans cette section, nous allons déployer un exemple d’application pour comparer et préparer notre poste de travail pour exécuter notre premier test basé sur JMeter.
Déployer un exemple d’application
Nous pouvons également apporter notre propre application Web que nous voulons comparer si nous le souhaitons. Mais pour le reste de ce chapitre, nous comparerons l’application suivante décrite dans cette section. L’application est une simple application Web Ruby déployée à l’aide d’Unicorn, un serveur d’applications Ruby populaire. Il reçoit le trafic via une socket Unix de NGINX. Cette configuration est très typique de la plupart des applications Ruby trouvées dans la nature.
Dans cette section, nous allons déployer cette application Ruby dans un hôte Docker appelé webapp. Nous utiliserons des hôtes Docker distincts pour l’application, les outils de référence et la surveillance. Cette séparation est importante pour que le benchmark et l’instrumentation de surveillance que nous utilisons n’affectent pas les résultats du benchmark.
Les prochaines étapes nous montrent comment créer et déployer notre simple pile d’applications Web Ruby :
1. Créez d’abord l’application Ruby en créant le fichier Rack config.ru suivant :
app = proc do |env|
Math.sqrt rand
[200, {}, %w(hello world)]
end
run app
2. Ensuite, nous empaquetons l’application en tant que conteneur Docker avec le Dockerfile suivant :
FROM ruby:2.6
RUN gem install –no-doc unicorn rack
WORKDIR /app
COPY config.ru /app/config.ru
CMD unicorn -l 8000
3. Générez l’application et accédez à Docker Hub à l’aide du code suivant :
$ docker build -t hubuser/benchmark-app .
$ docker push hubuser/benchmark-app
4. Le dernier composant sera un fichier compose.yml qui décrira comment notre application s’exécutera à l’intérieur de notre cluster Docker Swarm, comme indiqué dans le code suivant :
—
version: ‘3.7’
services:
web:
image: aespinosa/benchmark-app
ports:
– 8000:8000
# Set for debugging and testing purposes
networks:
default:
driver: overlay
attachable: true
À la fin, nous aurons les fichiers affichés dans la capture d’écran suivante dans notre base de code :

Maintenant que notre application est prête, déployons et testons notre application en suivant les étapes suivantes :
1. Tout d’abord, déployons notre application en exécutant la commande suivante:
dockerhost$ docker stack deploy app -c compose.yml
2. Ensuite, réalisons un test simple pour déterminer si notre application fonctionne correctement:
$ curl http://dockerhost:8000
hello world
Nous avons maintenant terminé de préparer l’application que nous voulons comparer. Dans la section suivante, nous préparerons notre poste de travail pour effectuer les tests de performances en installant Apache JMeter.
Installation de JMeter
Pour le reste de ce chapitre, nous utiliserons Apache JMeter version 5.1 pour effectuer nos tests de performances. Dans cette section, nous allons le télécharger et l’installer sur notre poste de travail. Suivez les étapes suivantes pour configurer correctement JMeter:
1. Pour commencer, accédez à la page Web de téléchargement de JMeter à l’adresse http://jmeter.apache.org/download_jmeter.cgi.
2. Sélectionnez le lien pour apache-jmeter-5.1.tgz pour commencer le téléchargement du binaire.
3. Une fois le téléchargement terminé, extrayez l’archive tar en tapant la commande suivante :
$ tar -xzf apache-jmeter-5.1.tgz
4. Ensuite, nous ajouterons le répertoire bin / à notre variable $ PATH afin que JMeter puisse être facilement lancé à partir de la ligne de commande. Pour ce faire, nous allons taper la commande suivante dans notre Terminal :
$ export PATH=$PATH:$(pwd)/apache-jmeter-5.1/bin
5. Enfin, lançons JMeter en tapant la commande suivante :
$ jmeter
Nous allons maintenant voir l’interface utilisateur JMeter, comme indiqué dans la capture d’écran suivante :
Nous sommes maintenant prêts à écrire la référence de notre application !
Apache JMeter est une application Java. Selon le site Web de JMeter, il nécessite au moins Java 8 pour fonctionner. Assurez-vous que vous disposez d’un environnement d’exécution Java (JRE) correctement installé avant d’installer JMeter.
Si nous étions dans un environnement macOS X, nous pourrions utiliser Homebrew et taper simplement la commande suivante :
$ brew install jmeter
Pour les autres plates-formes, les instructions décrites précédemment devraient être suffisantes pour commencer. Pour plus d’informations sur l’installation de JMeter, consultez http://jmeter.apache.org/usermanual/get-started.html.
Création d’une charge de travail de référence
La rédaction de repères pour une application est un domaine ouvert à explorer. Apache JMeter peut être écrasant au début : il a plusieurs options à régler afin d’écrire nos benchmarks. Pour commencer, nous pouvons utiliser l’histoire de notre application comme point de départ. Voici quelques-unes des questions que nous pouvons nous poser :
- Que fait notre application ?
- Quelle est la démographie de nos utilisateurs ?
- Comment interagissent-ils avec notre application ?
En commençant par les questions précédentes, nous pouvons ensuite les traduire en demandes réelles que nous pouvons utiliser pour tester notre application.
Dans l’exemple d’application que nous avons écrit, nous avons une application Web qui affiche Hello World à nos utilisateurs. Dans les applications Web, nous sommes généralement intéressés par le débit et le temps de réponse. Le débit fait référence au nombre d’utilisateurs qui peuvent recevoir Hello World à la fois. Le temps de réponse décrit le délai avant que l’utilisateur ne reçoive le message Hello World à partir du moment où il l’a demandé.
Dans cette section, nous allons créer une référence préliminaire dans Apache JMeter. Ensuite, nous commencerons à analyser nos premiers résultats avec les outils d’analyse de JMeter et la pile de surveillance que nous avons déployée au chapitre 3, Surveillance Docker. Après cela, nous allons itérer sur les repères que nous avons développés et les ajuster. De cette façon, nous saurons que nous évaluons correctement notre application.
Création d’un plan de test dans JMeter
Une série de benchmarks dans Apache JMeter est décrite dans un plan de test. Un plan de test décrit une série d’étapes que JMeter exécutera, telles que l’envoi de demandes à une application Web. Chaque étape d’un plan de test est appelée un élément. Ces éléments eux-mêmes peuvent également avoir un ou plusieurs éléments. Au final, notre plan de test ressemblera à un arbre – une hiérarchie d’éléments pour décrire le benchmark que nous voulons pour notre application.
Pour ajouter un élément dans notre plan de test, il suffit de cliquer avec le bouton droit sur l’élément parent que nous voulons, puis de sélectionner Ajouter. Cela ouvre un menu contextuel d’éléments qui peuvent être ajoutés à l’élément parent sélectionné. Dans la capture d’écran suivante, nous ajoutons un élément Thread Group à l’élément principal, Test Plan, comme indiqué dans la capture d’écran suivante :

Les prochaines étapes nous montrent comment créer un plan de test conduisant le benchmark que nous voulons :
1. Tout d’abord, renommons le plan de test comme quelque chose de plus approprié. Cliquez sur l’élément Plan de test ; cela mettra à jour la fenêtre principale de JMeter sur la droite. Dans le champ de formulaire intitulé Nom, définissez la valeur sur Capacité de licorne.
2. Dans le cadre du plan de test Unicorn Capacity, créez un groupe de threads. Nommez les utilisateurs de cette application. Nous allons configurer ce groupe de threads pour envoyer 10000 demandes à notre application à partir d’un seul thread au début. Utilisez les paramètres suivants pour remplir le formulaire de configuration de ce paramètre :
- Nombre de Threads : 1
- Période de montée en puissance : 0 seconde
- Nombre de boucles : 10000 fois
Lorsque nous commençons à développer nos plans de test, un faible nombre de boucles est utile. Au lieu de 10000 boucles, nous pouvons commencer par 100 ou même 10 à la place. Nos repères sont plus courts et nous obtenons un feedback immédiat lors de son développement, même dès la prochaine étape. Lorsque nous avons terminé l’ensemble du plan de test, nous pouvons toujours le rétablir et le régler plus tard pour générer plus de demandes.
3. Ensuite, sous le groupe de threads Application Users , nous créons la demande réelle en ajoutant Sampler , HTTP Request . Voici la configuration dans laquelle nous définissons les détails de la manière dont nous faisons une demande à notre application Web :
- Nom : accédez à http://dockerhost:8000/
- Nom du serveur : dockerhost
- Numéro de port : 8000
4. Dans notre plan de test, nous allons maintenant décrire comment enregistrer les résultats du test en ajoutant un écouteur sous le plan de test Unicorn Capacity. Pour cela, nous allons ajouter un enregistreur de données simple et le nommer Enregistrer le résultat. Nous définissons le champ Nom de fichier sur result.jtl pour enregistrer nos résultats de référence dans ledit fichier. Nous nous référerons à ce fichier ultérieurement lorsque nous analyserons le résultat du benchmark.
5. Enfin, sauvegardons le plan de test que nous avons créé en allant dans Fichier puis Enregistrer. Pour le nom de fichier, appelons notre plan de test benchmark.jmx.
Maintenant, nous avons une charge de travail de référence qui génère 10 000 requêtes HTTP vers http://dockerhost:8000/. Voici une capture d’écran de JMeter lorsque nous avons créé notre plan de test :

Enfin, il est temps d’exécuter notre référence. Quittons l’interface utilisateur JMeter et revenons à notre terminal. Nous allons taper la commande suivante pour effectuer le benchmark réel :
$ jmeter -n -t benchmark.jmx
Après avoir exécuté le test, les résultats du test ont été enregistrés dans un fichier appelé result.jtl , que nous avons utilisé lors de l’élaboration de ce plan de test plus tôt. Nous examinerons ces résultats en utilisant les outils d’analyse de JMeter dans la section suivante.
Il existe différents types d’éléments qui peuvent être placés dans un plan de test JMeter. Outre les trois éléments que nous avons utilisés précédemment pour créer une référence de base pour notre application, il y en a plusieurs autres qui régulent les demandes, effectuent d’autres demandes réseau et analysent les données.
Une liste complète des éléments du plan de test et leurs descriptions se trouve sur la page JMeter à http://jmeter.apache.org/usermanual/component_reference.html .
Analyse des résultats de référence
Dans cette section, nous analyserons les résultats de référence et identifierons comment les 120 000 demandes ont affecté notre application. Lors de la création de tests de performances d’applications Web, deux choses nous intéressent généralement :
- Combien de demandes notre application peut-elle gérer à la fois ?
- Pendant combien de temps chaque demande est-elle traitée par notre application ?
Ces deux mesures de performances Web de bas niveau peuvent facilement se traduire par les implications commerciales de notre application. Par exemple, combien de clients utilisent notre application ? Un autre est, comment perçoivent-ils la réactivité de notre application du point de vue de l’expérience utilisateur ? Nous pouvons corréler des métriques secondaires dans notre application telles que le CPU, la mémoire et le réseau pour déterminer la capacité de notre système.
Affichage des résultats des exécutions JMeter
Plusieurs éléments d’écoute de JMeter ont des fonctionnalités qui rendent les graphiques. L’activer lors de l’exécution du test est utile lors de l’élaboration du plan de test. Mais le temps mis par l’interface utilisateur pour rendre les résultats en temps réel, en plus des demandes de référence réelles, affecte les performances du test, c’est pourquoi il est préférable pour nous de séparer les composants d’exécution et d’analyse de notre référence. Dans cette section, nous allons créer un nouveau plan de test et examiner quelques éléments d’écoute JMeter pour analyser les données que nous avons acquises dans result.jtl.
Pour commencer notre analyse, nous créons d’abord un nouveau plan de test et nommons ce résultat d’analyse. Nous ajouterons divers éléments d’écoute sous cet élément parent du plan de test. Après cela, suivez les étapes suivantes pour ajouter divers écouteurs JMeter qui peuvent être utilisés pour analyser notre résultat de référence.
Calcul du débit
Pour notre première analyse, nous utiliserons l’écouteur Summary Report. Cet auditeur montrera le débit de notre application. Une mesure du débit montrera le nombre de transactions que notre application peut gérer par seconde. Après avoir chargé l’écouteur, remplissez le champ Nom de fichier en sélectionnant le fichier result.jtl que nous avons généré lors de l’exécution de notre test de performances. Pour l’exécution que nous avons effectuée plus tôt, la capture d’écran suivante montre que les 10100 requêtes HTTP ont été envoyées à http://dockerhost:8000/ à un débit de 7,1 requêtes par seconde :
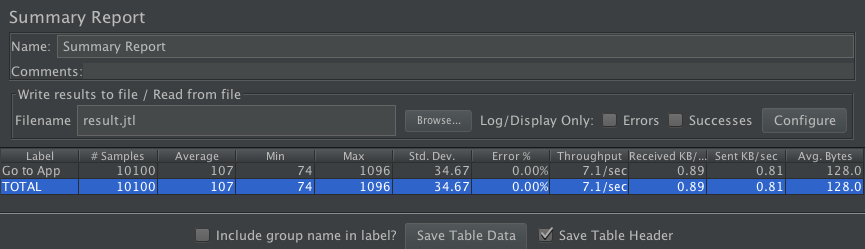
Nous pouvons également voir comment le débit a évolué au cours de notre benchmark avec l’écouteur Graph Results . Créez cet écouteur sous l’élément de plan de test Analyser les résultats et nommez-le Débit au fil du temps. Assurez-vous que seule la case Débit est cochée (n’hésitez pas à consulter les autres points de données plus tard, cependant). Après avoir créé l’écouteur, chargez à nouveau notre résultat de test result.jtl . La capture d’écran suivante montre comment le débit a évolué au fil du temps :
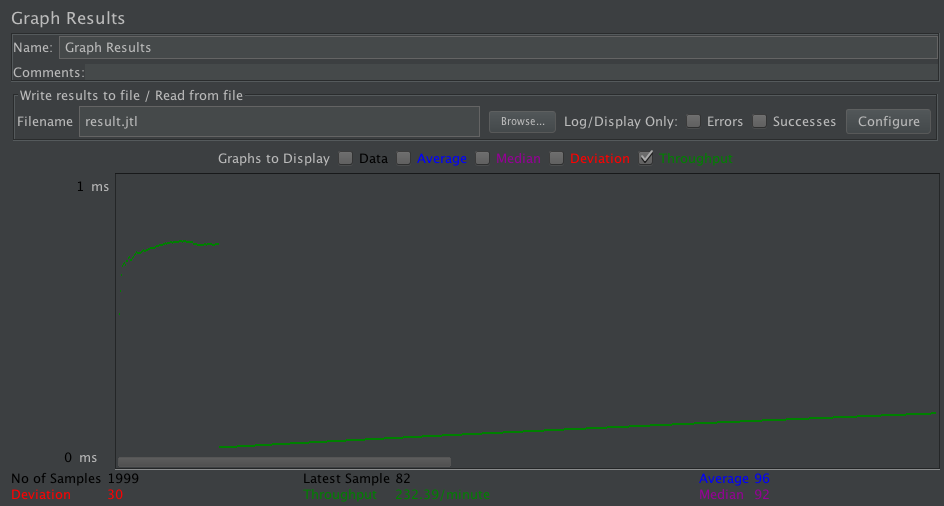
Comme nous pouvons le voir dans la capture d’écran précédente, le débit a commencé lentement pendant que JMeter tentait de réchauffer son pool de requêtes à thread unique. Mais après que notre indice de référence a continué de fonctionner, le niveau de débit s’est stabilisé. En ayant un grand nombre de comptages de boucles plus tôt dans notre groupe de threads, nous avons pu minimiser l’effet de la période de montée en puissance antérieure.
De cette façon, le débit affiché précédemment dans le rapport de synthèse est plus ou moins un résultat cohérent. Notez que l’écouteur Graph Results s’enroule autour de ses points de données après plusieurs échantillons.
Rappelez-vous que, dans l’analyse comparative, plus nous obtenons d’échantillons, plus nos observations seront précises !
Tracer le temps de réponse
Une autre mesure qui nous intéresse lorsque nous évaluons notre application est le temps de réponse. Le temps de réponse indique le temps que JMeter doit attendre avant de recevoir la réponse de la page Web de notre application. En termes d’utilisateurs réels, nous pouvons considérer cela comme le temps entre le moment où nos utilisateurs ont tapé l’URL de notre application Web lorsque tout était affiché dans leur navigateur Web (cela peut ne pas représenter l’état réel des choses si notre application affiche du JavaScript lent, mais pour l’application que nous avons faite plus tôt, cette analogie devrait suffire).
Pour afficher le temps de réponse de notre application, nous utiliserons l’écouteur Graph de temps de réponse. Comme paramètre initial, nous pouvons définir l’intervalle à 500 millisecondes. Cela fera la moyenne de certains des temps de réponse sur 500 millisecondes dans le fichier result.jtl. Dans le graphique suivant, vous pouvez voir que le temps de réponse de notre application est principalement d’environ 1 milliseconde :
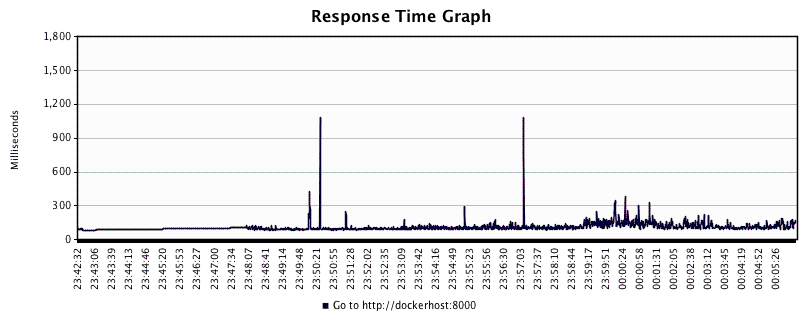
Si nous voulons afficher le temps de réponse avec plus de détails, nous pouvons réduire l’intervalle à 1 milliseconde. Notez que cela prendra plus de temps à s’afficher car l’interface utilisateur JMeter tente de tracer plus de points dans l’application. Parfois, lorsqu’il y a trop d’échantillons, JMeter peut se bloquer parce que notre station de travail n’a pas assez de mémoire pour afficher l’intégralité du graphique. Dans le cas de grands repères, il vaut mieux observer les résultats avec notre système de suivi. Nous examinerons ces données dans la section suivante.
Observation des performances à Grafana et Kibana
Nous pouvons être confrontés à une situation où notre poste de travail est si ancien que Java n’est pas en mesure de gérer l’affichage de 10 000 points de données dans son interface utilisateur JMeter. Pour résoudre ce problème, nous pouvons réduire la quantité de données dont nous disposons en générant moins de demandes dans notre référence ou en faisant la moyenne de certaines données, comme nous l’avons fait plus tôt lors de la représentation graphique du temps de réponse. Cependant, nous voulons parfois voir la pleine résolution de nos données. Cette vue complète est utile lorsque nous voulons inspecter les moindres détails du comportement de notre application. Heureusement, nous avons déjà un système de surveillance en place pour notre infrastructure Docker que nous avons construit au chapitre 3, Surveillance de Docker.
Notre application Ruby enregistre les demandes dans son flux de sortie standard dans un format appelé Apache Common Log Format (CLF). Ces événements sont capturés par notre démon Docker et envoyés au service Logstash que nous avons créé au chapitre 3, Surveillance de Docker. Une fois que le collecteur Logstash GELF a reçu les journaux, ils sont transférés et stockés dans notre service Elasticsearch. Nous pouvons ensuite utiliser la fonction de visualisation de Kibana pour examiner le débit de notre application. L’analyse suivante a été effectuée en comptant le nombre d’entrées de journal d’accès reçues par Elasticsearch par seconde :
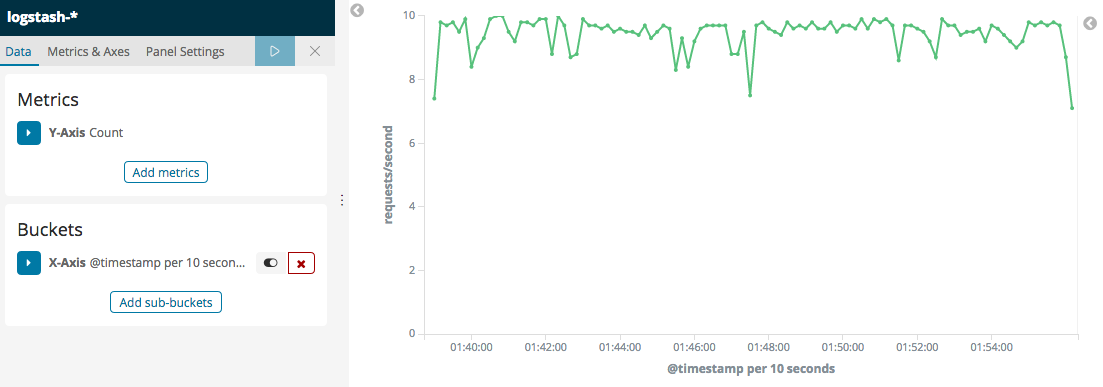
Nous pouvons également tracer le temps de réponse de notre application au cours du benchmark dans Kibana. Pour ce faire, nous devons mettre à jour notre service Logstash avec les étapes suivantes :
1. Tout d’abord, nous devons mettre à jour le fichier logstash.conf qui configure notre service Logstash. Nous allons ajouter le filtre grok {} comme suit :
# input { … }
# output { … }
filter {
if [container_name] =~ /app_web/ {
grok {
match => {
“message” => “%{HTTPD_COMMONLOG}\ %{NUMBER:response_time:float}”
}
}
}
}
Les plug-ins de filtrage de Logstash sont utilisés pour traiter les événements de manière intermédiaire avant qu’ils n’atteignent notre point de terminaison de stockage cible, comme Elasticsearch. Il transforme les données brutes, telles que les lignes de texte, en un schéma de données plus riche en JSON que nous pouvons ensuite utiliser plus tard pour une analyse plus approfondie. Pour plus d’informations sur les plug-ins de filtre Logstash, rendez-vous sur https://www.elastic.co/guide/en/logstash/current/filter-plugins.html.
2. Ensuite, nous allons redéployer notre service Logstash. Les commandes suivantes recréeront Logstash :
$ docker service rm logging_logstash
$ docker config rm logging_logstash.conf
$ docker stack deploy logging -c compose-logging.yml
Les configurations Docker sont des objets immuables à l’intérieur d’un cluster Docker Swarm. C’est pourquoi nous avons dû recréer le service Logstash.
3. Maintenant que nous avons notre nouvelle pile de journalisation, réexécutons notre référence :
$ jmeter -n -t benchmark.jmx
Maintenant que nous avons extrait les temps de réponse de notre application Ruby, nous pouvons tracer ces points de données dans une visualisation Kibana. Ce qui suit est une capture d’écran de Kibana montrant le temps de réponse moyen par seconde de l’indice de référence que nous avons exécuté plus tôt :
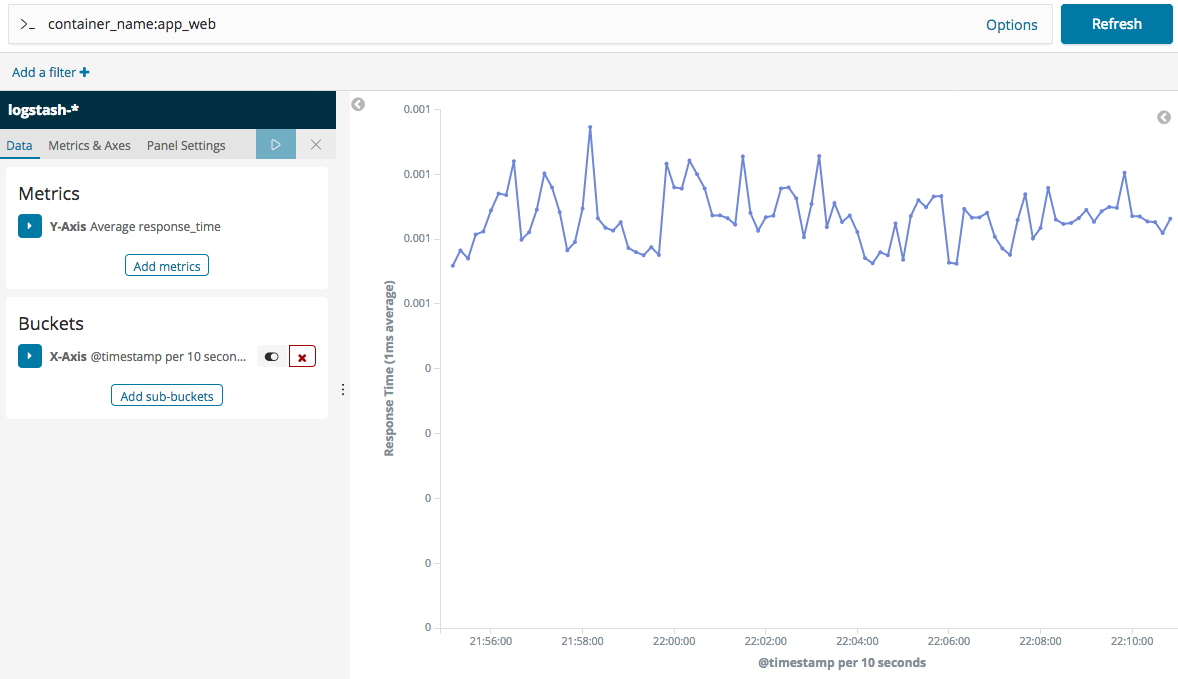
Un autre résultat que nous pouvons explorer est de savoir comment l’utilisation du processeur de notre application a répondu à notre référence. Nous pouvons effectuer la requête Prometheus suivante dans notre tableau de bord Grafana:
rate(
container_cpu_user_seconds_total{
container_label_com_docker_swarm_service_name=”app_web”
}
[1m])
+ rate(
container_cpu_system_seconds_total{
container_label_com_docker_swarm_service_name=”app_web”
}
[1m])
Comme nous pouvons le voir dans le graphique suivant, le processeur a augmenté au moment où notre application a commencé à recevoir des demandes :
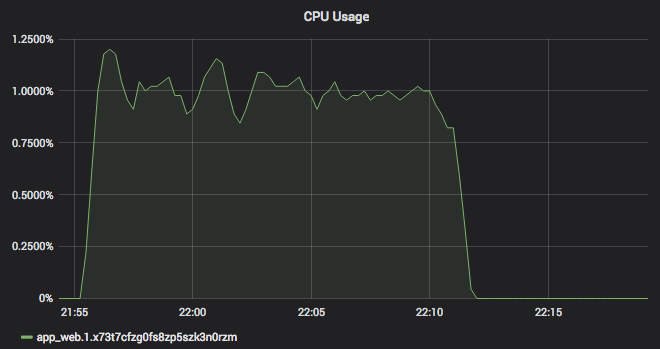
Nous pouvons explorer d’autres mesures du système de notre cluster Docker Swarm pour voir comment il est affecté par la charge des requêtes HTTP qu’il reçoit. Le point important est que nous utilisons ces données et les corrélons pour voir comment notre application Web se comporte.
Réglage de la référence
À ce stade, nous avons déjà un flux de travail de base pour créer un plan de test dans Apache JMeter et analyser les résultats préliminaires. À partir de là, nous pouvons ajuster plusieurs paramètres pour atteindre nos objectifs de référence. Dans cette section, nous allons itérer sur notre plan de test pour identifier les limites de notre application Docker.
Augmenter la simultanéité
Le premier paramètre que nous souhaitons peut-être régler est d’augmenter le nombre de boucles de notre plan de test. Conduire notre plan de test pour générer plus de demandes nous permettra de voir les effets de la charge que nous avons induite sur notre application. Cela augmente la précision de nos expériences de référence, car les événements aberrants tels qu’une connexion réseau lente ou une défaillance matérielle (sauf si nous testons cela spécifiquement !) Affectent nos tests.
Après avoir suffisamment de points de données pour nos benchmarks, nous pouvons réaliser que la charge générée n’est pas suffisante par rapport à notre application Docker. Par exemple, le débit actuel que nous avons reçu de notre première analyse peut ne pas simuler le comportement d’utilisateurs réels. Disons que nous voulons avoir 2 000 demandes par seconde. Pour augmenter la vitesse à laquelle JMeter génère les demandes, nous pouvons augmenter le nombre de threads dans le groupe de threads que nous avons créé précédemment. Cela augmente le nombre de demandes simultanées que JMeter crée à la fois. Si nous voulons simuler une augmentation progressive du nombre d’utilisateurs, nous pouvons ajuster la période de montée en puissance pour qu’elle soit plus longue.
Pour les charges de travail où nous voulons simuler une augmentation soudaine d’utilisateurs, nous pouvons nous en tenir à une période de montée en puissance de 0 pour démarrer immédiatement tous les threads. Dans les cas où nous voulons régler d’autres comportements, tels qu’une charge constante puis un pic soudain, nous pouvons utiliser le plugin Stepping Thread Group.
Nous pourrions aussi vouloir le limiter précisément à seulement cinq demandes par seconde. Ici, nous pouvons utiliser des éléments Timer pour contrôler la façon dont nos threads génèrent la demande. Pour commencer à limiter le débit, nous pouvons utiliser la minuterie de débit constant. Cela fera que JMeter ralentira automatiquement les threads lorsqu’il détectera que le débit qu’il reçoit de notre application Web augmente trop.
Certaines des techniques de référence ici sont difficiles à appliquer avec les composants Apache JMeter intégrés. Il existe une variété de plugins qui facilitent la génération de la charge pour piloter notre application. La liste Apache JMeter des plugins de communauté couramment utilisés se trouve à http://jmeter-plugins.org.
Exécution de tests distribués
Après avoir réglé les paramètres de concurrence pendant un certain temps, nous nous rendrons compte que notre résultat ne change pas. Nous pouvons configurer JMeter pour générer 10 000 requêtes à la fois, mais cela entraînera très probablement une panne de notre session JMeter! Dans ce cas, nous atteignons déjà les limites de performances de notre poste de travail lors de l’exécution des tests de performances. À partir de ce moment, nous pouvons commencer à utiliser un pool de serveurs qui exécutent JMeter pour créer des tests distribués. Les tests distribués sont utiles car nous pouvons saisir plusieurs serveurs du cloud avec des performances plus élevées pour simuler des pics. Il est également utile pour créer une charge provenant de plusieurs sources. Cette configuration distribuée est utile pour simuler des scénarios à latence élevée, où nos utilisateurs accèdent à notre application Docker de l’autre côté du monde.
Suivez les étapes suivantes pour déployer Apache JMeter sur plusieurs hôtes Docker pour effectuer un benchmark distribué :
1. Tout d’abord, créez le Dockerfile suivant pour créer une image Docker appelée hubuser / jmeter :
FROM openjdk:11-jre-stretch
RUN curl -s https://www.apache.org/dist/jmeter/binaries/apache-jmeter-5.1.tgz\ | tar xz
ADD benchmark.jmx /jmeter/benchmark.jmx
WORKDIR /jmeter
RUN /apache-jmeter-5.1/bin/create-rmi-keystore.sh -dname\ ‘CN=jmeter’
EXPOSE 1099
EXPOSE 1100
ENTRYPOINT [“/apache-jmeter-5.1/bin/jmeter”]
CMD [“-j”, “/dev/stdout”, “-s”, \
“-Dserver_port=1099”, “-Jserver_rmi_localport=1100”]
2. Ensuite, créez l’image Docker et publiez-la sur Docker Hub, à l’aide du code suivant:
dockerhost$ docker build -t hubuser/jmeter .
dockerhost$ docker push hubuser/jmeter
3. Maintenant que notre image Docker est publiée, créons maintenant un service JMeter avec deux répliques dans un fichier de composition appelé compose-jmeter.yml , en utilisant le code suivant:
—
version: ‘3.7’
services:
jmeter:
image: hubuser/jmeter
deploy:
replicas: 2
endpoint_mode: dnsrr
networks:
default:
driver: overlay
attachable: true
Note that we also set endpoint_mode: dnsrr in our service, as we don’t need a virtual IP address for our JMeter service. We will connect to each replica one by one from our JMeter client session later.
Notez que nous définissons également endpoint_mode: dnsrr dans notre service, car nous n’avons pas besoin d’une adresse IP virtuelle pour notre service JMeter. Nous nous connecterons plus tard à chaque réplique de notre session client JMeter.
4. Maintenant que la définition de notre service est prête, déployons-la sur notre cluster Docker Swarm à l’aide du code suivant :
dockerhost$ docker stack deploy benchmark -c compose-benchmark.yml
5. Une fois le service JMeter en cours d’exécution, déterminons les adresses IP de chaque réplique en effectuant la requête DNS suivante par rapport à son réseau de superposition Docker benchmark_default :
dockerhost$ docker run –network=benchmark_default –rm alpine nslookup jmeter
…
Name: jmeter
Address 1: 10.0.4.3 benchmark_jmeter.2.llybjbcroa3sn20yfn2i2klzc.benchmark_default
Address 2: 10.0.4.2 benchmark_jmeter.1.vpth5fzhz5dsg2w1ic0bbpf84.benchmark_default
Dans notre requête précédente, les adresses IP des répliques sont 10.0.4.2 et 10.0.4.3.
6. Pour exécuter notre benchmark JMeter à distance via ces serveurs JMeter en cours d’exécution, appelons JMeter avec l’option -R indiquant les adresses IP de chaque service, à l’aide du code suivant :
dockerhost$ docker run –network=benchmark_default –entrypoint /bin/sh -it aespinosa/jmeter
# /apache-jmeter-5.1/bin/jmeter -n -t benchmark.jmx -R 10.0.4.3,10.0.4.2
…
Configuring remote engine: 10.0.4.3
Configuring remote engine: 10.0.4.2
Starting remote engines
Starting the test @ Sat Mar 09 15:11:01 UTC 2019 (1552144261705)
…
summary = 20000 in 00:00:26 = 766.9/s Avg: 1 Min: 0 Max: 20041 Err: 10000 (50.00%)
Tidying up remote @ Sat Mar 09 15:11:31 UTC 2019 (1552144291696)
… end of run
…
Dans notre benchmark d’origine avec 10 000 tests, un test distribué a exécuté les mêmes 10 000 sur chaque réplique, ce qui représente un total de 20000 demandes pour notre application. Nous pouvons également voir cela en comptant le nombre de lignes dans les données résultantes qui ont été générées, comme indiqué dans le code suivant :
# wc -l result.jtl
20001 result.jtl
Plus d’informations sur les tests distribués et à distance peuvent être trouvées sur http://jmeter.apache.org/usermanual/remote-test.html.
Autres outils d’analyse comparative
Il existe quelques autres outils d’analyse comparative spécifiquement destinés à l’analyse comparative des applications Web. Voici une courte liste de ces outils, ainsi que leurs liens :
- Apache Bench : http://httpd.apache.org/docs/2.4/en/programs/ab.html
- Httperf de HP Lab : https://github.com/httperf/httperf
- Siege : https://www.joedog.org/siege-home
Résumé
Dans ce chapitre, nous avons créé des repères pour évaluer les performances de notre application Docker. En utilisant Apache JMeter et le système de surveillance que nous avons mis en place au chapitre 3, Monitoring Docker, nous avons analysé le comportement de notre application dans diverses conditions. Nous avons maintenant une idée des limites de notre application et nous allons l’utiliser pour l’optimiser davantage ou pour la faire évoluer.
Dans le chapitre suivant, nous parlerons d’équilibreurs de charge pour faire évoluer notre application afin d’augmenter sa capacité.
Équilibrage de charge
Peu importe la façon dont nous réglons nos applications Docker, nous atteindrons les limites de performances de notre application. En utilisant les techniques d’analyse comparative dont nous avons discuté dans le chapitre précédent, nous devrions être en mesure d’identifier la capacité de notre application. Dans un avenir proche, les utilisateurs de notre application Docker dépasseront cette limite. Nous ne pouvons pas refuser ces utilisateurs simplement parce que notre application Docker ne peut plus gérer leurs demandes. Nous devons faire évoluer notre application afin qu’elle puisse servir notre nombre croissant d’utilisateurs.
Dans ce chapitre, nous expliquerons comment faire évoluer nos applications Docker pour augmenter notre capacité. Nous utiliserons des équilibreurs de charge, qui sont un élément clé de l’architecture de diverses applications à l’échelle Web. Les équilibreurs de charge répartissent les utilisateurs de notre application sur plusieurs applications Docker déployées dans notre batterie d’hôtes Docker. Les étapes suivantes décrites dans ce chapitre nous aideront à y parvenir :
- Préparation des backends d’application
- Équilibrer la charge avec NGINX
- Extension avec Docker
- Déploiement sans temps d’arrêt
Préparation des backends d’application
Pour créer une application à charge équilibrée, nous devons d’abord préparer l’application là où elle est servie par plusieurs répliques dans notre service Docker Swarm. Dans les étapes suivantes, nous déploierons une application mise à l’échelle dans notre cluster Docker Swarm:
1. Premièrement, nous approvisionnerons des nœuds supplémentaires dans notre cluster Docker Swarm. Il s’agit de s’assurer que nous avons suffisamment de capacité dans notre cluster pour étendre notre application plus tard. Dans la sortie suivante, nous pouvons voir que nous avons quatre nœuds disponibles :
dockerhost$ docker node ls
ID HOSTNAME STATUS AVAILA… MANAGER… ENGINE VERSION
9tcxzq45 * dockerhost Ready Active Leader 18.09.3
thxcn7ev node-5lfg Ready Active 18.09.0
7lyr93qf node-ftc0 Ready Active 18.09.0
oydrnufp node-hqvv Ready Active 18.09.0
2. Ensuite, nous allons préparer une simple application Node.js dans un fichier appelé app.js . L’application suivante enregistre des informations supplémentaires sur la façon dont la charge de notre application est répartie sur plusieurs répliques :
var http = require(‘http’);
var server = http.createServer(function (request, response) {
response.writeHead(200, {“Content-Type”: “text/plain”});
var version = “1.0.0”;
var log = {};
log.header = ‘mywebapp’;
log.name = process.env.HOSTNAME;
log.version = version;
console.log(JSON.stringify(log));
response.end(version + ” Hello World “+ process.env.HOSTNAME);
});
server.listen(8000);
3. Pour déployer le code d’application précédent, nous allons l’intégrer dans une image Docker appelée hubuser/app : 1.0.0 avec le Dockerfile suivant :
FROM node:11-stretch
COPY app.js /app/app.js
EXPOSE 8000
CMD [“node”, “/app/app.js”]
4. Assurez-vous que notre image Docker est créée et disponible sur Docker Hub. De cette façon, nous pouvons facilement le déployer. Exécutez cela avec la commande suivante :
dockerhost$ docker build -t hubuser/app:1.0.0.
dockerhost$ docker push hubuser/app:1.0.0
5. Ensuite, créons la définition de notre service d’application dans un fichier de composition appelé compose-lb.yml :
—
version: ‘3.7’
services:
app_green:
image: hubuser/app:1.0.0
deploy:
replicas: 2
endpoint_mode: dnsrr
networks:
default:
aliases:
– application
Notez que nous avons configuré notre application pour qu’elle s’exécute sur deux répliques. Nous avons également créé un alias supplémentaire pour notre service appelé application. Enfin, nous avons défini l’utilisation du round-robin DNS comme mode de nœud final, car nous le chargerons plus tard avec NGINX.
6. Enfin, déployons notre service :
dockerhost$ docker stack deploy balancing -c compose-lb.yml
Notre application est maintenant prête à servir le trafic. Dans la section suivante, nous allons configurer NGINX pour équilibrer la charge du trafic vers ces répliques.
Équilibrage de la charge avec NGINX
Maintenant que nous avons un pool d’applications Docker vers lequel transférer le trafic, nous pouvons préparer notre équilibreur de charge. Dans cette section, nous couvrirons brièvement NGINX, un serveur Web populaire qui a une concurrence et des performances élevées. Il est couramment utilisé comme proxy inverse pour transférer les demandes vers des applications Web plus dynamiques, telles que celle de Node.js que nous avons écrite plus tôt. En configurant NGINX pour avoir plusieurs destinations de proxy inverse, telles que notre pool d’applications Docker, il équilibrera la charge des demandes qui lui parviendront à travers le pool.
Les étapes suivantes déploieront NGINX sur notre cluster Docker Swarm pour l’équilibrage de charge :
1. Tout d’abord, préparons un fichier de configuration NGINX appelé nginx.conf :
events { }
http {
resolver 127.0.0.11 valid=5s ipv6=off;
server {
listen 80;
location / {
set $backend application;
proxy_pass http://$backend:8000;
}
}
}
Notez que nous avons utilisé la découverte du service DNS de NGINX pour envoyer du trafic vers notre application via son application d’alias réseau.
2. Ensuite, mettons à jour notre fichier compose-lb.yml pour inclure notre service NGINX. Ce sera le point d’entrée de notre application :
—
version: ‘3.7’
services:
nginx: # Add this new nginx service
image: nginx:stable
ports:
– ’80:80′
configs:
– source: nginx.conf
target: /etc/nginx/nginx.conf
app_green:
image: hubuser/app:1.0.0
deploy:
replicas: 2
endpoint_mode: dnsrr
configs: # Include this config
nginx.conf:
file: ./nginx.conf
3. Enfin, déployons notre service NGINX en mettant à jour notre déploiement de pile:
dockerhost $ docker stack deploy balancing -c compose-lb.yml
Notre application Web est désormais accessible via http://dockerhost (ou n’importe quel port 80 de chaque nœud Docker Swarm). Chaque demande sera ensuite acheminée vers l’une des répliques hubuser / webapp: 1.0.0 déployées sur notre cluster Docker Swarm.
Pour confirmer notre déploiement, nous pouvons regarder notre visualisation Kibana pour montrer la distribution du trafic sur nos trois hôtes. Pour afficher la répartition du trafic, nous devons d’abord générer une charge pour notre application. Nous pouvons utiliser notre infrastructure de test JMeter décrite au chapitre 6 , Analyse comparative , pour y parvenir. Pour des tests rapides, nous pouvons également générer une charge à l’aide d’une commande de longue durée similaire à la suivante:
$ while true; do curl http://dockerhost && sleep 0.1; done
1.0.0 Hello World 56547aceb063
1.0.0 Hello World af272c6968f0
1.0.0 Hello World 56547aceb063
1.0.0 Hello World af272c6968f0
1.0.0 Hello World 56547aceb063
1.0.0 Hello World af272c6968f0
Rappelez-vous que, dans l’application que nous avons préparée précédemment, nous avons imprimé $ HOSTNAME dans le cadre de la réponse HTTP. Dans le cas précédent, les réponses indiquent le nom d’hôte du conteneur Docker. Notez que les conteneurs Docker obtiennent le hachage court de leurs ID de conteneur comme nom d’hôte par défaut. Comme nous pouvons le constater à partir de la sortie initiale de notre charge de travail de test, nous obtenons des réponses de trois conteneurs.
Nous pouvons mieux visualiser la réponse dans une visualisation Kibana si nous configurons notre infrastructure de journalisation comme nous l’avons fait au chapitre 3, Surveillance de Docker .
Dans la capture d’écran suivante, nous pouvons compter le nombre de réponses par minute en fonction de l’hôte Docker d’où provient l’entrée de journal :
Nous pouvons noter dans le graphique précédent que notre charge de travail est répartie uniformément par NGINX sur les deux répliques de notre application.
Extension de nos applications Docker
Supposons maintenant que la charge de travail de la section précédente commence à surcharger chacun de nos trois hôtes Docker. Sans un équilibreur de charge tel que notre configuration NGINX précédente, les performances de notre application commenceront à se dégrader. Cela peut signifier une qualité de service inférieure pour les utilisateurs de notre application ou être paginé au milieu de la nuit pour effectuer des opérations héroïques sur les systèmes. Cependant, avec un équilibreur de charge gérant les connexions à nos applications, il est très simple d’ajouter plus de capacité pour augmenter les performances de notre application.
Comme notre application est déjà conçue pour être équilibrée en charge, notre processus de mise à l’échelle est très simple. La seule chose que nous devons faire est de mettre à jour le nombre de répliques de notre application dans le fichier compose-lb.yml :
—
version: ‘3.7’
services:
nginx:
image: nginx:stable
ports:
– ’80:80′
configs:
– source: nginx.conf
target: /etc/nginx/nginx.conf
app_green:
image: hubuser/app:1.0.0
deploy:
replicas: 4 # Update this replica number
endpoint_mode: dnsrr
networks:
default:
aliases:
– application
# configs: …
Après cela, nous mettons à jour notre déploiement :
dockerhost$ docker stack deploy balancing -c compose-lb.yml
Maintenant que nous avons terminé la mise à l’échelle de notre application Docker, regardons en arrière notre visualisation Kibana pour observer l’effet. La capture d’écran suivante montre la répartition du trafic sur les cinq hôtes Docker que nous avons actuellement :
Nous pouvons noter dans la capture d’écran précédente qu’après avoir rechargé NGINX, il a commencé à répartir la charge sur nos nouveaux conteneurs Docker. Avant cela, chaque conteneur Docker ne recevait que la moitié du trafic de NGINX. Désormais, chaque application Docker du pool ne reçoit qu’un quart du trafic.
Déploiement sans temps d’arrêt
Un autre avantage de l’équilibrage de charge de notre application Docker est que nous pouvons utiliser les mêmes techniques d’équilibrage de charge pour mettre à jour notre application. Normalement, les ingénieurs d’exploitation doivent planifier des temps d’arrêt ou une fenêtre de maintenance afin de mettre à jour une application déployée en production. Cependant, comme le trafic de notre application va à un équilibreur de charge avant qu’il n’atteigne notre application, nous pouvons utiliser cette étape intermédiaire à notre avantage. Dans cette section, nous utiliserons une technique appelée déploiements bleu-vert pour mettre à jour notre application en cours d’exécution sans interruption.
Notre pool actuel de hubuser/app : 1.0.0 Docker conteneurs est appelé notre pool d’hôtes Docker vert car il reçoit activement les demandes de notre équilibreur de charge NGINX. Nous mettrons à jour l’application desservie par notre équilibreur de charge NGINX vers un pool de conteneurs Dockuser/app:2.0.0 Docker. Voici les étapes pour effectuer la mise à jour :
1. Tout d’abord, mettons à jour notre application en modifiant la chaîne de version dans notre fichier app.js, comme suit :
var http = require(‘http’);
var server = http.createServer(function (request, response) {
response.writeHead(200, {“Content-Type”: “text/plain”});
var version = “2.0.0”;
// …
});
server.listen(8000);
2. Après avoir mis à jour le contenu, nous préparerons une nouvelle version de notre image Docker appelée hubuser/app: 2.0.0 et la publierons sur Docker Hub via la commande suivante:
dockerhost$ docker build -t hubuser/app:2.0.0 .
dockerhost$ docker push hubuser/app:2.0.0
3. En option, nous pouvons ajouter plus de nœuds de travail Docker Swarm, si nous pensons qu’une plus grande capacité est nécessaire pour exécuter plus de conteneurs.
4. Ensuite, mettons à jour notre fichier de composition pour déployer la nouvelle version de notre service. Nous nommerons ce service app_blue et le déploierons avec notre service d’origine :
—
version: ‘3.7’
services:
nginx:
image: nginx:stable
ports:
– ’80:80′
configs:
– source: nginx.conf
target: /etc/nginx/nginx.conf
app_green:
image: hubuser/app:1.0.0
deploy:
replicas: 4
endpoint_mode: dnsrr
networks:
default:
aliases:
– application
app_blue: # Add this new applicaiton
image: hubuser/app:2.0.0
deploy:
replicas: 2
endpoint_mode: dnsrr
configs:
nginx.conf:
file: ./nginx.conf
5. Ensuite, nous déployons et mettons à jour notre pile :
dockerhost$ docker stack deploy balancing -c compose-lb.yml
Nos répliques d’applications bleues sont maintenant en cours d’exécution. Il est appelé bleu car, bien qu’il soit désormais opérationnel et en cours d’exécution, il n’a pas encore reçu de trafic utilisateur. À ce stade, nous pouvons faire tout ce qui est nécessaire, comme effectuer des vérifications en amont et des tests avant de siphonner nos utilisateurs vers la nouvelle version de notre application.
6. Une fois que nous sommes convaincus que notre service d’application bleue est pleinement fonctionnel et fonctionnel, il est temps de lui envoyer du trafic. Pour ce faire, nous ajouterons l’alias de réseau, application, à la nouvelle version de notre service en mettant à jour compose-lb.yml à nouveau :
—
version: ‘3.7’
services:
# nginx: …
# app_green: …
app_blue:
# …
networks:
default:
aliases:
– application
# configs: …
7. Pour terminer la mise à jour, déployons à nouveau notre pile :
dockerhost$ docker stack deploy balancing -c compose-lb.yml
À ce stade, NGINX envoie du trafic à la fois à l’ancienne version (hubuser/app:1.0.0) et à la nouvelle version (hubuser/app:2.0.0) de notre application Docker. Avec cela, nous pouvons vérifier complètement que notre nouvelle application fonctionne bien comme prévu car elle sert désormais le trafic en direct des utilisateurs de notre application. Dans les cas où cela ne fonctionne pas correctement, nous pouvons annuler en toute sécurité en supprimant l’alias réseau dans notre service d’application bleu et mettre à jour notre déploiement.
8. Supposons cependant que nous soyons déjà satisfaits de notre nouvelle application. Nous pouvons ensuite supprimer en toute sécurité l’ancienne application Docker de la configuration de notre équilibreur de charge. Pour ce faire, adaptons notre application à zéro réplique :
—
version: ‘3.7’
services:
nginx:
image: nginx:stable
ports:
– ’80:80′
configs:
– source: nginx.conf
target: /etc/nginx/nginx.conf
app_green:
image: hubuser/app:1.0.0
deploy:
replicas: 4
endpoint_mode: dnsrr
networks:
default:
aliases:
– application
app_blue:
image: hubuser/app:2.0.0
deploy:
replicas: 2
endpoint_mode: dnsrr
networks: # Add this new network alias
default:
aliases:
– application
configs:
nginx.conf:
file: ./nginx.conf
9. Et enfin, déployons notre pile une dernière fois :
dockerhost$ docker stack deploy balancing -c compose-lb.yml
Toutes nos félicitations ! Nous avons terminé le déploiement bleu-vert de notre nouvelle application et nous l’avons fait sans interruption de service ! À ce stade, notre service d’application bleue sert tout le trafic de production de notre application.
L’ensemble du processus de déploiement bleu-vert que nous avons entrepris plus tôt peut être résumé dans la visualisation Kibana suivante :
Notez que, dans le graphique précédent, notre application sert toujours le trafic même si nous avons mis à jour notre application. Notez également qu’avant cela, tout le trafic était distribué à nos quatre applications 1.0.0. Après avoir activé le pool d’hôtes Docker bleu, un tiers du trafic a commencé à passer à la version 2.0.0 de notre application. Au final, nous avons désactivé tous les points de terminaison de notre ancien service d’application verte, et tout le trafic de l’application est désormais géré par la version 2.0.0 de notre application.
Vous trouverez plus d’informations sur les déploiements bleu-vert et d’autres types de techniques de libération sans interruption dans un livre intitulé Continuous Delivery de Jez Humble et Dave Farley. Le site Web du livre peut être trouvé à http://continuousdelivery.com.
Autres équilibreurs de charge
Il existe d’autres outils qui peuvent être utilisés pour équilibrer les applications de charge. Certains sont similaires à NGINX, où la configuration est définie via des fichiers de configuration externes. Ensuite, nous pouvons envoyer un signal au processus en cours pour recharger la configuration mise à jour. Certains ont leurs configurations de pool stockées dans un magasin externe, comme Redis, etcd, et même des bases de données régulières, de sorte que la liste est chargée dynamiquement par l’équilibreur de charge lui-même. Même NGINX possède certaines de ces fonctionnalités dans son offre commerciale. Il existe également d’autres projets open source qui étendent NGINX avec des modules tiers.
Voici une courte liste d’équilibreurs de charge que nous pouvons déployer sous forme de conteneurs Docker dans notre infrastructure :
- HAProxy ( http://www.haproxy.org )
- Serveur Apache HTTP ( http://httpd.apache.org )
- Traefik ( https://traefik.io/ )
Il existe également des équilibreurs de charge basés sur le matériel que nous pouvons nous procurer et configurer via leurs propres formats propriétaires ou API. Si nous utilisons des fournisseurs de cloud, certaines de leurs propres offres d’équilibrage de charge auraient leurs propres API de cloud que nous pouvons également utiliser.
Résumé
Dans ce chapitre, nous avons découvert les avantages de l’utilisation d’équilibreurs de charge et comment les utiliser. Nous avons déployé et configuré NGINX en tant qu’équilibreur de charge dans un conteneur Docker afin de pouvoir étendre notre application Docker. Nous avons également utilisé l’équilibreur de charge pour effectuer des versions sans interruption de service afin de mettre à jour notre application vers une nouvelle version.
Dans le chapitre suivant, nous continuerons d’améliorer nos compétences d’optimisation Docker en déboguant à l’intérieur des conteneurs Docker que nous déployons.
Dépannage des conteneurs
Parfois, la configuration d’une instrumentation telle que le système de surveillance et de journalisation (comme nous l’avons fait au chapitre 3 , Surveillance de Docker ) peut ne pas suffire. Idéalement, nous devrions créer un moyen de dépanner nos déploiements Docker de manière évolutive. Cependant, parfois, nous n’avons pas d’autre choix que de nous connecter à l’hôte Docker et de regarder les conteneurs Docker eux-mêmes. Il est important de savoir comment interagir avec nos hôtes Docker afin de comprendre ce qui se passe avec nos systèmes. Ces activités de débogage de bas niveau contribueront également à améliorer notre système de surveillance et de journalisation pour notre infrastructure Docker.
Dans ce chapitre, nous couvrirons les sujets suivants :
- Inspection des conteneurs avec la commande docker exec
- Débogage depuis Docker extérieur
- Autres outils de débogage de conteneur
Inspection des conteneurs avec la commande docker exec
Lors du dépannage des serveurs, la méthode traditionnelle de débogage consiste à se connecter et à fouiller la machine. Avec Docker, ce flux de travail typique est divisé en deux étapes : la première se connecte à l’hôte Docker en utilisant des outils d’accès à distance standard tels que SSH, et la seconde entre l’espace de noms de processus du conteneur en cours d’exécution souhaité avec la commande docker exec. Ceci est utile en dernier recours pour déboguer ce qui se passe dans notre application.
Pour la majeure partie de ce chapitre, nous allons dépanner et déboguer un conteneur Docker exécutant HAProxy. Les étapes suivantes prépareront l’exemple de service de conteneur :
1. Tout d’abord, nous allons créer la configuration pour HAProxy nommée haproxy.cfg avec le contenu suivant :
defaults
mode http
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
frontend stats
bind 127.0.0.1:80
stats enable
listen http-in
bind *:80
server server1 www.debian.org:80
2. Ensuite, nous préparerons un fichier Compose, compose.yml , décrivant comment exécuter le service HAProxy:
—
version: ‘3.7’
services:
haproxy:
image: haproxy:1.9
ports:
– ’80:80′
configs:
– source: haproxy.cfg
target: /usr/local/etc/haproxy/haproxy.cfg
configs:
haproxy.cfg:
file: ./haproxy.cfg
3. Enfin, exécutons HAProxy en déployant notre fichier Docker Compose :
dockerhost$ docker stack deploy haproxy -c compose.yml
Nous pouvons maintenant commencer à inspecter notre conteneur et à le déboguer, ce qui est un bon moyen de confirmer que le conteneur HAProxy écoute le port 80. Le programme ss exporte un résumé des statistiques de sockets disponibles dans la plupart des distributions Linux, comme notre hôte CentOS Docker. Cependant, comme la plupart des images Docker sont empaquetées pour être aussi petites que possible, les programmes de débogage tels que ss peuvent ne pas être disponibles. Dans l’exemple suivant, la saisie de notre conteneur haproxy en cours d’exécution à l’aide de docker exec nous indique que ce programme n’est en effet pas disponible :
dockerhost$ service=$(docker service ps haproxy_haproxy -q)
dockerhost$ docker exec haproxy_haproxy.1.$service ss -l
OCI runtime exec failed: exec failed: container_linux.go:344: starting container process caused “exec: \”/bin/ss\”: stat /bin/ss: no such file or directory”: unknown
Nous pouvons fournir une solution rapide en l’installant à l’intérieur de notre conteneur, similaire à ce que nous faisons dans un environnement de système d’exploitation normal. Pendant que nous sommes encore à l’intérieur du conteneur, nous allons taper la commande suivante pour installer ss :
dockerhost$ service=$(docker service ps haproxy_haproxy -q)
dockerhost$ docker exec -it haproxy_haproxy.1.$service /bin/bash
# haproxy uses Debian as the base image so we have to use apt for
# installing packages.
root@b397ffb9df13:/# apt-get update
root@b397ffb9df13:/# apt-get install -y iproute2
Lorsque vous utilisez la commande docker ps <nom-service> -q, nous pouvons ajouter l’indicateur –filter desire-state = running si le service a redémarré plusieurs fois auparavant.
Nous pouvons maintenant exécuter le programme ss et confirmer que le service haproxy écoute le port 80 :
root@b397ffb9df13:/# # ss -l -A tcp
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:80 *:*
LISTEN 0 128 127.0.0.1:80 *:*
LISTEN 0 128 127.0.0.11:41372 *:*
Cette approche de débogage de conteneur ad hoc n’est pas recommandée ! La connexion manuelle aux hôtes Docker peut entraîner des modifications involontaires de notre infrastructure auxquelles nous ne nous attendions pas. Cela rendra le débogage encore plus difficile à l’avenir.
Voici quelques limites de cette approche de dernier recours :
- Lorsque nous arrêtons et recréons le conteneur, le package netstat que nous avons installé ne sera plus disponible. Cela est dû au fait que l’image HAProxy Docker d’origine ne la contient pas en premier lieu. L’installation de packages ad hoc pour exécuter des conteneurs sape la principale caractéristique de Docker, qui est de permettre une infrastructure immuable.
- Dans le cas où nous voulons empaqueter tous les outils de débogage à l’intérieur de notre image Docker, sa taille augmentera en conséquence. Cela signifie que nos déploiements augmenteront et deviendront plus lents. N’oubliez pas que, dans le chapitre 4, Optimisation des images Docker, nous avons optimisé pour réduire la taille de notre conteneur.
- Dans le cas de conteneurs minimaux avec juste les binaires requis, nous sommes désormais majoritairement aveugles. La coque Thebash n’est même pas disponible ! Il n’y a aucun moyen d’entrer dans notre conteneur ; jetez un oeil à la commande suivante :
dockerhost$ docker exec -it minimal_image /bin/bash
OCI runtime exec failed: exec failed: container_linux.go:344: starting container process caused “exec: \”/bin/bash\”: stat /bin/bash: no such file or directory”: unknown
En bref, docker exec est un outil puissant qui pénètre dans nos conteneurs et débogue en exécutant diverses commandes. Couplé avec les indicateurs -it , nous pouvons obtenir un shell interactif pour effectuer un débogage plus approfondi. Cette approche a ses limites car elle suppose que tous les outils disponibles dans notre conteneur Docker sont prêts à l’emploi.
Pour plus d’informations sur la commande docker exec, consultez la documentation officielle à l’adresse https://docs.docker.com/engine/reference/commandline/exec/.
Après avoir débogué notre application avec la commande docker exec, nous devrions utiliser ces leçons pour améliorer le système de surveillance et de journalisation que nous avons créé au chapitre 3, Surveillance de Docker.
La section suivante explique comment contourner cette limitation en disposant d’outils externes à Docker pour inspecter l’état de notre conteneur en cours d’exécution. Nous fournirons un bref aperçu de la façon d’utiliser certains de ces outils.
Débogage depuis Docker extérieur
Même si Docker isole le réseau, la mémoire, le processeur et les ressources de stockage à l’intérieur des conteneurs, chaque conteneur individuel devra toujours accéder au système d’exploitation de l’hôte Docker pour exécuter la commande réelle. Nous pouvons profiter de ce ruissellement des appels vers le système d’exploitation hôte pour intercepter et déboguer nos conteneurs Docker de l’extérieur. Dans cette section, nous couvrirons certains outils sélectionnés et comment les utiliser pour interagir avec nos conteneurs Docker. Nous pouvons effectuer l’interaction à partir de l’hôte Docker lui-même ou à l’intérieur d’un conteneur frère avec des privilèges élevés pour voir certains composants de l’hôte Docker.
Suivi des appels système
Un traceur d’appels système est l’un des outils essentiels pour les opérations serveur. Il s’agit d’un utilitaire qui intercepte et trace les appels effectués par l’application vers le système d’exploitation. Chaque système d’exploitation a sa propre variation. Même si nous exécutons diverses applications et processus à l’intérieur de nos conteneurs Docker, il finira par entrer dans le système d’exploitation Linux de notre hôte Docker sous la forme d’une série d’appels système.
Sur les systèmes Linux, le programme strace est utilisé pour tracer ces appels système. Cette fonctionnalité d’interception et de journalisation de strace peut être utilisée pour inspecter nos conteneurs Docker de l’extérieur. La liste des appels système effectués tout au long de la durée de vie de notre conteneur peut donner une vue au niveau du profil de son comportement.
Pour commencer à utiliser strace, tapez simplement la commande suivante pour l’installer dans notre hôte CentOS Docker:
dockerhost$ yum install -y
Avec l’option –pid = host ajoutée à la commande docker run, nous pouvons définir l’espace de noms PID d’un conteneur comme appartenant à l’hôte Docker. De cette façon, nous pourrons installer et utiliser strace dans un conteneur Docker pour inspecter tous les processus dans l’hôte Docker lui-même. Nous pouvons également installer strace à partir d’une distribution Linux différente, comme Ubuntu, si nous utilisons l’image de base correspondante pour notre conteneur.
Plus d’informations décrivant cette option sont disponibles sur http://docs.docker.com/engine/reference/run/#pid-settings—pid .
Maintenant que strace est installé sur notre hôte Docker, nous pouvons l’utiliser pour inspecter les appels système à l’intérieur du conteneur HAProxy que nous avons créé dans la section précédente. Tapez les commandes suivantes pour commencer le suivi des appels système à partir du conteneur HAProxy:
dockerhost$ service=$(docker service ps haproxy_haproxy -q)
dockerhost$ container=haproxy_haproxy.1.$service
dockerhost$ pid=$(docker inspect -f ‘{{.State.Pid}}’ $container)
dockerhost$ strace -p $(pgrep -P $pid)
clock_gettime(CLOCK_THREAD_CPUTIME_ID, {0, 251877895}) = 0
clock_gettime(CLOCK_THREAD_CPUTIME_ID, {0, 251931556}) = 0
epoll_wait(4, [], 200, 1000) = 0
clock_gettime(CLOCK_THREAD_CPUTIME_ID, {0, 252169242}) = 0
clock_gettime(CLOCK_THREAD_CPUTIME_ID, {0, 252263388}) = 0
epoll_wait(4, [], 200, 1000) = 0
clock_gettime(CLOCK_THREAD_CPUTIME_ID, {0, 252505040}) = 0
clock_gettime(CLOCK_THREAD_CPUTIME_ID, {0, 252600407}) = 0
epoll_wait(4, [], 200, 1000)
…
Comme vous pouvez le voir, notre conteneur HAProxy effectue des appels epoll_wait () pour attendre les connexions réseau entrantes. Maintenant, dans un terminal distinct, tapez la commande suivante pour effectuer une demande HTTP sur notre conteneur en cours d’exécution :
$ curl http://dockerhost
Maintenant, revenons à notre programme strace en cours d’exécution plus tôt. Nous pouvons voir les lignes suivantes imprimées :
…
epoll_wait(5, [{EPOLLIN, {u32=7, u64=7}}], 200, 1000) = 1
clock_gettime(CLOCK_THREAD_CPUTIME_ID, {0, 262270237}) = 0
accept4(7, {sa_family=AF_INET, sin_port=htons(63212), sin_addr=inet_addr(“10.255.0.2”)}, [16], SOCK_NONBLOCK) = 10
setsockopt(10, SOL_TCP, TCP_NODELAY, [1], 4) = 0
accept4(7, 0x7fff262ba090, 0x7fff262ba084, SOCK_NONBLOCK) = -1 EAGAIN (Resource temporarily unavailable)
recvfrom(10, “GET / HTTP/1.1\r\nUser-Agent: curl”…, 15360, 0, NULL, NULL) = 75
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP) = 11
fcntl(11, F_SETFL, O_RDONLY|O_NONBLOCK) = 0
setsockopt(11, SOL_TCP, TCP_NODELAY, [1], 4) = 0
connect(11, {sa_family=AF_INET, sin_port=htons(80), sin_addr=inet_addr(“149.20.4.15”)}, 16) = -1 EINPROGRESS (Operation now in progress)
sendto(11, “GET / HTTP/1.1\r\nUser-Agent: curl”…, 75, MSG_DONTWAIT|MSG_NOSIGNAL, NULL, 0) = -1 EAGAIN (Resource temporarily unavailable)
epoll_ctl(5, EPOLL_CTL_ADD, 11, {EPOLLOUT, {u32=11, u64=11}}) = 0
…
Nous pouvons voir ici que HAProxy a effectué des appels système standard de socket de type BSD, tels que accept4 () , socket () et close () , pour accepter, traiter et mettre fin aux connexions réseau à partir de notre client HTTP. Enfin, il revient à epoll_wait () à nouveau pour attendre les prochaines connexions. Notez également que les appels epoll_wait () sont répartis sur toute la trace même lorsque HAProxy traite une connexion. Cela montre comment HAProxy peut gérer les connexions simultanées.
Le suivi des appels système est une technique très utile pour déboguer des systèmes de production en direct. Les gens dans les opérations sont parfois paginés et n’ont pas accès au code source tout de suite. Alternativement, il y a des cas où nous ne recevons que des binaires compilés (ou des images Docker simples) en cours de production où il n’y a pas de code source (ni Dockerfile). Le seul indice que nous pouvons obtenir d’une application en cours d’exécution est de piéger les appels système qu’elle fait au noyau Linux.
La page Web de strace se trouve à https://strace.io/. Plus d’informations sont également accessibles via sa page de manuel, en tapant la commande suivante :
dockerhost$ man 1 strace
Pour une liste plus complète des appels système dans les systèmes Linux, reportez-vous à http://man7.org/linux/man-pages/man2/syscalls.2.html. Cela sera utile pour comprendre les différentes sorties fournies par strace.
Analyse des paquets réseau
La plupart des conteneurs Docker que nous déployons tournent autour de la fourniture d’une certaine forme de service réseau. Dans l’exemple de HAProxy dans ce chapitre, notre conteneur sert essentiellement le trafic réseau HTTP. Quel que soit le type de conteneur que nous avons en cours d’exécution, les paquets réseau devront éventuellement quitter l’hôte Docker pour qu’il puisse répondre à une demande que nous lui envoyons. En vidant et en analysant le contenu de ces paquets, nous pouvons avoir un aperçu de la nature de notre conteneur Docker. Dans cette section, nous utiliserons un analyseur de paquets appelé tcpdump pour afficher le trafic des paquets réseau reçus et envoyés par nos conteneurs Docker.
Pour commencer à utiliser tcpdump, nous pouvons émettre la commande suivante dans notre hôte CentOS Docker pour l’installer :
dockerhost$ yum install -y tcpdump
Nous pouvons également exposer les interfaces réseau de l’hôte Docker à un conteneur. Avec cette approche, nous pouvons installer tcpdump dans un conteneur et ne pas polluer notre hôte Docker principal avec des packages de débogage ad hoc. Cela peut être fait en spécifiant l’indicateur –net = host sur la commande docker run. Avec cela, nous pouvons accéder à l’interface docker0 depuis l’intérieur de notre conteneur Docker avec tcpdump.
L’exemple d’utilisation de tcpdump sera très spécifique au fournisseur Vagrant VMware Fusion pour VMware Fusion 7.0. En supposant que nous avons un hôte Docker CentOS en tant que boîte Vagrant VMware Fusion, exécutez la commande suivante pour suspendre et suspendre la machine virtuelle de notre hôte Docker :
$ vagrant suspend
$ vagrant up
$ vagrant ssh
dockerhost$
Maintenant que nous sommes de retour dans notre hôte Docker, exécutez la commande suivante et notez que nous ne pouvons plus résoudre www.google.com dans notre conteneur interactif debian:jessie , comme suit:
dockerhost$ docker run -it debian:jessie /bin/bash
root@fce09c8c0e16:/# ping www.google.com
ping: unknown host
Maintenant, exécutons tcpdump dans un terminal séparé. Lors de l’exécution de la commande ping précédente, nous remarquerons la sortie suivante de notre terminal tcpdump :
dockerhost$ tcpdump -i docker0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on docker0, link-type EN10MB (Ethernet), capture size 262144 bytes
22:03:34.512942 ARP, Request who-has 172.17.42.1 tell 172.17.0.7, length 28
22:03:35.512931 ARP, Request who-has 172.17.42.1 tell 172.17.0.7, length 28
22:03:38.520681 ARP, Request who-has 172.17.42.1 tell 172.17.0.7, length 28
22:03:39.520099 ARP, Request who-has 172.17.42.1 tell 172.17.0.7, length 28
22:03:40.520927 ARP, Request who-has 172.17.42.1 tell 172.17.0.7, length 28
22:03:43.527069 ARP, Request who-has 172.17.42.1 tell 172.17.0.7, length 28
Comme nous pouvons le voir, le conteneur interactif / bin / bash recherche 172.17.42.1, qui est normalement l’adresse IP attachée au périphérique réseau Docker Engine, docker0. Avec cela compris, jetez un œil à docker0 en tapant la commande suivante :
dockerhost$ ip addr show dev docker0
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:46:66:64:b8 brd ff:ff:ff:ff:ff:ff
inet6 fe80::42:46ff:fe66:64b8/64 scope link
valid_lft forever preferred_lft forever
Maintenant, nous pouvons voir le problème. Le périphérique docker0 n’a pas d’adresse IPv4 attachée. D’une manière ou d’une autre, VMware ne suspendant pas notre hôte Docker supprime l’adresse IP mappée dans docker0 . Heureusement, la solution consiste à simplement redémarrer le moteur Docker et Docker réinitialisera lui-même l’interface réseau docker0. Redémarrez Docker Engine en tapant la commande suivante dans notre hôte Docker :
dockerhost$ systemctl restart docker.service
Maintenant, lorsque nous exécutons la même commande que précédemment, nous verrons que l’adresse IP est attachée, comme suit :
dockerhost$ ip addr show dev docker0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noque…
link/ether 02:42:46:66:64:b8 brd ff:ff:ff:ff:ff:ff
inet 172.17.42.1/16 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:46ff:fe66:64b8/64 scope link
valid_lft forever preferred_lft forever
Revenons à notre commande initiale montrant le problème; nous verrons qu’il est maintenant résolu, comme suit:
root@fce09c8c0e16:/# ping www.google.com
PING www.google.com (74.125.21.105): 56 data bytes
64 bytes from 74.125.21.105: icmp_seq=0 ttl=127 time=65.553 ms
64 bytes from 74.125.21.105: icmp_seq=1 ttl=127 time=38.270 ms
…
Plus d’informations sur le dumper et l’analyseur de paquets tcpdump peuvent être trouvées sur http://www.tcpdump.org . Nous pouvons également accéder à la documentation à partir de l’endroit où nous l’avons installée en tapant la commande suivante:
dockerhost $ man 8 tcpdump
Observer les périphériques blocs
Les données accessibles à partir de nos conteneurs Docker résideront principalement dans des périphériques de stockage physiques, tels que des disques durs ou des disques SSD. Sous les systèmes de fichiers de copie sur écriture de Docker se trouve un périphérique physique auquel on accède de manière aléatoire. Ces lecteurs sont regroupés en tant que périphériques blocs. Les données ici sont des données de taille fixe à accès aléatoire appelées blocs.
Ainsi, dans le cas où nos conteneurs Docker présentent des problèmes particuliers de comportement d’E / S et de performances, nous pouvons tracer et dépanner ce qui se passe à l’intérieur de nos périphériques de bloc à l’aide d’un outil appelé blktrace. Tous les événements que le noyau génère pour interagir avec les périphériques de bloc des processus sont interceptés par ce programme. Dans cette section, nous allons configurer notre hôte Docker pour observer le périphérique de bloc supportant nos conteneurs en dessous.
Pour utiliser blktrace, préparons notre hôte Docker en installant le programme blktrace. Tapez la commande suivante pour l’installer dans notre hôte Docker :
dockerhost$ yum install -y blktrace
De plus, nous devons activer le débogage du système de fichiers. Nous pouvons le faire en tapant la commande suivante dans notre hôte Docker :
dockerhost$ mount -t debugfs debugfs /sys/kernel/debug
Après les préparatifs, nous devons trouver comment indiquer à blktrace où écouter les événements d’E / S. Pour tracer les événements d’E / S pour nos conteneurs, nous devons savoir où se trouve la racine du runtime Docker. Dans la configuration par défaut de notre hôte Docker, le runtime pointe vers le répertoire / var / lib / docker. Pour déterminer à quelle partition il appartient, tapez la commande suivante :
dockerhost$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 10G 7.2G 2.9G 72% /
devtmpfs 7.3G 0 7.3G 0% /dev
tmpfs 7.3G 0 7.3G 0% /dev/shm
tmpfs 7.3G 8.6M 7.3G 1% /run
tmpfs 7.3G 0 7.3G 0% /sys/fs/cgroup
/dev/sdb 9.8G 159M 9.1G 2% /var/lib/docker/swarm
tmpfs 1.5G 0 1.5G 0% /run/user/0
tmpfs 1.5G 0 1.5G 0% /run/user/1000
Comme décrit dans la sortie précédente, le répertoire / var / lib / docker de notre hôte Docker se trouve sous la partition /. C’est là que nous pointerons blktrace pour écouter les événements. Tapez la commande suivante pour commencer à écouter les événements d’E / S sur ce périphérique :
dockerhost$ blktrace -d /dev/sda1 -o dump
En utilisant l’indicateur –privileged dans la commande docker run, nous pouvons utiliser blktrace dans un conteneur. Cela nous permettra de monter le système de fichiers débogué avec les privilèges accrus. Pour plus d’informations sur les privilèges étendus des conteneurs, rendez-vous sur https://docs.docker.com/engine/reference/run/#runtime-privilege-linux-capabilities-and-lxc-configuration.
Pour créer une charge de travail simple qui générera des événements d’E / S sur notre disque, nous allons créer un fichier vide à partir d’un conteneur jusqu’à ce que la partition / manque d’espace libre. Tapez la commande suivante pour générer cette charge de travail:
dockerhost$ docker run -d –name dump debian:stretch \
/bin/dd if=/dev/zero of=/root/dump bs=65000
Selon l’espace libre disponible dans notre partition racine, cette commande peut se terminer rapidement. Tout de suite, récupérons le PID du conteneur que nous venons d’exécuter en utilisant la commande suivante :
dockerhost$ docker inspect -f ‘{{.State.Pid}}’ dump
11099
Maintenant que nous savons que le PID de notre conteneur Docker qui a généré des événements d’E/S, nous pouvons regarder cela avec l’ blktrace outil complémentaire de programme, blkparse . Le programme blktrace écoute uniquement les événements dans la couche d’E / S de bloc du noyau Linux et sauvegarde les résultats dans un fichier. Le programme blkparse est l’outil d’accompagnement pour visualiser et analyser les événements. Dans la charge de travail que nous avons générée précédemment, nous pouvons rechercher les événements d’E / S qui correspondent au PID de notre conteneur Docker à l’aide de la commande suivante :
dockerhost$ blkparse -i dump.blktrace.0 | grep ” $PID “
…
254,0 0 730 10.6267 11099 Q R 13667072 + 24 [exe]
254,0 0 732 10.6293 11099 Q R 5042728 + 16 [exe]
254,0 0 734 10.6299 11099 Q R 13900768 + 152 [exe]
254,0 0 736 10.6313 11099 Q RM 4988776 + 8 [exe]
254,0 0 1090 10.671 11099 C W 11001856 + 1024 [0]
254,0 0 1091 10.6712 11099 C W 11002880 + 1024 [0]
254,0 0 1092 10.6712 11099 C W 11003904 + 1024 [0]
254,0 0 1093 10.6712 11099 C W 11004928 + 1024 [0]
254,0 0 1094 10.6713 11099 C W 11006976 + 1024 [0]
254,0 0 1095 10.6714 11099 C W 11005952 + 1024 [0]
254,0 0 1138 10.6930 11099 C W 11239424 + 1024 [0]
254,0 0 1139 10.6931 11099 C W 11240448 + 1024 [0]
…
Dans la sortie en surbrillance précédente, nous pouvons voir que le bloc / dev / sda1 a décalé la position de 11001856, et il y avait une écriture (W) de 1024 octets de données qui venait de se terminer (C). Pour aller plus loin, nous pouvons regarder cette position de décalage sur les événements qu’elle a générés. Tapez la commande suivante pour filtrer cette position de décalage :
dockerhost$ blkparse -i dump.blktrace.0 | grep 11001856
…
254,0 0 1066 10.667 8207 Q W 11001856 + 1024 [kworker/u2:2]
254,0 0 1090 10.671 11099 C W 11001856 + 1024 [0]
…
Nous pouvons voir l’écriture (W) mise en file d’attente (Q) sur notre appareil par le processus kworker, ce qui signifie que l’écriture a été mise en file d’attente par le noyau. Après 40 millisecondes, la demande d’écriture enregistrée a été effectuée pour notre processus de conteneur Docker.
La procédure de débogage que nous venons d’exécuter n’est qu’un petit échantillon de ce que nous pouvons faire en traçant les événements d’E / S de bloc avec blktrace. Par exemple, nous pouvons également analyser plus en détail le comportement d’E / S de notre conteneur Docker et déterminer les goulots d’étranglement qui se produisent dans notre application. Y a-t-il beaucoup d’écritures en cours ? Les lectures ont-elles tellement besoin de mise en cache ? Le fait d’avoir les événements réels plutôt que les seules mesures de performances fournies par la commande intégrée docker stats est utile dans les scénarios de dépannage très approfondis.
Plus d’informations sur les différentes valeurs de sortie de blkparse et des indicateurs pour capturer les événements d’E / S dans blktrace, avec une copie de son guide de l’utilisateur, sont disponibles sur http://man7.org/linux/man-pages/man8/blktrace.8 .html.
Autres outils de débogage de conteneur
Le débogage d’applications à l’intérieur de conteneurs Docker nécessite une approche différente des applications normales sous Linux. Cependant, les programmes réels utilisés sont les mêmes car tous les appels de l’intérieur du conteneur iront finalement au système d’exploitation du noyau de l’hôte Docker. En sachant comment les appels sortent de nos conteneurs, nous pouvons utiliser tout autre outil de débogage que nous devons dépanner.
En plus des outils Linux standard, il existe plusieurs utilitaires spécifiques aux conteneurs qui regroupent les utilitaires standard précédents pour être plus conviviaux pour l’utilisation des conteneurs. Voici quelques-uns de ces outils :
- L’image Docker de rhel-tools de Red Hat est un énorme conteneur contenant une combinaison des outils dont nous avons discuté précédemment. Sa page de documentation se trouve sur https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux_atomic_host/7/html/managing_containers/running_super _privileged_containers # using_the_atomic_tools_container_image montre comment l’exécuter correctement avec les privilèges Docker.
- Le programme CoreOS toolbox est un petit utilitaire de script qui crée un petit conteneur Linux à l’aide du programme systemd-nspawn du logiciel systemd. En copiant le système de fichiers racine à partir d’images Docker populaires, nous pouvons installer n’importe quel outil que nous voulons sans polluer le système de fichiers de l’hôte Docker avec des outils de débogage ad hoc. Son utilisation est documentée sur sa page Web à l’adresse https://coreos.com/os/docs/latest/install-debugging-tools.html.
Résumé
N’oubliez pas que la connexion aux hôtes Docker n’est pas évolutive. L’ajout d’instruments au niveau de l’application, en plus de ceux fournis par notre système d’exploitation, permet un diagnostic plus rapide et plus efficace des problèmes que nous pourrions rencontrer à l’avenir. N’oubliez pas que personne n’aime se réveiller à deux heures du matin pour exécuter tcpdump pour déboguer un conteneur Docker en feu !
Dans le chapitre suivant, nous terminerons et examinerons à nouveau ce qu’il faut pour mettre nos charges de travail basées sur Docker en production.
Sur la production
Docker est né du PaaS de dotCloud, où il répond aux besoins des TI pour développer et déployer des applications Web de manière rapide et évolutive. Cela est nécessaire pour suivre le rythme toujours plus rapide de l’utilisation du Web. Garder tout ce qui fonctionne dans notre conteneur Docker en production n’est pas une mince affaire.
Jusqu’à présent, nous avons appris divers détails pour améliorer notre infrastructure Docker. Nous avons appris à créer automatiquement des clusters Docker Swarm. Nous avons découvert divers systèmes tels que la surveillance, la journalisation et le déploiement pour prendre en charge notre application Docker. Nous avons amélioré notre flux de travail de développement et de déploiement afin que nos applications soient performantes et résistantes.
Dans ce chapitre, nous résumerons ce que vous avez appris sur l’optimisation de Docker et illustrerons comment il se rapporte au fonctionnement de nos applications Web en production. Il se compose des sujets suivants :
- Exécution d’opérations Web
- Soutenir notre application avec Docker
- Déployer des applications
- Applications de mise à l’échelle
- Lectures complémentaires sur les opérations Web en général
Exécution d’opérations Web
Garder une application Web fonctionnant 24h / 24 et 7j / 7 sur Internet pose des défis à la fois en matière de développement logiciel et d’administration de systèmes. Docker se positionne comme le ciment qui permet aux deux disciplines de se réunir en créant des images Docker qui peuvent être construites et déployées de manière cohérente.
Cependant, Docker n’est pas une solution miracle pour le Web. Il est toujours important de connaître les concepts fondamentaux du développement logiciel et de l’administration des systèmes à mesure que les applications Web deviennent plus complexes. La complexité se pose naturellement parce que de nos jours, avec les technologies Internet en particulier, la multitude d’applications Web devient de plus en plus omniprésente dans la vie des gens.
Faire face à la complexité de maintenir les applications Web opérationnelles implique de maîtriser les tenants et aboutissants des opérations Web, et comme toute voie vers la maîtrise, Theo Schlossnagle se résume à quatre objectifs fondamentaux : connaissances, outils, expérience et discipline. Les connaissances se réfèrent à l’absorption d’informations sur les opérations Web disponibles sur Internet et dans les conférences et les réunions technologiques comme une éponge. Les comprendre et savoir filtrer le signal du bruit nous aidera à concevoir l’architecture de notre application lorsqu’elle brûle en production. Avec la popularité croissante des conteneurs Docker et Linux, il est important de connaître les différentes technologies qui le prennent en charge et de plonger dans ses bases. Dans le chapitre 8, Dépannage des conteneurs, nous avons montré que les outils de débogage Linux habituels sont toujours utiles pour déboguer des conteneurs Docker en cours d’exécution. En sachant comment les conteneurs interagissent avec le système d’exploitation de notre hôte Docker, nous avons pu déboguer les problèmes survenant dans Docker.
Le deuxième aspect est la maîtrise de nos outils. Cet article a essentiellement tourné autour de la maîtrise de l’utilisation de Docker en examinant comment il fonctionne et comment optimiser son utilisation. Dans le chapitre 4, Optimisation des images Docker, nous avons appris à optimiser les images Docker en fonction de la façon dont Docker construit les images et exécute le conteneur à l’aide de son système de fichiers de copie sur écriture en dessous. Cela a été guidé par notre connaissance des opérations Web et pourquoi les images Docker optimisées sont importantes à la fois du point de vue de l’évolutivité et de la déployabilité. Savoir comment utiliser Docker efficacement ne se fait pas du jour au lendemain. Sa maîtrise ne peut être acquise que par une pratique continue d’utilisation de Docker en production. Bien sûr, nous pourrions être paginés à 2 heures du matin pour notre premier déploiement Docker en production, mais avec le temps, l’expérience que nous gagnons d’une utilisation continue fera de Docker une extension de nos membres et de nos sens, comme le dit Schlossnagle.
En appliquant les connaissances et en utilisant continuellement nos outils, nous acquérons une expérience sur laquelle nous pouvons nous appuyer à l’avenir. Cela nous aide à porter de bons jugements sur la base de mauvaises décisions que nous avons prises dans le passé. C’est l’endroit où nous pouvons voir la théorie de la technologie des conteneurs et la pratique de l’exécution de Docker en production entrer en collision. Schlossnagle a mentionné les défis de l’acquisition d’expérience dans les opérations Web et comment survivre aux mauvais jugements et en tirer des expériences. Il suggère d’avoir des environnements limités dans lesquels l’impact d’une mauvaise décision est minime. Docker est le meilleur endroit pour dessiner ces types d’expériences. Ayant un format standard d’images Docker prêtes à être déployées, les ingénieurs d’exploitation Web juniors peuvent avoir leurs propres environnements qu’ils peuvent expérimenter et dans lesquels ils peuvent apprendre de leurs erreurs. De plus, comme les environnements Docker se ressemblent beaucoup lorsqu’ils passent à la production, ces ingénieurs auront déjà leur expérience à exploiter.
La dernière partie dans la poursuite de la maîtrise des opérations Web est la discipline. Cependant, comme il s’agit d’une discipline très jeune, ces processus ne sont pas bien définis. Même avec Docker, il a fallu quelques années pour que les gens réalisent les meilleures façons d’utiliser les technologies de conteneurs. Avant cela, la commodité d’inclure tout l’évier de la cuisine dans les images Docker était très courante. Cependant, comme nous pouvons le voir au chapitre 4, Optimisation des images Docker , la réduction de l’encombrement des images Docker aide à gérer la complexité des applications que nous devons déboguer. Cela rend l’expérience de débogage du chapitre 8 , Dépannage des conteneurs , beaucoup plus simple car nous avons moins de composants et de facteurs à considérer. Ces disciplines d’utilisation de Docker ne viennent pas du jour au lendemain simplement en lisant des blogs Docker (enfin, certains le font). Il implique une exposition continue à la connaissance de la communauté Docker et à la pratique de l’utilisation de Docker dans divers contextes pour une utilisation en production.
Dans les sections restantes, nous montrerons comment la théorie et la pratique de l’utilisation de la technologie de conteneur de Docker peuvent aider au fonctionnement de nos applications Web.
Prise en charge des applications Web avec Docker
Le diagramme suivant montre l’architecture typique d’une application Web. Nous avons le niveau d’équilibrage de charge qui reçoit le trafic provenant d’Internet, puis le trafic, qui est généralement composé de demandes des utilisateurs, est relayé à une batterie de serveurs d’applications Web de manière équilibrée en charge.
Selon la nature de la demande, certains états seront récupérés par l’application Web à partir du niveau de stockage persistant, similaire aux serveurs de base de données :
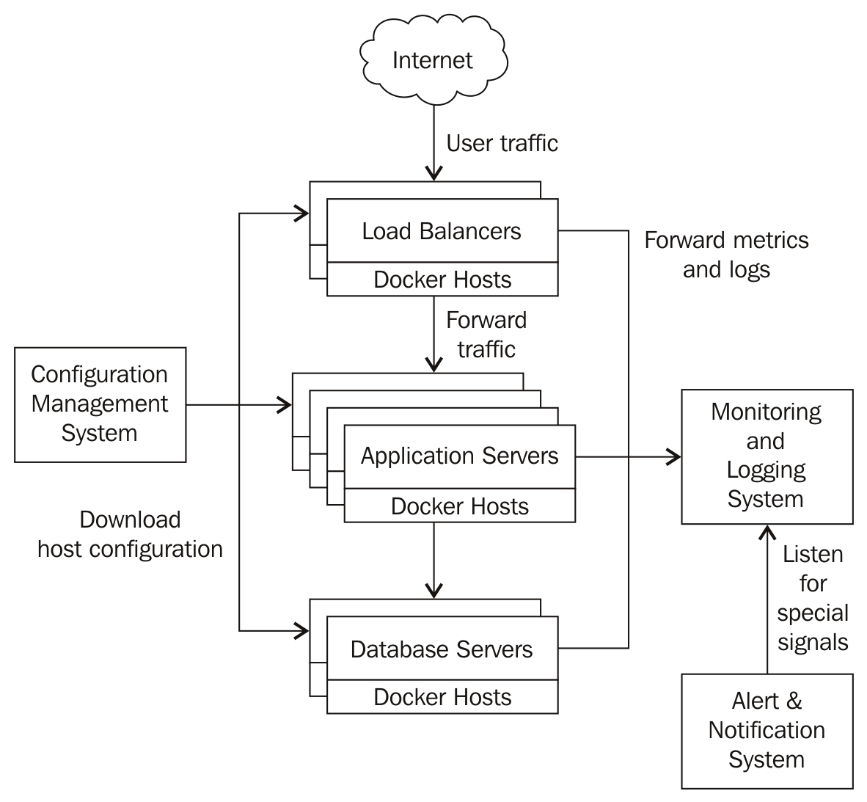
Comme nous pouvons le voir dans le diagramme précédent, chaque niveau est exécuté dans un conteneur Docker au-dessus des hôtes Docker. Avec cette disposition pour chaque composant, nous pouvons tirer parti de la manière uniforme de Docker de déployer des équilibreurs de charge, des applications et des bases de données, comme nous l’avons fait au chapitre 2, Configuration de Docker avec Chef, et au chapitre 7, Équilibrage de charge. Cependant, en plus des démons Docker dans chaque hôte Docker, nous avons besoin d’une infrastructure de prise en charge pour gérer et observer l’intégralité de la pile de notre architecture Web de manière évolutive. Sur le côté droit, nous pouvons voir que chacun de nos hôtes Docker envoie des informations de diagnostic – par exemple, des événements d’application et de système tels que des messages de journal et des mesures – à notre système centralisé de journalisation et de surveillance. Nous avons déployé un tel système dans le chapitre 3 , Monitoring Dockers , où nous avons déployé Grafana et une pile ELK. De plus, il peut y avoir un autre système qui écoute des signaux spécifiques dans les journaux et les mesures et envoie des alertes aux ingénieurs responsables du fonctionnement de notre pile d’applications Web Docker. Ces événements peuvent être liés à des événements critiques, tels que la disponibilité et les performances de notre application, que nous devons prendre pour garantir que notre application répond aux besoins de notre entreprise comme prévu. Un système géré en interne, tel que Nagios, ou un système tiers, tel que PagerDuty, est utilisé pour nos déploiements Docker pour nous appeler et nous réveiller à 2 heures du matin pour des sessions de surveillance et de dépannage plus approfondies comme au Chapitre 3, Surveillance de Docker, et Chapitre 8, Dépannage des conteneurs.
Le côté gauche du diagramme contient le système de gestion de la configuration. C’est l’endroit où chacun des hôtes Docker télécharge tous les paramètres dont il a besoin pour fonctionner correctement. Dans le chapitre 2, Configuration de Docker avec Chef, nous avons utilisé un serveur Chef pour stocker la configuration de notre hôte Docker. Il contenait des informations telles que le rôle d’un hôte Docker dans la pile de notre architecture. Le serveur Chef stocke des informations sur les conteneurs Docker à exécuter dans chaque niveau et comment les exécuter à l’aide des recettes Chef que nous avons écrites. Enfin, le système de gestion de la configuration indique également à nos hôtes Docker où se trouvent les points d’extrémité de surveillance et de journalisation Grafana et Logstash.
Dans l’ensemble, il faut divers composants pour prendre en charge notre application Web en production, à part Docker. Docker nous permet de configurer facilement cette infrastructure en raison de la rapidité et de la flexibilité du déploiement de conteneurs. Néanmoins, nous ne devons pas ignorer nos devoirs concernant la mise en place de ces infrastructures de soutien. Dans la section suivante, nous verrons l’infrastructure de prise en charge du déploiement d’applications Web dans Docker en utilisant les compétences que vous avez apprises dans les chapitres précédents.
Déploiement d’applications
Un élément important lors du réglage des performances des conteneurs Docker est le retour d’information nous indiquant que nous avons pu améliorer notre application Web correctement. Le déploiement de Graphite et de la pile ELK dans le chapitre 3, Monitoring Docker, nous a donné une visibilité sur les effets de ce que nous avons changé dans notre application Web Docker. Autant il est important de recueillir des commentaires, il est plus important de recueillir des commentaires en temps opportun. Par conséquent, le déploiement de nos conteneurs Docker doit être rapide et évolutif. La possibilité de configurer automatiquement un hôte Docker, comme nous l’avons fait au chapitre 2, Configuration de Docker avec Chef , est un composant important pour un système de déploiement rapide et automatisé. Les autres composants sont décrits dans le diagramme suivant :
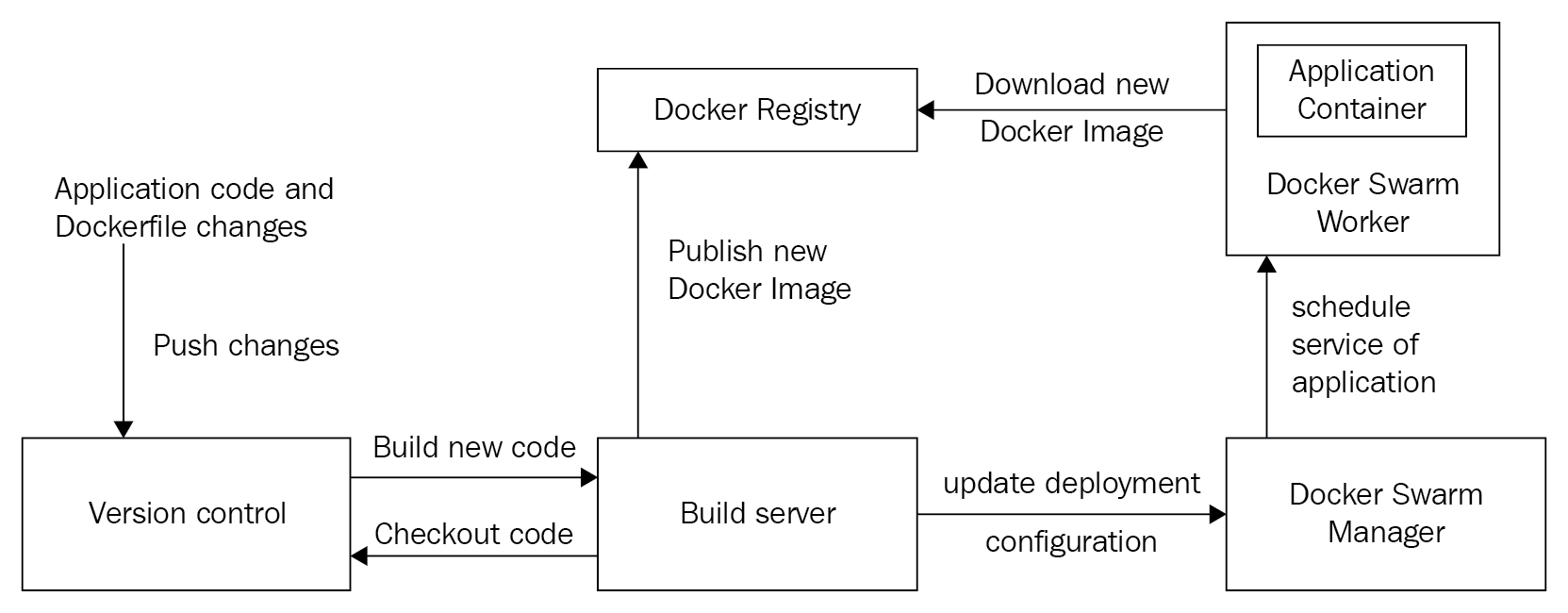
Chaque fois que nous soumettons des modifications au code de notre application ou au Dockerfile décrivant comment il est exécuté et construit, nous avons besoin d’une infrastructure de support pour propager ce changement jusqu’à nos hôtes Docker. Dans le diagramme précédent, nous pouvons voir que les modifications que nous soumettons à notre système de contrôle de version, comme Git, génèrent un déclencheur pour construire la nouvelle version de notre code. Cela se fait généralement via les hooks post-réception de Git sous forme de scripts shell. Les déclencheurs seront reçus par un serveur de génération, tel que le serveur Jenkins que nous avons configuré au chapitre 5, Déploiement de conteneurs. Les étapes pour propager la modification seront similaires au processus de déploiement bleu-vert que nous avons effectué au chapitre 7, Équilibrage de charge. Après avoir reçu le déclencheur pour générer les nouvelles modifications que nous avons soumises, Jenkins examinera la nouvelle version de notre code et exécutera la génération Docker pour créer l’image Docker. Après la génération, Jenkins poussera la nouvelle image Docker vers un registre Docker, tel que Docker Hub. Avec les nouveaux artefacts d’image Docker disponibles dans le Docker Registry, notre processus de déploiement peut désormais mettre à jour la définition d’application de notre service pour utiliser les nouvelles versions de notre image Docker via une commande telle que Docker stack deploy.
Dans la section suivante, nous verrons comment un processus similaire est utilisé pour faire évoluer notre application Docker.
Mise à l’échelle des applications
Lorsque nous recevons des alertes de notre système de surveillance, comme dans le chapitre 3 , Surveillance de Docker , que le pool de conteneurs Docker exécutant notre application Web n’est pas chargé, il est temps d’évoluer. Nous avons accompli cela en utilisant des équilibreurs de charge au chapitre 7, Équilibrage de charge. Le diagramme suivant montre l’architecture de haut niveau des commandes que nous avons exécutées au chapitre 7, Équilibrage de charge :
Lorsque nous décidons de mettre à l’échelle et d’ajouter un hôte Docker supplémentaire, nous pouvons automatiser le processus avec un composant d’orchestrateur Scale out. Il peut s’agir d’une série de scripts shell simples que nous installerons dans un serveur de build, tel que Jenkins. L’orchestrateur demandera essentiellement à l’API du fournisseur de cloud de créer un nouvel hôte Docker. Cette demande provisionnera alors l’hôte Docker et exécutera le script d’amorçage initial pour télécharger la configuration à partir de notre système de gestion de configuration dans le chapitre 2, Configuration de Docker avec Chef. Cela augmentera ensuite le nombre de nœuds dans notre cluster Docker Swarm. Une fois l’ensemble de ce processus de provisioning terminé, notre orchestrateur évolutif augmentera alors le nombre de répliques des services de nos applications. Notre équilibreur de charge NGINX commencera à transférer le trafic vers ces répliques supplémentaires.
Comme nous pouvons le voir dans ce qui précède, apprendre à automatiser la configuration de notre hôte Docker au chapitre 2, Configuration de Docker avec Chef, est crucial pour réaliser la configuration de l’architecture d’équilibrage de charge évolutive que nous avons créée au chapitre 7, Équilibrage de charge.
Résumé
Vous avez beaucoup appris sur le fonctionnement de Docker tout au long de cet article. En plus des bases de Docker, nous avons regardé en arrière certains concepts fondamentaux des opérations Web et comment ils nous aident à réaliser le plein potentiel de Docker. Vous avez acquis des connaissances sur les principaux concepts de Docker et de systèmes d’exploitation pour mieux comprendre ce qui se passe dans les coulisses. Vous avez maintenant une idée de la façon dont notre application passe de notre code à l’appel réel dans le système d’exploitation de notre hôte Docker. Vous avez beaucoup appris sur les outils pour déployer et dépanner nos conteneurs Docker en production de manière évolutive et gérable.
Cependant, cela ne devrait pas vous empêcher de continuer à développer et à utiliser Docker pour exécuter des applications Web en production. Nous ne devons pas avoir peur de faire des erreurs et d’acquérir une expérience supplémentaire sur les meilleures façons d’exécuter Docker en production. À mesure que la communauté Docker évolue, ces pratiques évoluent à travers l’expérience collective de la communauté. Donc, nous devons continuer et être disciplinés pour apprendre les bases que nous avons commencé à maîtriser petit à petit. N’hésitez pas à lancer Docker en production !


Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.